Apache Spark: Resilient Distributed Datasets
Los RDDs representan tanto la idea de cómo se representa un gran conjunto de datos en Apache Spark como la abstracción para trabajar con él. Esta sección cubrirá lo primero, y las siguientes secciones cubrirán lo segundo. Según el documento seminal de Spark, «los RDDs son estructuras de datos paralelas, inmutables y tolerantes a fallos que permiten a los usuarios persistir explícitamente los resultados intermedios en memoria, controlar su partición para optimizar la colocación de los datos y manipularlos utilizando un rico conjunto de operadores.» Vamos a diseccionar esta descripción para entender realmente las ideas que hay detrás del concepto de RDD.
Inmutable
Los RDDs están diseñados para ser inmutables, lo que significa que no se puede modificar específicamente una fila particular en el conjunto de datos representado por ese RDD. Puedes llamar a una de las operaciones disponibles del RDD para manipular las filas del RDD de la forma que quieras, pero esa operación devolverá un nuevo RDD. El RDD básico permanecerá sin cambios, y el nuevo RDD contendrá los datos de la forma en que usted los alteró. La inmutabilidad requiere que un RDD lleve su información de linaje que Spark aprovecha para proporcionar eficientemente capacidades de tolerancia a fallos.
Tolerante a fallos
La capacidad de procesar múltiples conjuntos de datos en paralelo suele requerir un clúster de máquinas para alojar y ejecutar la lógica computacional. Si una o más de esas máquinas mueren o se vuelven extremadamente lentas debido a circunstancias inesperadas, entonces ¿cómo afectará eso al procesamiento general de esos conjuntos de datos? La buena noticia es que Spark se encarga automáticamente de gestionar el fallo en nombre de sus usuarios reconstruyendo la parte que ha fallado utilizando la información de linaje.
Estructuras de datos paralelas
Imagine el caso de uso en el que alguien le da un gran archivo de registro que tiene un tamaño de 1TB y se le pide que averigüe cuántas sentencias de registro contienen la palabra «excepción» en él. Una solución lenta sería iterar a través de ese archivo de registro desde el principio hasta el final y ejecutar la lógica de determinar si una declaración de registro particular contiene la palabra excepción. Una solución más rápida sería dividir ese archivo de 1TB en varios trozos y ejecutar la lógica mencionada en cada trozo de forma paralela para acelerar el tiempo de procesamiento total. Cada trozo contiene una colección de filas. La colección de filas es esencialmente la estructura de datos que contiene un conjunto de filas y proporciona la capacidad de iterar a través de cada fila. Cada chunk contiene una colección de filas, y todos los chunks están siendo procesados en paralelo. De aquí viene la frase estructuras de datos paralelas.
Computación en memoria
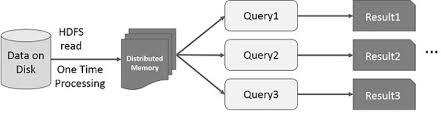
La idea de acelerar el cálculo de grandes conjuntos de datos que residen en discos de forma paralela utilizando un clúster de máquinas fue introducida por un documento de MapReduce2 de Google. Esta idea se implementó y está disponible en el proyecto de código abierto Hadoop. Partiendo de esa sólida base, RDD empuja el límite de la velocidad introduciendo la capacidad de hacer computación distribuida en memoria.
Siempre es fascinante examinar las historias que llevaron a la creación de una idea innovadora. En el mundo del procesamiento de big data, una vez que se es capaz de extraer información de grandes conjuntos de datos de forma fiable utilizando un conjunto de técnicas rudimentarias, se desea utilizar técnicas más sofisticadas para reducir el tiempo que se tarda en hacerlo. Aquí es donde ayuda la computación distribuida en memoria.
La técnica sofisticada a la que me refiero es el uso del aprendizaje automático para realizar diversas predicciones o extraer patrones de grandes conjuntos de datos. Los algoritmos de aprendizaje automático son iterativos por naturaleza, lo que significa que necesitan pasar por muchas iteraciones para llegar a un estado óptimo. Aquí es donde la computación distribuida en memoria puede ayudar a reducir el tiempo de ejecución de días a horas. Otro caso de uso que puede beneficiarse enormemente de la computación distribuida en memoria es la minería de datos interactiva, en la que se realizan múltiples consultas ad hoc sobre el mismo subconjunto de datos. Si ese subconjunto de datos se mantiene en memoria, esas consultas tardarán segundos y no minutos en completarse.