Boolean World

Il comando top permette agli utenti di monitorare i processi e l’utilizzo delle risorse di sistema su Linux. È uno degli strumenti più utili nella cassetta degli attrezzi di un amministratore di sistema, ed è preinstallato su ogni distribuzione. A differenza di altri comandi come ps, è interattivo, e si può scorrere l’elenco dei processi, uccidere un processo, e così via.
In questo articolo, capiremo come utilizzare il comando top.
Iniziare
Come avrete già capito, dovete semplicemente digitare questo per lanciare top:
top
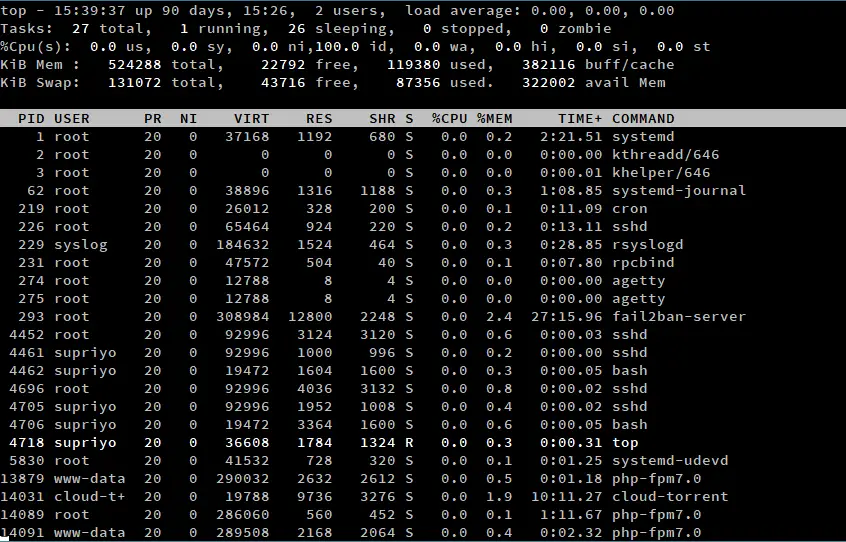
Questo avvia un’applicazione interattiva a riga di comando, simile a quella nello screenshot qui sotto. La metà superiore dell’output contiene statistiche sui processi e sull’utilizzo delle risorse, mentre la metà inferiore contiene un elenco dei processi attualmente in esecuzione. Puoi usare i tasti freccia e i tasti Page Up/Down per scorrere l’elenco. Se volete uscire, premete semplicemente “q”.
Ci sono diverse varianti di top, ma nel resto di questo articolo, parleremo della variante più comune – quella fornita con il pacchetto “procps-ng”. Potete verificarlo eseguendo:
top -v
Se avete questa variante, questo apparirà nell’output, così:
procps-ng version 3.3.10
Ci sono un bel po’ di cose da fare nell’interfaccia di top, quindi le analizzeremo pezzo per pezzo nella prossima sezione.
Comprendere l’interfaccia di top: l’area di riepilogo
Come abbiamo visto in precedenza, l’output di top è diviso in due diverse sezioni. In questa parte dell’articolo, ci concentreremo sugli elementi nella metà dell’output. Questa regione è anche chiamata “area di riepilogo”.
Ora del sistema, tempo di attività e sessioni utente

In alto a sinistra dello schermo (come indicato nello screenshot sopra), top mostra l’ora corrente. Questo è seguito dall’uptime del sistema, che ci dice il tempo per il quale il sistema è stato in funzione. Per esempio, nel nostro esempio, l’ora corrente è “15:39:37”, e il sistema è stato in funzione per 90 giorni, 15 ore e 26 minuti.
Poi viene il numero di sessioni utente attive. In questo esempio, ci sono due sessioni utente attive. Queste sessioni possono essere fatte sia su una TTY (fisicamente sul sistema, sia attraverso la linea di comando o un ambiente desktop) o una PTY (come una finestra di emulatore di terminale o su SSH). Infatti, se si accede ad un sistema Linux attraverso un ambiente desktop, e poi si avvia un emulatore di terminale, ci saranno due sessioni attive.
Se si desidera ottenere maggiori dettagli sulle sessioni utente attive, utilizzare il comando who.
Uso della memoria

La sezione “memoria” mostra informazioni riguardanti l’uso della memoria del sistema. Le linee marcate “Mem” e “Swap” mostrano informazioni rispettivamente sulla RAM e sullo spazio di swap. In parole povere, uno spazio di swap è una parte del disco rigido che viene utilizzato come la RAM. Quando l’uso della RAM diventa quasi pieno, le regioni usate di rado della RAM vengono scritte nello spazio di swap, pronte per essere recuperate più tardi quando necessario. Tuttavia, poiché l’accesso ai dischi è lento, fare troppo affidamento sullo swapping può danneggiare le prestazioni del sistema.
Come ci si aspetterebbe naturalmente, i valori “totale”, “libero” e “usato” hanno il loro solito significato. Il valore “avail mem” è la quantità di memoria che può essere allocata ai processi senza causare ulteriore swapping.
Il kernel Linux cerca anche di ridurre i tempi di accesso al disco in vari modi. Mantiene una “cache del disco” nella RAM, dove sono memorizzate le regioni del disco usate frequentemente. Inoltre, le scritture su disco sono memorizzate in un “disk buffer”, e il kernel alla fine le scrive sul disco. La memoria totale consumata da questi è il valore “buff/cache”. Potrebbe sembrare una cosa negativa, ma in realtà non lo è – la memoria usata dalla cache sarà assegnata ai processi se necessario.
Tasks

La sezione “Tasks” mostra le statistiche riguardanti i processi in esecuzione sul sistema. Il valore “totale” è semplicemente il numero totale di processi. Per esempio, nello screenshot qui sopra, ci sono 27 processi in esecuzione. Per capire il resto dei valori, abbiamo bisogno di un po’ di background su come il kernel Linux gestisce i processi.
I processi eseguono un mix di lavoro legato all’I/O (come leggere i dischi) e alla CPU (come eseguire operazioni aritmetiche). La CPU è inattiva quando un processo esegue l’I/O, così i sistemi operativi passano all’esecuzione di altri processi durante questo tempo. Inoltre, il sistema operativo permette l’esecuzione di un dato processo per una quantità molto piccola di tempo, e poi passa ad un altro processo. Questo è il modo in cui i sistemi operativi appaiono come se fossero “multitasking”. Fare tutto questo richiede di tenere traccia dello “stato” di un processo. In Linux, un processo può essere in uno di questi stati:
- Runable (R): Un processo in questo stato è in esecuzione sulla CPU, o è presente nella coda di esecuzione, pronto per essere eseguito.
- Interruptible sleep (S): I processi in questo stato sono in attesa del completamento di un evento.
- Sleep ininterrotto (D): In questo caso, un processo è in attesa del completamento di un’operazione di I/O.
- Stopped (T): Questi processi sono stati fermati da un segnale di controllo del lavoro (come premendo Ctrl+Z) o perché sono stati tracciati.
- Zombie (Z): Il kernel mantiene varie strutture di dati in memoria per tenere traccia dei processi. Un processo può creare un certo numero di processi figli, e questi possono uscire mentre il genitore è ancora in giro. Tuttavia, queste strutture dati devono essere mantenute in giro fino a quando il genitore non ottiene lo stato dei processi figli. Tali processi terminati le cui strutture dati sono ancora in giro sono chiamati zombie.
I processi negli stati D e S sono mostrati in “sleeping”, e quelli nello stato T sono mostrati in “stopped”. Il numero di zombie è mostrato come valore di “zombie”.
Uso della CPU

La sezione dell’uso della CPU mostra la percentuale di tempo della CPU speso in vari compiti. Il valore us è il tempo che la CPU spende nell’esecuzione dei processi nello spazio utente. Allo stesso modo, il valore sy è il tempo speso nell’esecuzione di processi in kernelspace.
Linux usa un valore “nice” per determinare la priorità di un processo. Un processo con un alto valore di “nice” è più “gentile” con gli altri processi, e ottiene una priorità bassa. Allo stesso modo, i processi con un “nice” più basso ottengono una priorità più alta. Come vedremo più avanti, il valore predefinito di “nice” può essere cambiato. Il tempo speso per l’esecuzione dei processi con un “nice” impostato manualmente appare come valore ni.
Questo è seguito da id, che è il tempo che la CPU rimane inattiva. La maggior parte dei sistemi operativi mette la CPU in una modalità di risparmio energetico quando è inattiva. Poi viene il valore wa, che è il tempo che la CPU trascorre in attesa che l’I/O sia completato.
Gli interrupt sono segnali al processore su un evento che richiede attenzione immediata. Gli interrupt hardware sono tipicamente usati dalle periferiche per informare il sistema di eventi, come la pressione di un tasto su una tastiera. D’altra parte, gli interrupt software sono generati da istruzioni specifiche eseguite sul processore. In entrambi i casi, il sistema operativo li gestisce, e il tempo speso per gestire gli interrupt hardware e software è dato rispettivamente da hi e si.
In un ambiente virtualizzato, una parte delle risorse della CPU è data ad ogni macchina virtuale (VM). Il sistema operativo rileva quando ha del lavoro da fare, ma non può eseguirlo perché la CPU è occupata su qualche altra VM. La quantità di tempo perso in questo modo è il tempo “rubato”, mostrato come st.
Carico medio

La sezione carico medio rappresenta il “carico” medio su uno, cinque e quindici minuti. Il “carico” è una misura della quantità di lavoro computazionale che un sistema esegue. Su Linux, il carico è il numero di processi negli stati R e D in un dato momento. Il valore “load average” vi dà una misura relativa di quanto tempo dovete aspettare che le cose vengano fatte.
Consideriamo alcuni esempi per capire questo concetto. Su un sistema a core singolo, una media di carico di 0,4 significa che il sistema sta facendo solo il 40% del lavoro che può fare. Una media di carico di 1 significa che il sistema è esattamente alla capacità – il sistema sarà sovraccaricato aggiungendo anche un po’ di lavoro supplementare. Un sistema con una media di carico di 2,12 significa che è sovraccarico del 112% di lavoro in più di quello che può gestire.
Su un sistema multi-core, si dovrebbe prima dividere la media di carico con il numero di core della CPU per ottenere una misura simile.
Inoltre, “media di carico” non è in realtà la tipica “media” che la maggior parte di noi conosce. È una “media mobile esponenziale”, il che significa che una piccola parte delle medie di carico precedenti è incorporata nel valore attuale. Se siete interessati, questo articolo copre tutti i dettagli tecnici.
Comprendere l’interfaccia di top: l’area delle attività
L’area di riepilogo è relativamente più semplice, e contiene una lista di processi. In questa sezione, impareremo a conoscere le diverse colonne mostrate nell’output predefinito di top.
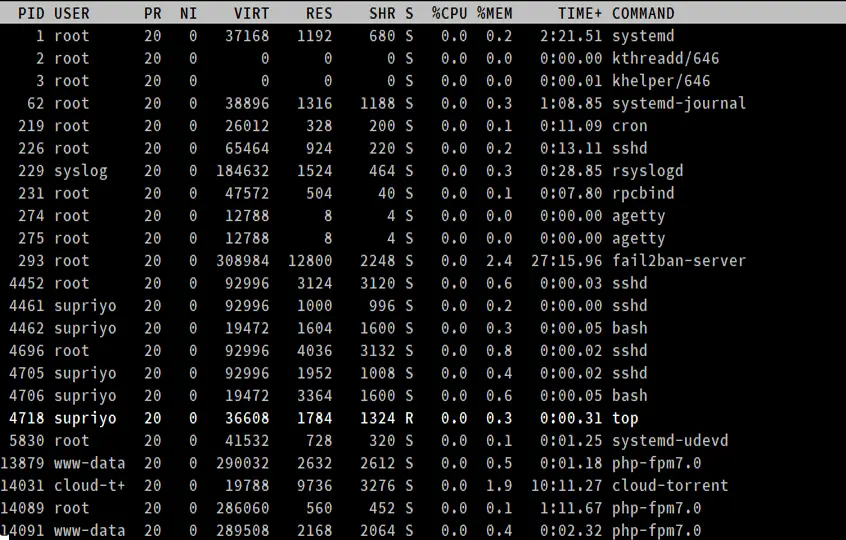
- PID
Questo è l’ID del processo, un intero positivo unico che identifica un processo.
- USER
Questo è il nome utente “effettivo” (che corrisponde ad un ID utente) dell’utente che ha avviato il processo. Linux assegna un ID utente reale e un ID utente effettivo ai processi; quest’ultimo permette ad un processo di agire per conto di un altro utente. (Per esempio, un utente non root può elevarsi a root per installare un pacchetto.)
- PR e NI
Il campo “NI” mostra il valore “nice” di un processo. Il campo “PR” mostra la priorità di programmazione del processo dal punto di vista del kernel. Il valore nice influenza la priorità di un processo.
- VIRT, RES, SHR e %MEM
Questi tre campi sono legati al consumo di memoria dei processi. “VIRT” è la quantità totale di memoria consumata da un processo. Questo include il codice del programma, i dati memorizzati dal processo in memoria, così come tutte le regioni di memoria che sono state scambiate sul disco. “RES” è la memoria consumata dal processo in RAM, e “%MEM” esprime questo valore come percentuale della RAM totale disponibile. Infine, “SHR” è la quantità di memoria condivisa con altri processi.
- S
Come abbiamo visto prima, un processo può essere in vari stati. Questo campo mostra lo stato del processo nella forma di lettera singola.
- TIME+
Questo è il tempo totale di CPU usato dal processo dal suo inizio, preciso al centesimo di secondo.
- COMANDO
La colonna COMANDO mostra il nome dei processi.
Esempi di utilizzo dei comandi di Top
Finora abbiamo parlato dell’interfaccia di Top. Tuttavia, può anche gestire i processi e puoi controllare vari aspetti dell’output di top. In questa sezione, prenderemo in esame alcuni esempi.
Nella maggior parte degli esempi qui sotto, dovete premere un tasto mentre top è in esecuzione. Tenete a mente che questi tasti sono sensibili al maiuscolo/minuscolo, quindi se premete “k” mentre il Caps Lock è attivo, avete effettivamente premuto una “K”, e il comando non funzionerà, o farà qualcosa di completamente diverso.
Uccidere i processi
Se volete uccidere un processo, premete semplicemente “k” quando top è in esecuzione. Questo farà apparire un prompt, che chiederà l’ID del processo e premerà invio.
In seguito, inserite il segnale con cui il processo deve essere ucciso. Se lo lasciate vuoto, Top usa un SIGTERM, che permette ai processi di terminare con grazia. Se vuoi uccidere un processo con forza, puoi digitare SIGKILL qui. Potete anche digitare il numero del segnale qui. Per esempio, il numero per SIGTERM è 15 e SIGKILL è 9.
Se lasciate vuoto l’ID del processo e premete direttamente enter, terminerà il processo più in alto nella lista. Come abbiamo detto in precedenza, puoi scorrere usando i tasti freccia, e cambiare il processo che vuoi uccidere in questo modo.
Ordinamento della lista dei processi
Una delle ragioni più frequenti per usare uno strumento come top è scoprire quale processo sta consumando più risorse. Potete premere i seguenti tasti per ordinare l’elenco:
- ‘M’ per ordinare in base all’utilizzo della memoria
- ‘P’ per ordinare in base all’utilizzo della CPU
- ‘N’ per ordinare in base all’ID del processo
- ‘T’ per ordinare in base al tempo di esecuzione
Di default, top visualizza tutti i risultati in ordine decrescente. Tuttavia, puoi passare all’ordine ascendente premendo ‘R’.
Puoi anche ordinare la lista con l’interruttore -o. Per esempio, se volete ordinare i processi in base all’utilizzo della CPU, potete farlo con:
top -o %CPU
E’ possibile ordinare l’elenco in base a qualsiasi attributo nell’area di riepilogo allo stesso modo.
Mostra un elenco di thread invece che di processi
Abbiamo già parlato di come Linux passa da un processo all’altro. Sfortunatamente, i processi non condividono la memoria o altre risorse, rendendo tali scambi piuttosto lenti. Linux, come molti altri sistemi operativi, supporta un’alternativa “leggera”, chiamata “thread”. Essi sono parte di un processo e condividono alcune regioni di memoria e altre risorse, ma possono essere eseguiti contemporaneamente come i processi.
Di default, top mostra una lista di processi nel suo output. Se invece volete elencare i thread, premete ‘H’ quando top è in esecuzione. Notate che la linea “Tasks” dice “Threads” invece, e mostra il numero di threads invece dei processi.
Avrete notato come nessuno degli attributi nella lista dei processi sia cambiato. Com’è possibile, dato che i processi differiscono dai thread? All’interno del kernel Linux, thread e processi sono gestiti utilizzando le stesse strutture dati. Così, ogni thread ha il suo ID, il suo stato e così via.
Se vuoi tornare alla vista del processo, premi di nuovo ‘H’. Inoltre, è possibile utilizzare l’interruttore -H per visualizzare i thread di default.
top -H
Mostra i percorsi completi
Di default, top non mostra il percorso completo del programma, o fa una distinzione tra processi dello spazio kernel e dello spazio utente. Se hai bisogno di queste informazioni, premi ‘c’ mentre top è in esecuzione. Premi di nuovo ‘c’ per tornare all’impostazione predefinita.
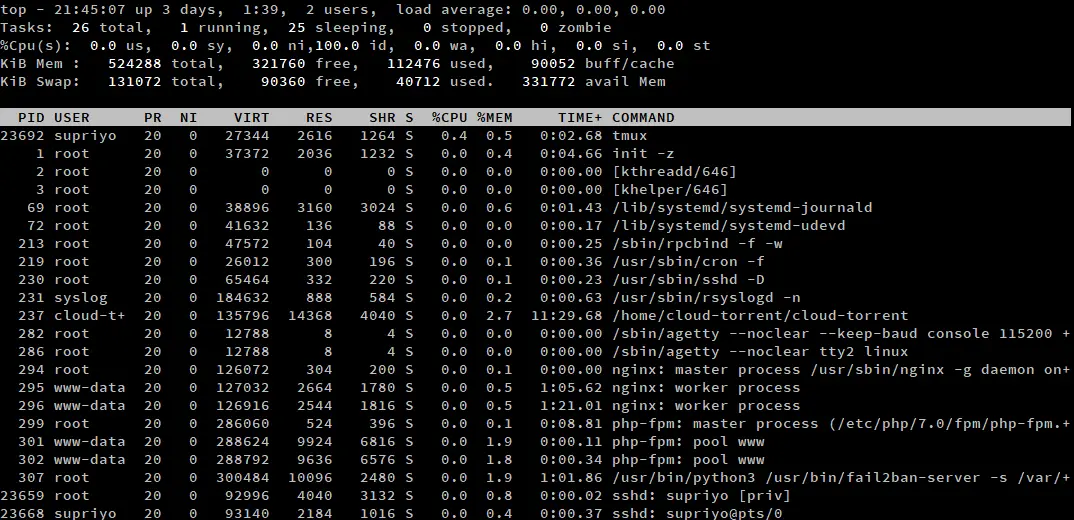
I processi dello spazio kernel sono contrassegnati da parentesi quadre. Come esempio, nello screenshot qui sopra ci sono due processi del kernel, kthreadd e khelper. Nella maggior parte delle installazioni di Linux, ce ne saranno di solito alcuni di più.
In alternativa, si può anche avviare la parte superiore con l’argomento -c:
top -c
Vista foresta
A volte, si potrebbe voler vedere la gerarchia figlio-parente dei processi. Puoi vedere questo con la vista foresta, premendo ‘v’/’V’ mentre top è in esecuzione.
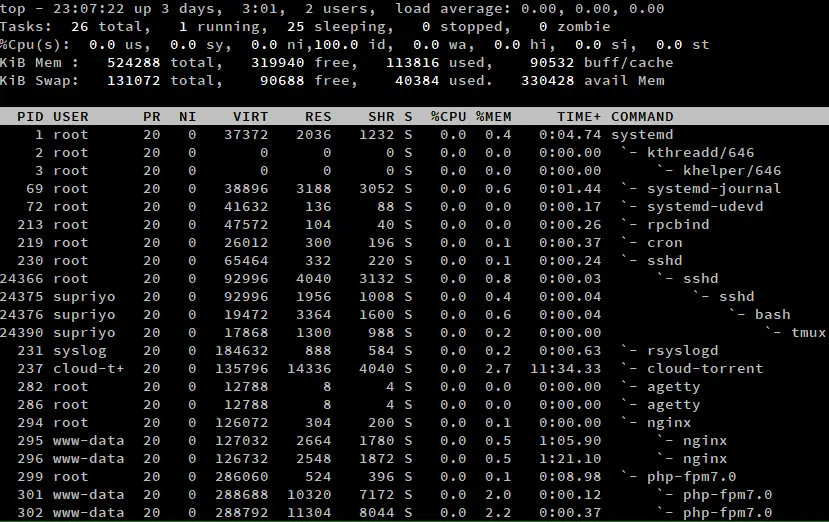
Come puoi vedere dallo screenshot sopra, il processo systemd è stato il primo ad avviarsi sul sistema. Ha avviato processi come sshd, che a sua volta ha creato altri processi sshd, e così via.
Elenco dei processi di un utente
Per elencare i processi di un certo utente, premere ‘u’ quando top è in esecuzione. Poi, digita il nome utente, o lascialo vuoto per visualizzare i processi di tutti gli utenti.
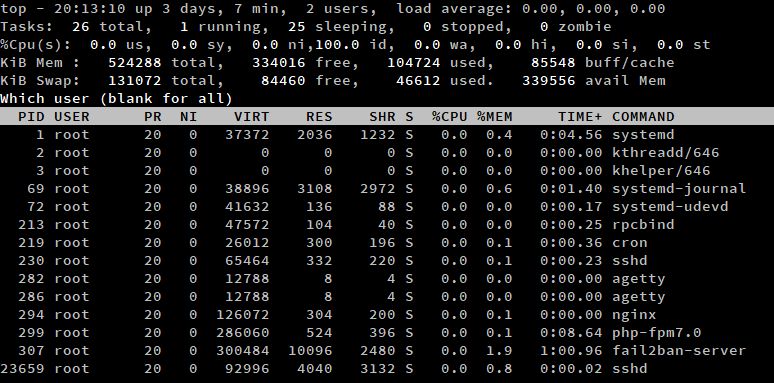
In alternativa, puoi eseguire il comando top con lo switch -u. In questo esempio, abbiamo elencato tutti i processi dell’utente root.
top -u root
Filtrare i processi
Se avete molti processi con cui lavorare, un semplice ordinamento non funziona abbastanza bene. In una tale situazione, è possibile utilizzare il filtraggio di Top per concentrarsi su alcuni processi. Per attivare questa modalità, premi ‘o’/’O’. Un prompt appare all’interno di top e puoi digitare un’espressione di filtro qui.
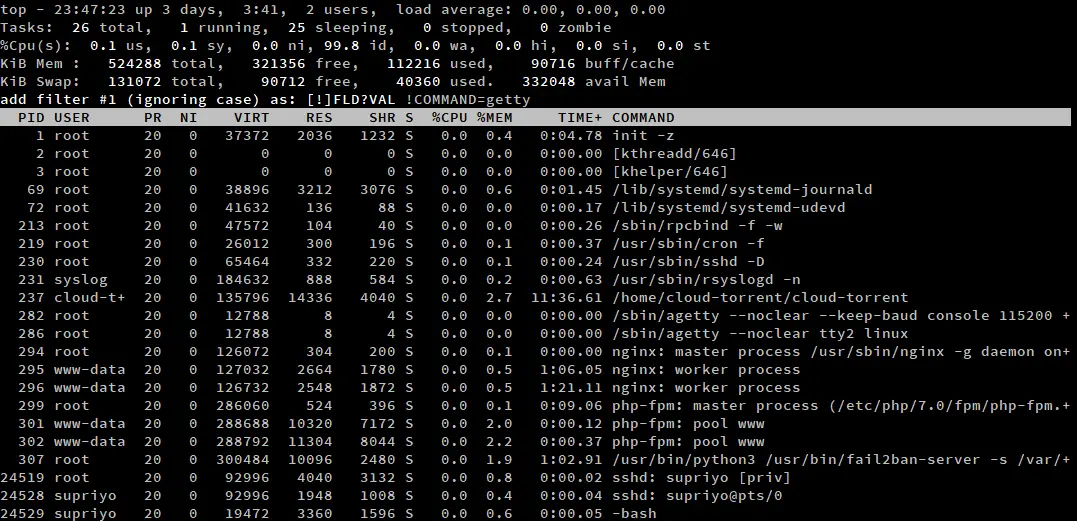
Un’espressione di filtro è una dichiarazione che specifica una relazione tra un attributo e un valore. Alcuni esempi di filtri sono:
-
COMMAND=getty: Filtra i processi che contengono “getty” nell’attributo COMMAND. -
!COMMAND=getty: Filtra i processi che non hanno “getty” nell’attributo COMMAND. -
%CPU>3.0: Filtra i processi che hanno un utilizzo della CPU superiore al 3%.
Una volta aggiunto un filtro, è possibile ridurre ulteriormente le cose aggiungendo altri filtri. Per cancellare qualsiasi filtro aggiunto, premi ‘=’.
Cambiare l’aspetto predefinito delle statistiche della CPU e della memoria
Se ti trovi per lo più in un ambiente GUI, potrebbe non piacerti il modo predefinito di Top di mostrare le statistiche della CPU e della memoria. Puoi premere ‘t’ e ‘m’ per cambiare lo stile delle statistiche della CPU e della memoria. Ecco uno screenshot di top, dove abbiamo premuto ‘t’ e ‘m’ una volta.
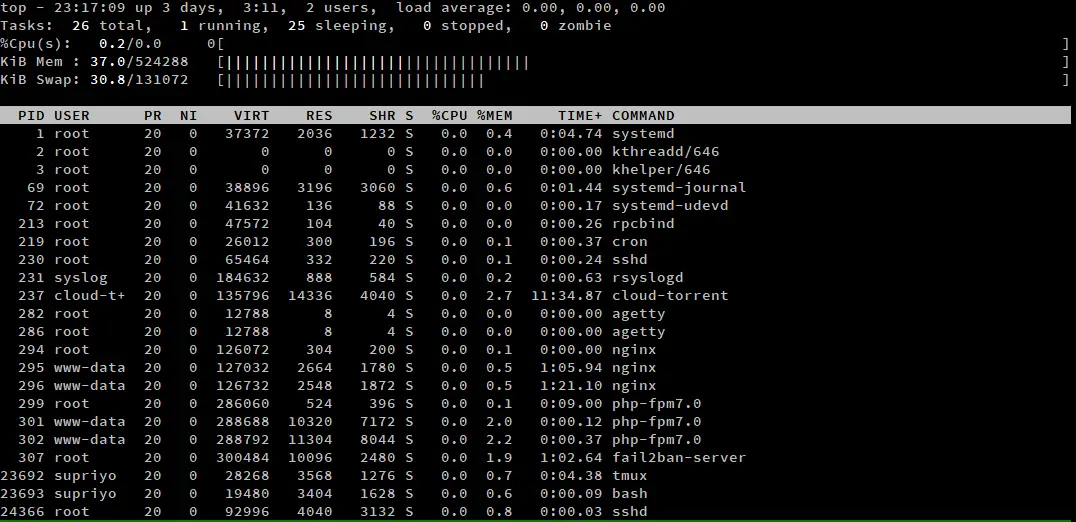
Se premete ‘t’ o ‘m’ ripetutamente, si passa attraverso quattro diverse visualizzazioni. Nelle prime due pressioni, passa attraverso due diversi tipi di barre di progresso. Se premete il tasto una terza volta, la barra di progresso è nascosta. Se premi di nuovo il tasto, riporta i contatori di default, basati sul testo.
Salvare le tue impostazioni
Se hai fatto delle modifiche all’output di top, puoi salvarle per un uso successivo premendo ‘W’. top scrive la sua configurazione nel file .toprc nella vostra home directory.
Conclusione
Il comando top è estremamente utile per monitorare e gestire i processi su un sistema Linux. Questo articolo ha solo grattato la superficie, e c’è un bel po’ di cose che non abbiamo coperto. Per esempio, ci sono molte altre colonne che puoi aggiungere a top. Per tutte queste cose, assicuratevi di controllare la pagina man eseguendo man top sul vostro sistema.
Se ti è piaciuto questo post, per favore condividilo 🙂