Apache Spark : Resilient Distributed Datasets
Les RDD représentent à la fois l’idée de la façon dont un grand ensemble de données est représenté dans Apache Spark et l’abstraction pour travailler avec lui. Cette section couvrira la première, et les sections suivantes couvriront la seconde. Selon l’article fondateur de Spark, « les RDD sont des structures de données immuables, tolérantes aux pannes et parallèles qui permettent aux utilisateurs de persister explicitement les résultats intermédiaires en mémoire, de contrôler leur partitionnement pour optimiser le placement des données et de les manipuler en utilisant un riche ensemble d’opérateurs. » Disséquons cette description pour vraiment comprendre les idées derrière le concept RDD.
Immuable
Les RDD sont conçus pour être immuables, ce qui signifie que vous ne pouvez pas modifier spécifiquement une ligne particulière dans le jeu de données représenté par ce RDD. Vous pouvez appeler l’une des opérations RDD disponibles pour manipuler les lignes du RDD comme vous le souhaitez, mais cette opération renverra un nouveau RDD. Le RDD de base restera inchangé, et le nouveau RDD contiendra les données de la manière dont vous les avez modifiées. L’immuabilité exige qu’un RDD porte ses informations de lignage que Spark exploite pour fournir efficacement des capacités de tolérance aux pannes.
Tolérance aux pannes
La capacité de traiter plusieurs ensembles de données en parallèle nécessite généralement un cluster de machines pour héberger et exécuter la logique de calcul. Si une ou plusieurs de ces machines meurent ou deviennent extrêmement lentes en raison de circonstances inattendues, alors comment cela affectera-t-il le traitement global de ces ensembles de données ? La bonne nouvelle, c’est que Spark s’occupe automatiquement de gérer la panne pour le compte de ses utilisateurs en reconstruisant la partie défaillante à l’aide des informations de lignage.
Structures de données parallèles
Imaginez le cas d’utilisation où quelqu’un vous donne un gros fichier journal qui fait 1 To et on vous demande de trouver combien d’énoncés de journal contiennent le mot » exception « . Une solution lente consisterait à parcourir le fichier journal du début à la fin et à exécuter la logique permettant de déterminer si une déclaration particulière contient le mot « exception ». Une solution plus rapide serait de diviser ce fichier de 1 To en plusieurs morceaux et d’exécuter la logique susmentionnée sur chaque morceau de manière parallélisée pour accélérer le temps de traitement global. Chaque chunk contient une collection de lignes. La collection de lignes est essentiellement la structure de données qui contient un ensemble de lignes et offre la possibilité d’itérer dans chaque ligne. Chaque chunk contient une collection de lignes, et tous les chunks sont traités en parallèle. C’est de là que vient l’expression structures de données parallèles.
In-Memory Computing
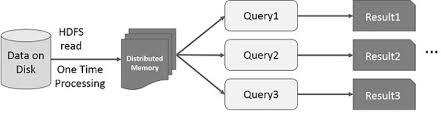
L’idée d’accélérer le calcul de grands ensembles de données qui résident sur des disques de manière parallélisée en utilisant un cluster de machines a été introduite par un article MapReduce2 de Google. Cette idée a été mise en œuvre et est disponible dans le projet open source Hadoop. S’appuyant sur cette base solide, RDD repousse les limites de la vitesse en introduisant la possibilité de faire du calcul distribué en mémoire.
Il est toujours fascinant d’examiner les histoires qui ont conduit à la création d’une idée innovante. Dans le monde du traitement des big data, une fois que vous êtes en mesure d’extraire des informations de grands ensembles de données de manière fiable en utilisant un ensemble de techniques rudimentaires, vous voulez utiliser des techniques plus sophistiquées pour réduire le temps nécessaire pour y parvenir. C’est là que le calcul distribué en mémoire est utile.
La technique sophistiquée à laquelle je fais référence est l’utilisation de l’apprentissage automatique pour effectuer diverses prédictions ou extraire des modèles à partir de grands ensembles de données. Les algorithmes d’apprentissage automatique sont itératifs par nature, ce qui signifie qu’ils doivent passer par de nombreuses itérations pour arriver à un état optimal. C’est là que le calcul distribué en mémoire peut aider à réduire le temps de réalisation de plusieurs jours à quelques heures. Un autre cas d’utilisation qui peut bénéficier énormément du calcul distribué en mémoire est l’exploration interactive des données, où de multiples requêtes ad hoc sont effectuées sur le même sous-ensemble de données. Si ce sous-ensemble de données est persistant en mémoire, ces requêtes prendront des secondes et non des minutes pour être complétées.