Mundo Booleano

El comando top permite a los usuarios monitorizar los procesos y el uso de recursos del sistema en Linux. Es una de las herramientas más útiles en la caja de herramientas de un sysadmin, y viene preinstalado en cada distribución. A diferencia de otros comandos como ps, es interactivo, y se puede navegar por la lista de procesos, matar un proceso, etc.
En este artículo, vamos a entender cómo utilizar el comando top.
Comenzando
Como ya habrás adivinado, simplemente tienes que escribir esto para lanzar top:
top
Esto inicia una aplicación interactiva de línea de comandos, similar a una de las capturas de pantalla de abajo. La mitad superior de la salida contiene estadísticas sobre los procesos y el uso de recursos, mientras que la mitad inferior contiene una lista de los procesos actualmente en ejecución. Puede utilizar las teclas de flecha y las teclas de avance/retroceso de página para navegar por la lista. Si quieres salir, simplemente presiona «q».
Hay un número de variantes de top, pero en el resto de este artículo, hablaremos de la variante más común – la que viene con el paquete «procps-ng». Puedes verificar esto ejecutando:
top -v
Si tienes esta variante, esto aparecerá en la salida, así:
procps-ng version 3.3.10
Hay bastante en la interfaz de top, así que lo desglosaremos poco a poco en la siguiente sección.
Entendiendo la interfaz de top: el área de resumen
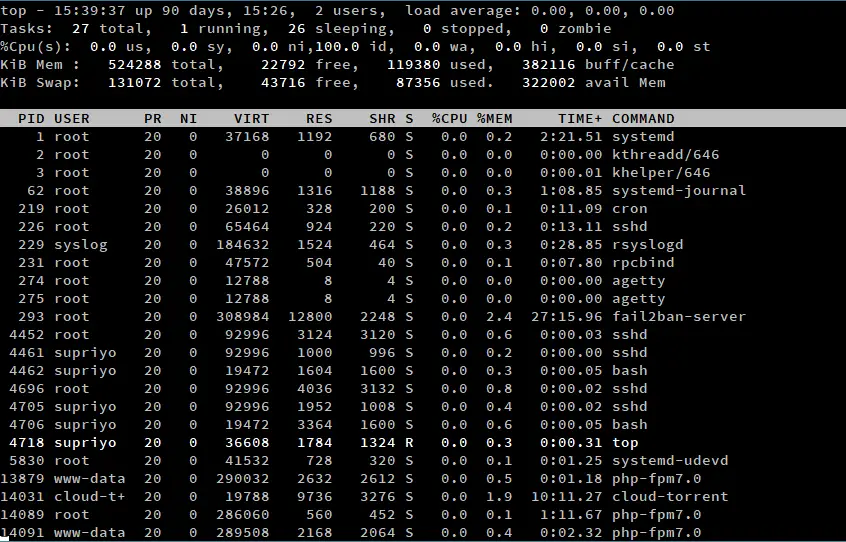
Como hemos visto anteriormente, la salida de top está dividida en dos secciones diferentes. En esta parte del artículo, nos vamos a centrar en los elementos de la mitad de la salida. Esta región también se llama «área de resumen».
Hora del sistema, tiempo de actividad y sesiones de usuario

En la parte superior izquierda de la pantalla (como se marca en la captura de pantalla anterior), top muestra la hora actual. A continuación aparece el tiempo de actividad del sistema, que nos indica el tiempo que lleva funcionando el sistema. Por ejemplo, en nuestro ejemplo, la hora actual es «15:39:37», y el sistema ha estado funcionando durante 90 días, 15 horas y 26 minutos.
A continuación viene el número de sesiones de usuario activas. En este ejemplo, hay dos sesiones de usuario activas. Estas sesiones pueden realizarse en un TTY (físicamente en el sistema, ya sea a través de la línea de comandos o de un entorno de escritorio) o en un PTY (como una ventana de emulador de terminal o a través de SSH). De hecho, si se accede a un sistema Linux a través de un entorno de escritorio, y luego se inicia un emulador de terminal, se encontrará que habrá dos sesiones activas.
Si quiere obtener más detalles sobre las sesiones de usuario activas, utilice el comando who.
Uso de la memoria

La sección «memory» muestra información relativa al uso de la memoria del sistema. Las líneas marcadas como «Mem» y «Swap» muestran información sobre la RAM y el espacio de intercambio respectivamente. En pocas palabras, un espacio de intercambio es una parte del disco duro que se utiliza como la RAM. Cuando el uso de la RAM está casi lleno, las regiones de la RAM utilizadas con poca frecuencia se escriben en el espacio de intercambio, listas para ser recuperadas más tarde cuando se necesiten. Sin embargo, debido a que el acceso a los discos es lento, confiar demasiado en el intercambio puede perjudicar el rendimiento del sistema.
Como es natural, los valores «total», «libre» y «usado» tienen sus significados habituales. El valor «avail mem» es la cantidad de memoria que se puede asignar a los procesos sin causar más swapping.
El núcleo de Linux también intenta reducir los tiempos de acceso al disco de varias maneras. Mantiene una «caché de disco» en la RAM, donde se almacenan las regiones del disco que se utilizan con frecuencia. Además, las escrituras en el disco se almacenan en un «buffer de disco», y el núcleo finalmente las escribe en el disco. La memoria total consumida por ellos es el valor «buff/cache». Puede sonar como algo malo, pero realmente no lo es – la memoria utilizada por la caché se asignará a los procesos si es necesario.
Tareas

La sección «Tareas» muestra las estadísticas relativas a los procesos que se ejecutan en su sistema. El valor «total» es simplemente el número total de procesos. Por ejemplo, en la captura de pantalla anterior, hay 27 procesos en ejecución. Para entender el resto de los valores, necesitamos un poco de información sobre cómo el kernel de Linux maneja los procesos.
Los procesos realizan una mezcla de trabajo ligado a la E/S (como la lectura de discos) y trabajo ligado a la CPU (como la realización de operaciones aritméticas). La CPU está inactiva cuando un proceso realiza E/S, por lo que los SO pasan a ejecutar otros procesos durante este tiempo. Además, el SO permite que un proceso determinado se ejecute durante un tiempo muy pequeño, y luego cambia a otro proceso. Así es como los SO aparecen como si fueran «multitarea». Hacer todo esto requiere que llevemos la cuenta del «estado» de un proceso. En Linux, un proceso puede estar en uno de estos estados:
- Runable (R): Un proceso en este estado se está ejecutando en la CPU, o está presente en la cola de ejecución, listo para ser ejecutado.
- Sueño interrumpible (S): Los procesos en este estado están esperando que se complete un evento.
- Sueño ininterrumpible (D): En este caso, un proceso está esperando a que se complete una operación de E/S.
- Detenidos (T): Estos procesos han sido detenidos por una señal de control de trabajo (como al pulsar Ctrl+Z) o porque están siendo rastreados.
- Zombie (Z): El kernel mantiene varias estructuras de datos en la memoria para hacer un seguimiento de los procesos. Un proceso puede crear un número de procesos hijos, y éstos pueden salir mientras el padre sigue en pie. Sin embargo, estas estructuras de datos deben mantenerse hasta que el padre obtenga el estado de los procesos hijos. Tales procesos terminados cuyas estructuras de datos todavía están alrededor se llaman zombis.
- PID
- USUARIO
- PR y NI
- VIRT, RES, SHR y %MEM
- S
- TIME+
- COMANDO
- ‘M’ para ordenar por uso de memoria
- ‘P’ para ordenar por uso de CPU
- ‘N’ para ordenar por ID de proceso
- ‘T’ para ordenar por el tiempo de ejecución
Los procesos en los estados D y S se muestran en «sleeping», y los que están en el estado T se muestran en «stopped». El número de zombis se muestra como el valor «zombie».
Uso de la CPU

La sección de uso de la CPU muestra el porcentaje de tiempo de la CPU dedicado a varias tareas. El valor de us es el tiempo que la CPU pasa ejecutando procesos en el espacio de usuario. Del mismo modo, el valor sy es el tiempo que se dedica a ejecutar procesos en el espacio del núcleo.
Linux utiliza un valor «nice» para determinar la prioridad de un proceso. Un proceso con un valor «nice» alto es más «amable» con otros procesos, y obtiene una prioridad baja. Del mismo modo, los procesos con un valor «nice» más bajo obtienen una prioridad más alta. Como veremos más adelante, el valor «nice» por defecto puede cambiarse. El tiempo dedicado a la ejecución de procesos con un «nice» establecido manualmente aparece como el valor ni.
A este le sigue el id, que es el tiempo que la CPU permanece inactiva. La mayoría de los sistemas operativos ponen la CPU en modo de ahorro de energía cuando está inactiva. A continuación viene el valor wa, que es el tiempo que la CPU pasa esperando a que se complete la E/S.
Las interrupciones son señales al procesador sobre un evento que requiere atención inmediata. Las interrupciones de hardware suelen ser utilizadas por los periféricos para informar al sistema sobre eventos, como la pulsación de una tecla en un teclado. Por otro lado, las interrupciones de software se generan debido a instrucciones específicas ejecutadas en el procesador. En cualquiera de los dos casos, el SO se encarga de gestionarlas, y el tiempo que se dedica a manejar las interrupciones de hardware y software viene dado por hi y si respectivamente.
En un entorno virtualizado, una parte de los recursos de la CPU se ceden a cada máquina virtual (VM). El SO detecta cuando tiene trabajo que hacer, pero no puede realizarlo porque la CPU está ocupada en alguna otra VM. La cantidad de tiempo que se pierde de esta manera es el tiempo de «robo», que se muestra como st.
Promedio de carga

La sección de promedio de carga representa el promedio de «carga» durante uno, cinco y quince minutos. «Carga» es una medida de la cantidad de trabajo computacional que realiza un sistema. En Linux, la carga es el número de procesos en los estados R y D en un momento dado. El valor de «carga media» le da una medida relativa de cuánto tiempo debe esperar para que las cosas se hagan.
Consideremos algunos ejemplos para entender este concepto. En un sistema de un solo núcleo, un promedio de carga de 0,4 significa que el sistema está haciendo sólo el 40% del trabajo que puede hacer. Un promedio de carga de 1 significa que el sistema está exactamente a su capacidad – el sistema se sobrecargará al añadir incluso un poco de trabajo adicional. Un sistema con una media de carga de 2,12 significa que está sobrecargado con un 112% más de trabajo del que puede realizar.
En un sistema multinúcleo, primero debe dividir la media de carga con el número de núcleos de la CPU para obtener una medida similar.
Además, la «media de carga» no es en realidad la típica «media» que la mayoría conocemos. Es una «media móvil exponencial», lo que significa que una pequeña parte de las medias de carga anteriores se tienen en cuenta en el valor actual. Si estás interesado, este artículo cubre todos los detalles técnicos.
Entendiendo la interfaz de top: el área de tareas
El área de resumen es comparativamente más simple, y contiene una lista de procesos. En esta sección, aprenderemos sobre las diferentes columnas que se muestran en la salida por defecto de top.
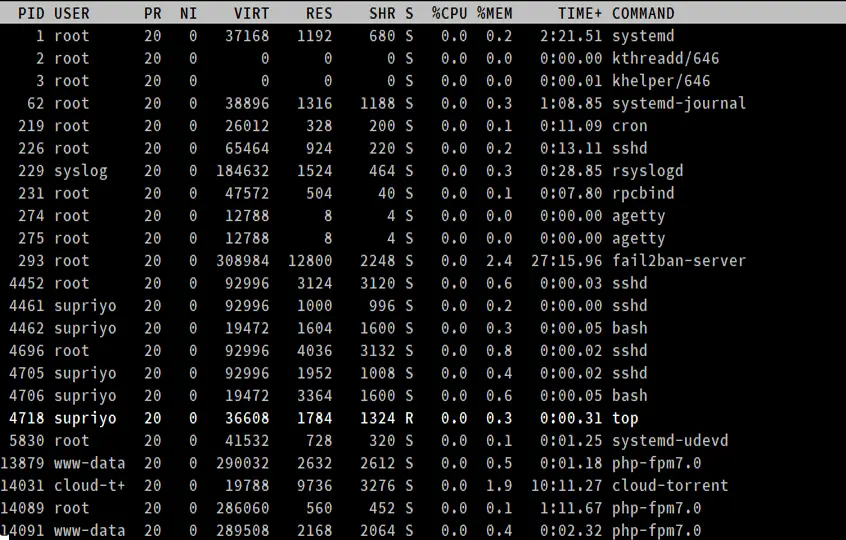
Este es el ID del proceso, un número entero positivo único que identifica a un proceso.
Este es el nombre de usuario «efectivo» (que se corresponde con un ID de usuario) del usuario que inició el proceso. Linux asigna un ID de usuario real y un ID de usuario efectivo a los procesos; este último permite que un proceso actúe en nombre de otro usuario. (Por ejemplo, un usuario no root puede elevarse a root para instalar un paquete.)
El campo «NI» muestra el valor «nice» de un proceso. El campo «PR» muestra la prioridad de programación del proceso desde la perspectiva del kernel. El valor nice afecta a la prioridad de un proceso.
Estos tres campos están relacionados con el consumo de memoria de los procesos. «VIRT» es la cantidad total de memoria consumida por un proceso. Esto incluye el código del programa, los datos almacenados por el proceso en memoria, así como cualquier región de memoria que haya sido intercambiada al disco. «RES» es la memoria consumida por el proceso en la RAM, y «%MEM» expresa este valor como un porcentaje del total de la RAM disponible. Por último, «SHR» es la cantidad de memoria compartida con otros procesos.
Como hemos visto anteriormente, un proceso puede estar en varios estados. Este campo muestra el estado del proceso en la forma de una sola letra.
Es el tiempo total de CPU utilizado por el proceso desde que se inició, con precisión de centésimas de segundo.
La columna COMANDO muestra el nombre de los procesos.
Ejemplos de uso de comandos de top
Hasta ahora, hemos hablado de la interfaz de top. Sin embargo, también puede gestionar procesos, y puedes controlar varios aspectos de la salida de top. En esta sección, vamos a ver unos cuantos ejemplos.
En la mayoría de los ejemplos que aparecen a continuación, hay que pulsar una tecla mientras top se está ejecutando. Tenga en cuenta que estas pulsaciones de teclas son sensibles a las mayúsculas y minúsculas – así que si presiona «k» mientras Caps Lock está activado, en realidad ha presionado una «K», y el comando no funcionará, o hará algo completamente diferente.
Matar procesos
Si quiere matar un proceso, simplemente presione ‘k’ cuando top esté ejecutando. Esto hará que aparezca un prompt, que le pedirá el ID del proceso y pulse enter.
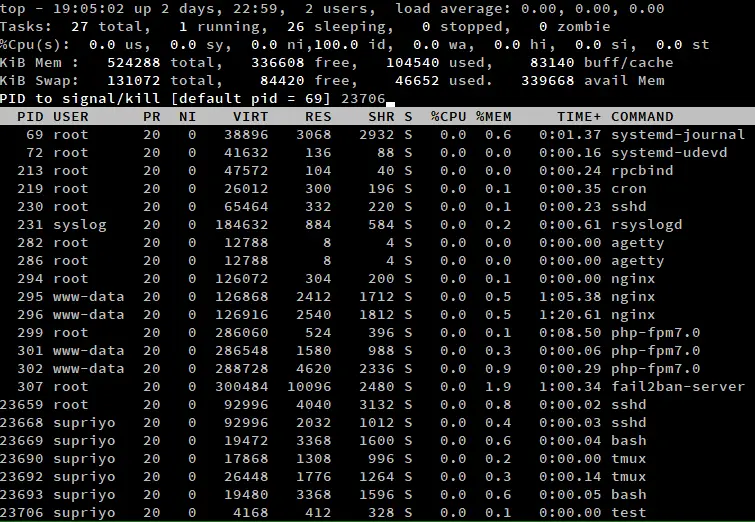
A continuación, introduzca la señal con la que se debe matar el proceso. Si deja esto en blanco, top utiliza un SIGTERM, que permite que los procesos terminen con gracia. Si quiere matar un proceso a la fuerza, puede escribir SIGKILL aquí. También puede escribir el número de la señal aquí. Por ejemplo, el número de SIGTERM es 15 y el de SIGKILL es 9.
Si dejas el ID del proceso en blanco y pulsas enter directamente, terminará el proceso más alto de la lista. Como hemos comentado anteriormente, puedes desplazarte con las teclas de dirección, y cambiar el proceso que quieres matar de esta forma.
Ordenación de la lista de procesos
Una de las razones más frecuentes para utilizar una herramienta como top es averiguar qué proceso está consumiendo más recursos. Puedes pulsar las siguientes teclas para ordenar la lista:
Por defecto, top muestra todos los resultados en orden descendente. Sin embargo, puedes cambiar al orden ascendente pulsando R.También puedes ordenar la lista con el interruptor -o. Por ejemplo, si quieres ordenar los procesos por el uso de la CPU, puedes hacerlo con:
top -o %CPU
Puedes ordenar la lista por cualquiera de los atributos del área de resumen de la misma manera.
Mostrar una lista de hilos en lugar de procesos
Hemos tocado anteriormente cómo Linux cambia entre procesos. Desafortunadamente, los procesos no comparten memoria ni otros recursos, lo que hace que estos cambios sean bastante lentos. Linux, como muchos otros sistemas operativos, soporta una alternativa «ligera», llamada «hilo». Forman parte de un proceso y comparten ciertas regiones de memoria y otros recursos, pero pueden ejecutarse concurrentemente como los procesos.
Por defecto, top muestra una lista de procesos en su salida. Si quiere listar los hilos en su lugar, pulse ‘H’ cuando top se esté ejecutando. Observe que la línea de «Tareas» dice «Hilos» en su lugar, y muestra el número de hilos en lugar de procesos.
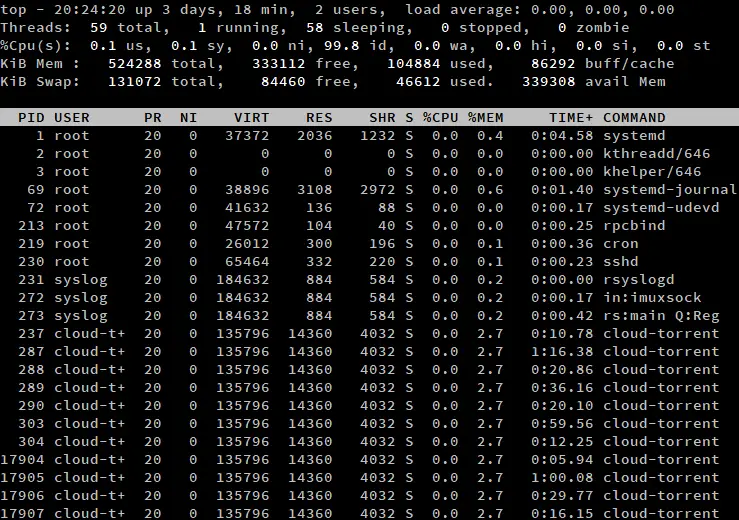
Puede haber notado cómo ninguno de los atributos de la lista de procesos cambió. Cómo es eso posible, dado que los procesos difieren de los hilos? Dentro del núcleo de Linux, los hilos y los procesos se manejan usando las mismas estructuras de datos. Así, cada hilo tiene su propio ID, estado y demás.
Si quieres volver a la vista de procesos, pulsa de nuevo H. Además, puede utilizar el interruptor -H para mostrar los hilos por defecto.
top -H
Mostrar rutas completas
Por defecto, top no muestra la ruta completa del programa, ni distingue entre los procesos del espacio del núcleo y los del espacio del usuario. Si necesita esta información, presione ‘c’ mientras se ejecuta top. Presione ‘c’ de nuevo para volver al valor predeterminado.
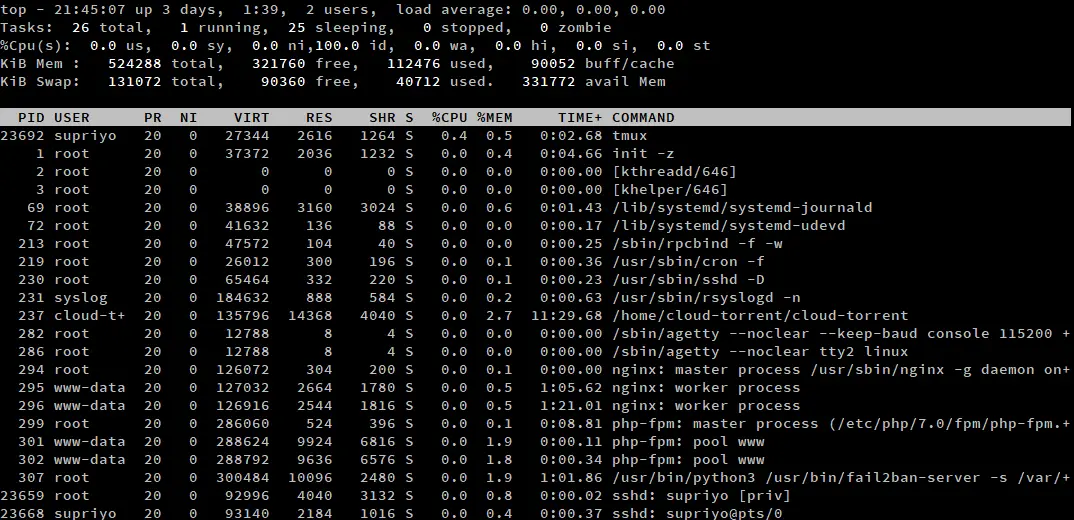
Los procesos del espacio del núcleo están marcados con corchetes alrededor de ellos. Como ejemplo, en la captura de pantalla anterior hay dos procesos del núcleo, kthreadd y khelper. En la mayoría de las instalaciones de Linux, normalmente habrá unos cuantos más.
Alternativamente, también puede iniciar el top con el argumento -c:
top -c
Vista de bosque
A veces, puede querer ver la jerarquía hijo-padre de los procesos. Puedes ver esto con la vista de bosque, pulsando ‘/’V’ mientras se ejecuta top.
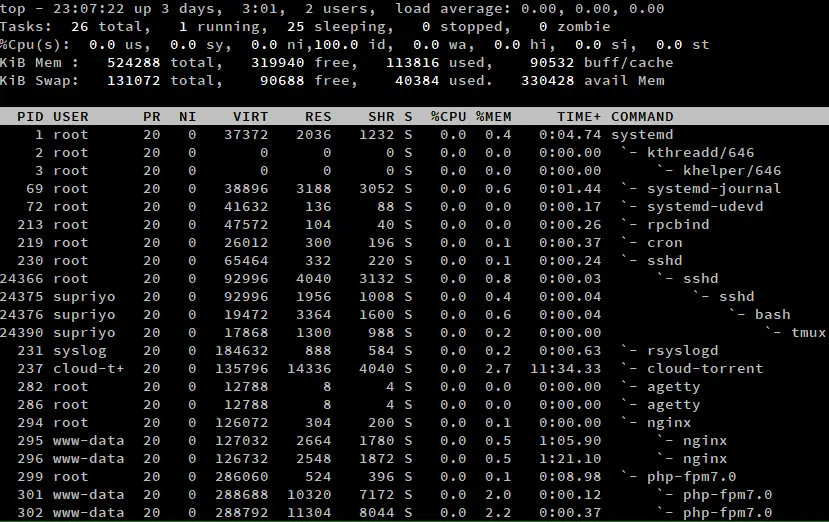
Como puedes ver en la captura de pantalla de arriba, el proceso systemd fue el primero en arrancar en el sistema. Ha iniciado procesos como sshd, que a su vez ha creado otros procesos sshd, y así sucesivamente.
Listado de procesos de un usuario
Para listar los procesos de un determinado usuario, pulsa ‘u’ cuando top esté ejecutándose. Luego, escriba el nombre de usuario, o déjelo en blanco para mostrar los procesos de todos los usuarios.
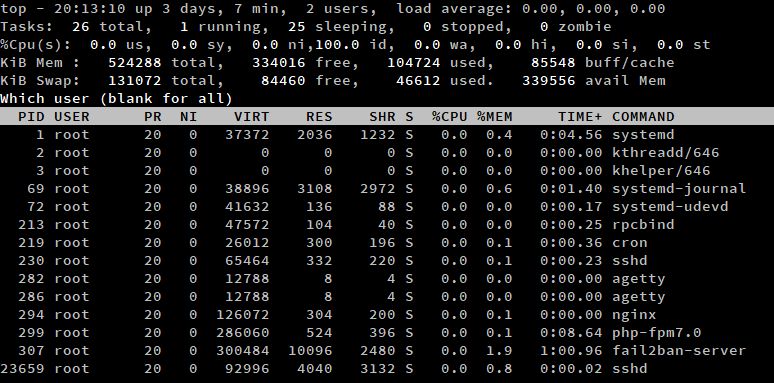
Alternativamente, puede ejecutar el comando top con el interruptor -u. En este ejemplo, hemos listado todos los procesos del usuario root.
top -u root
Filtrar por procesos
Si tienes muchos procesos con los que trabajar, una simple ordenación no funcionará lo suficientemente bien. En tal situación, puedes utilizar el filtrado de top para centrarte en unos pocos procesos. Para activar este modo, pulse ‘o’/’O’. Aparece un prompt dentro de top, y puedes escribir una expresión de filtro aquí.
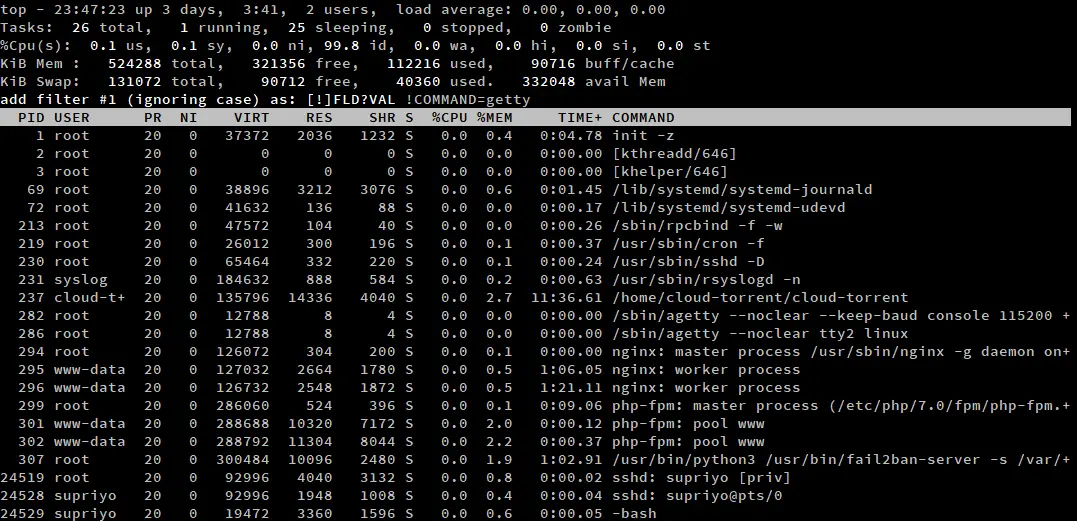
Una expresión de filtro es una declaración que especifica una relación entre un atributo y un valor. Algunos ejemplos de filtros son:
-
COMMAND=getty: Filtra los procesos que contienen «getty» en el atributo COMMAND. -
!COMMAND=getty: Filtra los procesos que no tienen «getty» en el atributo COMMAND. -
%CPU>3.0: Filtrar los procesos que tienen una utilización de la CPU de más del 3%. -
.
Una vez que haya añadido un filtro, puede podar aún más las cosas añadiendo más filtros. Para borrar cualquier filtro que haya añadido, presione ‘=’.
Cambiar el aspecto por defecto de las estadísticas de la CPU y la memoria
Si se encuentra principalmente en un entorno de interfaz gráfica de usuario, puede que no le guste la forma por defecto de top de mostrar las estadísticas de la CPU y la memoria. Puede presionar ‘t’ y ‘m’ para cambiar el estilo de las estadísticas del CPU y la memoria. Aquí hay una captura de pantalla de top, en la que hemos pulsado ‘t’ y ‘m’ una vez.
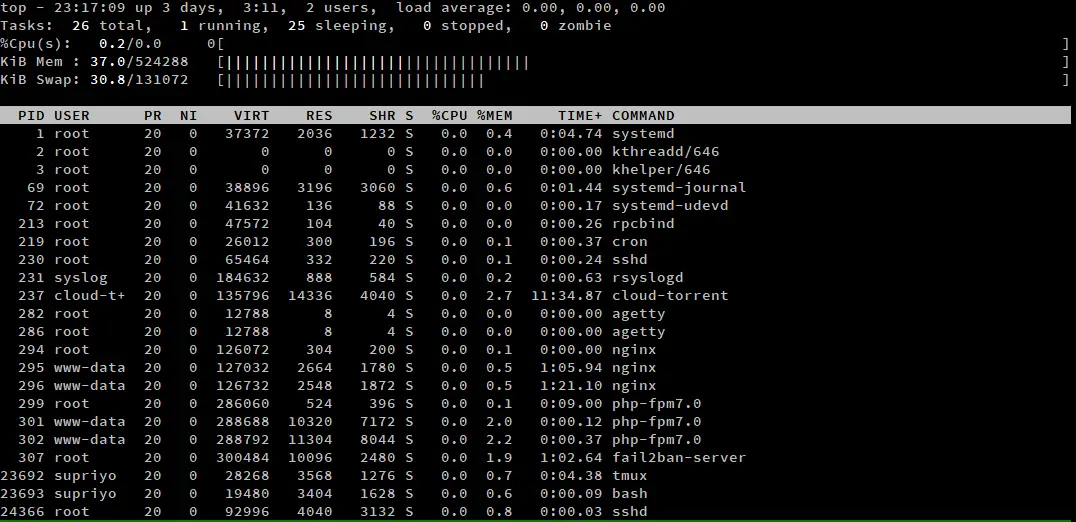
Si pulsas ‘t’ o ‘m’ repetidamente, pasa por cuatro vistas diferentes. En las dos primeras pulsaciones, hace un ciclo a través de dos tipos diferentes de barras de progreso. Si pulsas la tecla por tercera vez, la barra de progreso se oculta. Si vuelve a pulsar la tecla, vuelve a aparecer el contador por defecto, basado en texto.
Guardar la configuración
Si ha realizado algún cambio en la salida de top, puede guardarlo para utilizarlo más tarde pulsando .toprc en su directorio home.
Conclusión
El comando top es extremadamente útil para monitorear y administrar procesos en un sistema Linux. Este artículo sólo araña la superficie, y hay bastantes cosas que no hemos cubierto. Por ejemplo, hay muchas más columnas que puede agregar a top. Para todas estas cosas, asegúrate de revisar la página man ejecutando man top en tu sistema.
Si te ha gustado este post, por favor compártelo 🙂