Apache Spark: Resilient Distributed Datasets
RDDs stellen sowohl die Idee dar, wie ein großer Datensatz in Apache Spark repräsentiert wird, als auch die Abstraktion für die Arbeit mit ihm. Dieser Abschnitt behandelt Ersteres, die folgenden Abschnitte behandeln Letzteres. Laut dem grundlegenden Papier zu Spark sind „RDDs unveränderliche, fehlertolerante, parallele Datenstrukturen, die es Benutzern ermöglichen, Zwischenergebnisse explizit im Speicher zu halten, ihre Partitionierung zu steuern, um die Datenplatzierung zu optimieren, und sie mit einem reichhaltigen Satz von Operatoren zu manipulieren.“ Lassen Sie uns diese Beschreibung auseinandernehmen, um die Ideen hinter dem RDD-Konzept wirklich zu verstehen.
Unveränderlich
RDDs sind so konzipiert, dass sie unveränderlich sind, was bedeutet, dass Sie eine bestimmte Zeile im Datensatz, der durch dieses RDD repräsentiert wird, nicht spezifisch ändern können. Sie können eine der verfügbaren RDD-Operationen aufrufen, um die Zeilen im RDD so zu manipulieren, wie Sie es wünschen, aber diese Operation wird ein neues RDD zurückgeben. Das Basis-RDD bleibt unverändert, und das neue RDD enthält die Daten so, wie Sie sie verändert haben. Die Unveränderlichkeit erfordert, dass ein RDD seine Abstammungsinformationen trägt, die Spark nutzt, um effizient Fehlertoleranzfähigkeiten bereitzustellen.
Fehlertolerant
Die Fähigkeit, mehrere Datensätze parallel zu verarbeiten, erfordert in der Regel einen Cluster von Maschinen zum Hosten und Ausführen der Berechnungslogik. Wenn eine oder mehrere dieser Maschinen ausfallen oder aufgrund unerwarteter Umstände extrem langsam werden, wie wirkt sich das auf die Gesamtverarbeitung dieser Datensätze aus? Die gute Nachricht ist, dass Spark sich automatisch um den Umgang mit dem Ausfall für seine Benutzer kümmert, indem es den ausgefallenen Teil unter Verwendung der Lineage-Informationen neu aufbaut.
Parallele Datenstrukturen
Stellen Sie sich den Anwendungsfall vor, dass Ihnen jemand eine große Protokolldatei mit einer Größe von 1 TB gibt und Sie herausfinden sollen, wie viele Protokollanweisungen das Wort „Exception“ darin enthalten. Eine langsame Lösung wäre, die Protokolldatei von Anfang bis Ende zu durchlaufen und die Logik auszuführen, um festzustellen, ob eine bestimmte Protokollanweisung das Wort „Exception“ enthält. Eine schnellere Lösung wäre, diese 1 TB große Datei in mehrere Chunks zu unterteilen und die oben genannte Logik auf jedem Chunk in parallelisierter Weise auszuführen, um die Gesamtverarbeitungszeit zu beschleunigen. Jeder Chunk enthält eine Sammlung von Zeilen. Die Zeilensammlung ist im Wesentlichen die Datenstruktur, die einen Satz von Zeilen enthält und die Möglichkeit bietet, durch jede Zeile zu iterieren. Jeder Chunk enthält eine Sammlung von Zeilen, und alle Chunks werden parallel verarbeitet. Daher kommt auch der Begriff parallele Datenstrukturen.
In-Memory Computing
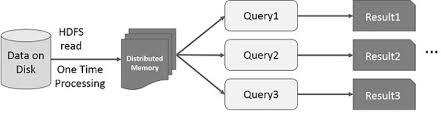
Die Idee, die Berechnung großer Datenmengen, die auf Festplatten liegen, mit Hilfe eines Clusters von Maschinen zu parallelisieren, wurde durch ein MapReduce-Papier2 von Google eingeführt. Diese Idee wurde implementiert und ist im Open-Source-Projekt Hadoop verfügbar. Auf dieser soliden Grundlage aufbauend, verschiebt RDD die Geschwindigkeitsgrenze, indem es die Möglichkeit einführt, verteilte In-Memory-Berechnungen durchzuführen.
Es ist immer faszinierend, die Geschichten zu untersuchen, die zur Entstehung einer innovativen Idee geführt haben. In der Welt der Big-Data-Verarbeitung möchte man, sobald man in der Lage ist, mit einer Reihe rudimentärer Techniken auf zuverlässige Weise Erkenntnisse aus großen Datensätzen zu extrahieren, anspruchsvollere Techniken einsetzen, um die dafür benötigte Zeit zu verkürzen. An dieser Stelle hilft verteilte In-Memory-Berechnung.
Die ausgefeilte Technik, auf die ich mich beziehe, ist die Verwendung von maschinellem Lernen, um verschiedene Vorhersagen durchzuführen oder Muster aus großen Datensätzen zu extrahieren. Algorithmen des maschinellen Lernens sind von Natur aus iterativ, das heißt, sie müssen viele Iterationen durchlaufen, um einen optimalen Zustand zu erreichen. Hier kann verteilte In-Memory-Berechnung helfen, die Fertigstellungszeit von Tagen auf Stunden zu reduzieren. Ein weiterer Anwendungsfall, der enorm von verteilten In-Memory-Berechnungen profitieren kann, ist das interaktive Data Mining, bei dem mehrere Ad-hoc-Abfragen auf derselben Teilmenge von Daten durchgeführt werden. Wenn diese Teilmenge von Daten im Speicher persistiert wird, werden diese Abfragen in Sekunden und nicht in Minuten erledigt.