Ingeniería inversa
MachinesEdit
A medida que el diseño asistido por ordenador (CAD) se ha hecho más popular, la ingeniería inversa se ha convertido en un método viable para crear un modelo virtual 3D de una pieza física existente para su uso en CAD 3D, CAM, CAE u otro software. El proceso de ingeniería inversa consiste en medir un objeto y luego reconstruirlo como un modelo 3D. El objeto físico puede medirse utilizando tecnologías de escaneado 3D como MMC, escáneres láser, digitalizadores de luz estructurada o escaneado CT industrial (tomografía computarizada). Los datos medidos por sí solos, normalmente representados como una nube de puntos, carecen de información topológica y de intención de diseño. La primera puede recuperarse convirtiendo la nube de puntos en una malla de caras triangulares. El objetivo de la ingeniería inversa es ir más allá de la producción de una malla de este tipo y recuperar la intención del diseño en términos de superficies analíticas simples, cuando sea apropiado (planos, cilindros, etc.), así como posiblemente superficies NURBS para producir un modelo CAD de representación de límites. La recuperación de dicho modelo permite modificar un diseño para satisfacer nuevos requisitos, generar un plan de fabricación, etc.
El modelado híbrido es un término comúnmente utilizado cuando se implementan conjuntamente el modelado NURBS y el paramétrico. El uso de una combinación de superficies geométricas y de forma libre puede proporcionar un potente método de modelado 3D. Las áreas de datos de forma libre pueden combinarse con superficies geométricas exactas para crear un modelo híbrido. Un ejemplo típico de esto sería la ingeniería inversa de una culata, que incluye características de fundición de forma libre, como camisas de agua y áreas mecanizadas de alta tolerancia.
La ingeniería inversa también es utilizada por las empresas para llevar la geometría física existente a entornos de desarrollo de productos digitales, para hacer un registro digital en 3D de sus propios productos o para evaluar los productos de la competencia. Se utiliza para analizar cómo funciona un producto, qué hace, qué componentes tiene; estimar los costes; identificar posibles infracciones de patentes; etc.
La ingeniería de valor, una actividad relacionada que también utilizan las empresas, consiste en deconstruir y analizar los productos. Sin embargo, el objetivo es encontrar oportunidades de reducción de costes.
Ingeniería del software
En 1990, el Instituto de Ingenieros Eléctricos y Electrónicos (IEEE) definió la ingeniería inversa (del software) como «el proceso de análisis de un sistema sujeto para identificar los componentes del sistema y sus interrelaciones y para crear representaciones del sistema en otra forma o a un nivel superior de abstracción» en el que el «sistema sujeto» es el producto final del desarrollo del software. La ingeniería inversa es un proceso de examen únicamente, y el sistema de software en cuestión no se modifica, lo que supondría una reingeniería o reestructuración. La ingeniería inversa puede realizarse desde cualquier etapa del ciclo del producto, no necesariamente desde el producto final funcional.
Hay dos componentes en la ingeniería inversa: la redocumentación y la recuperación del diseño. La redocumentación es la creación de una nueva representación del código informático para que sea más fácil de entender. Por su parte, la recuperación del diseño es el uso de la deducción o el razonamiento a partir del conocimiento general o la experiencia personal del producto para comprender plenamente su funcionalidad. También puede verse como «retroceder en el ciclo de desarrollo». En este modelo, el resultado de la fase de implementación (en forma de código fuente) se devuelve a la fase de análisis, en una inversión del modelo tradicional de cascada. Otro término para esta técnica es el de comprensión del programa. La Conferencia de Trabajo sobre Ingeniería Inversa (WCRE) se celebra anualmente para explorar y ampliar las técnicas de ingeniería inversa. La ingeniería de software asistida por ordenador (CASE) y la generación automatizada de código han contribuido en gran medida al campo de la ingeniería inversa.
La tecnología antimanipulación de software, como la ofuscación, se utiliza para disuadir tanto de la ingeniería inversa como de la reingeniería del software propietario y de los sistemas impulsados por software. En la práctica, surgen dos tipos principales de ingeniería inversa. En el primer caso, el código fuente ya está disponible para el software, pero se descubren aspectos de nivel superior del programa, que quizás están mal documentados o documentados pero ya no son válidos. En el segundo caso, no hay código fuente disponible para el software, y cualquier esfuerzo por descubrir un posible código fuente para el software se considera ingeniería inversa. El segundo uso del término es más familiar para la mayoría de la gente. La ingeniería inversa de software puede hacer uso de la técnica de diseño de sala limpia para evitar la violación de los derechos de autor.
En una nota relacionada, las pruebas de caja negra en la ingeniería de software tienen mucho en común con la ingeniería inversa. El probador suele tener la API, pero tiene los objetivos de encontrar errores y características no documentadas golpeando el producto desde fuera.
Otros propósitos de la ingeniería inversa incluyen la auditoría de seguridad, la eliminación de la protección anticopia («cracking»), la elusión de las restricciones de acceso a menudo presentes en la electrónica de consumo, la personalización de los sistemas integrados (como los sistemas de gestión del motor), las reparaciones o adaptaciones internas, la habilitación de características adicionales en el hardware de bajo coste «lisiado» (como algunos conjuntos de chips de tarjetas gráficas), o incluso la mera satisfacción de la curiosidad.
Edición de software binario
La ingeniería inversa binaria se realiza si el código fuente de un software no está disponible. Este proceso se denomina a veces ingeniería inversa de código, o RCE. Por ejemplo, la descompilación de los binarios para la plataforma Java puede llevarse a cabo utilizando Jad. Un caso famoso de ingeniería inversa fue la primera implementación no IBM de la BIOS del PC, que lanzó la histórica industria de los compatibles IBM PC, que ha sido la plataforma de hardware de ordenador abrumadoramente dominante durante muchos años. La ingeniería inversa de software está protegida en Estados Unidos por la excepción de uso justo de la ley de derechos de autor. El software Samba, que permite a los sistemas que no ejecutan Microsoft Windows compartir archivos con los sistemas que lo ejecutan, es un ejemplo clásico de ingeniería inversa de software, ya que el proyecto Samba tuvo que aplicar ingeniería inversa a información no publicada sobre cómo funcionaba el intercambio de archivos de Windows para que los ordenadores que no son de Windows pudieran emularlo. El proyecto Wine hace lo mismo con la API de Windows, y OpenOffice.org es una de las partes que lo hace con los formatos de archivo de Microsoft Office. El proyecto ReactOS es aún más ambicioso en sus objetivos al tratar de ofrecer compatibilidad binaria (ABI y API) con los actuales sistemas operativos Windows de la rama NT, lo que permite que el software y los controladores escritos para Windows se ejecuten en una contraparte de software libre (GPL) de ingeniería inversa. WindowsSCOPE permite realizar ingeniería inversa de todo el contenido de la memoria viva de un sistema Windows, incluyendo una ingeniería inversa gráfica a nivel binario de todos los procesos en ejecución.
Otro ejemplo clásico, aunque no muy conocido, es que en 1987 Bell Laboratories realizó ingeniería inversa del sistema Mac OS 4.1, que originalmente se ejecutaba en el Apple Macintosh SE, para poder ejecutarlo en máquinas RISC propias.
Técnicas de software binarioEditar
La ingeniería inversa del software puede llevarse a cabo mediante varios métodos.Los tres grupos principales de ingeniería inversa del software son
- El análisis mediante la observación del intercambio de información, más frecuente en la ingeniería inversa de protocolos, que implica el uso de analizadores de bus y rastreadores de paquetes, como para acceder a un bus informático o a una conexión de red informática y revelar los datos de tráfico en ellos. El comportamiento del bus o de la red puede entonces analizarse para producir una implementación independiente que imite ese comportamiento. Esto es especialmente útil para la ingeniería inversa de controladores de dispositivos. A veces, la ingeniería inversa en sistemas embebidos se ve muy favorecida por las herramientas introducidas deliberadamente por el fabricante, como los puertos JTAG u otros medios de depuración. En Microsoft Windows, son populares los depuradores de bajo nivel como SoftICE.
- Desmontaje mediante un desensamblador, lo que significa que el lenguaje de máquina en bruto del programa se lee y se entiende en sus propios términos, sólo con la ayuda de mnemónicos de lenguaje de máquina. Funciona con cualquier programa de ordenador, pero puede llevar bastante tiempo, especialmente para aquellos que no están acostumbrados al código máquina. El desensamblador interactivo es una herramienta especialmente popular.
- Descompilación mediante un descompilador, un proceso que intenta, con resultados variables, recrear el código fuente en algún lenguaje de alto nivel para un programa sólo disponible en código máquina o bytecode.
Clasificación de softwareEditar
La clasificación de software es el proceso de identificación de similitudes entre diferentes binarios de software (como dos versiones diferentes del mismo binario) utilizado para detectar relaciones de código entre muestras de software. La tarea se realizaba tradicionalmente de forma manual por varias razones (como el análisis de parches para la detección de vulnerabilidades y la infracción de derechos de autor), pero ahora se puede realizar de forma algo automática para un gran número de muestras.
Este método se está utilizando sobre todo para tareas de ingeniería inversa largas y exhaustivas (análisis completo de un algoritmo complejo o una pieza grande de software). En general, la clasificación estadística se considera un problema difícil, lo que también es cierto para la clasificación de software, por lo que son pocas las soluciones/herramientas que manejan bien esta tarea.
Edición de código fuente
Una serie de herramientas UML se refieren al proceso de importación y análisis de código fuente para generar diagramas UML como «ingeniería inversa.» Ver Lista de herramientas UML.
Aunque UML es un enfoque para proporcionar «ingeniería inversa», los avances más recientes en las actividades de estándares internacionales han dado lugar al desarrollo del Metamodelo de Descubrimiento de Conocimiento (KDM). Este estándar ofrece una ontología para la representación intermedia (o abstracta) de las construcciones del lenguaje de programación y sus interrelaciones. El KDM, que es una norma del Object Management Group (que está a punto de convertirse en norma ISO), ha empezado a imponerse en la industria con el desarrollo de herramientas y entornos de análisis que permiten extraer y analizar código fuente, binario y de bytes. Para el análisis del código fuente, la arquitectura granular de las normas KDM permite la extracción de los flujos del sistema de software (datos, control y mapas de llamadas), las arquitecturas y el conocimiento de la capa de negocio (reglas, términos y procesos). El estándar permite el uso de un formato de datos común (XMI) que posibilita la correlación de las distintas capas de conocimiento del sistema para el análisis detallado (como la causa raíz, el impacto) o el análisis derivado (como la extracción de procesos de negocio). Aunque los esfuerzos para representar las construcciones del lenguaje pueden ser interminables debido al número de lenguajes, la continua evolución de los lenguajes de software y el desarrollo de nuevos lenguajes, el estándar permite el uso de extensiones para soportar el amplio conjunto de lenguajes, así como la evolución. KDM es compatible con UML, BPMN, RDF, y otros estándares permitiendo la migración a otros entornos y así aprovechar el conocimiento del sistema para esfuerzos como la transformación del sistema de software y el análisis de la capa de negocio de la empresa.
ProtocolosEditar
Los protocolos son conjuntos de reglas que describen los formatos de los mensajes y cómo se intercambian: la máquina de estado del protocolo. En consecuencia, el problema de la ingeniería inversa de protocolos puede dividirse en dos subproblemas: el formato de los mensajes y la ingeniería inversa de la máquina de estados.
Los formatos de los mensajes han sido tradicionalmente objeto de ingeniería inversa mediante un tedioso proceso manual, que implicaba el análisis de cómo las implementaciones de los protocolos procesan los mensajes, pero la investigación reciente ha propuesto una serie de soluciones automáticas. Normalmente, los enfoques automáticos agrupan los mensajes observados en clusters utilizando varios análisis de agrupación, o emulan la implementación del protocolo rastreando el procesamiento de los mensajes.
Ha habido menos trabajos sobre la ingeniería inversa de los estados-máquina de los protocolos. En general, las máquinas de estado de los protocolos pueden aprenderse a través de un proceso de aprendizaje fuera de línea, que observa pasivamente la comunicación e intenta construir la máquina de estado más general que acepte todas las secuencias de mensajes observadas, y el aprendizaje en línea, que permite la generación interactiva de secuencias de mensajes de sondeo y escuchar las respuestas a esas secuencias de sondeo. En general, se sabe que el aprendizaje offline de pequeñas máquinas de estado es NP-completo, pero el aprendizaje online puede realizarse en tiempo polinómico. Comparetti et al. han demostrado un enfoque automático fuera de línea y Cho et al. un enfoque en línea.
Otros componentes de los protocolos típicos, como las funciones de cifrado y de hash, también pueden ser objeto de ingeniería inversa automáticamente. Normalmente, los enfoques automáticos rastrean la ejecución de las implementaciones de los protocolos e intentan detectar los búferes en la memoria que contienen paquetes sin cifrar.
Circuitos integrados/tarjetas inteligentesEditar
La ingeniería inversa es una forma invasiva y destructiva de analizar una tarjeta inteligente. El atacante utiliza productos químicos para grabar capa tras capa de la tarjeta inteligente y toma fotografías con un microscopio electrónico de barrido (SEM). Esta técnica puede revelar toda la parte de hardware y software de la tarjeta inteligente. El mayor problema para el atacante es poner todo en orden para averiguar cómo funciona todo. Los fabricantes de la tarjeta intentan ocultar las claves y las operaciones mezclando las posiciones de la memoria, por ejemplo, mediante la codificación del bus.
En algunos casos, incluso es posible colocar una sonda para medir los voltajes mientras la tarjeta inteligente sigue funcionando. Los fabricantes de la tarjeta emplean sensores para detectar y prevenir ese ataque. Ese ataque no es muy común porque requiere tanto una gran inversión de esfuerzo como un equipo especial que generalmente sólo está disponible para los grandes fabricantes de chips. Además, la rentabilidad de este ataque es escasa, ya que se suelen utilizar otras técnicas de seguridad, como las cuentas en la sombra. Todavía no se sabe si los ataques contra las tarjetas con chip y PIN para replicar los datos de encriptación y luego descifrar los PINs proporcionarían un ataque rentable a la autenticación multifactor.
La ingeniería inversa completa procede en varios pasos principales.
El primer paso después de que se hayan tomado las imágenes con un SEM es coser las imágenes juntas, lo cual es necesario porque cada capa no puede ser capturada por una sola toma. Un MEB tiene que barrer el área del circuito y tomar varios cientos de imágenes para cubrir toda la capa. El cosido de imágenes toma como entrada varios cientos de imágenes y da como resultado una única imagen correctamente superpuesta de la capa completa.
A continuación, las capas cosidas deben alinearse porque la muestra, tras el grabado, no puede colocarse en la misma posición exacta con respecto al SEM cada vez. Por lo tanto, las versiones cosidas no se superpondrán de forma correcta, como en el circuito real. Por lo general, se seleccionan tres puntos correspondientes y se aplica una transformación a partir de ellos.
Para extraer la estructura del circuito, es necesario segmentar las imágenes alineadas y cosidas, lo que resalta los circuitos importantes y los separa del fondo y los materiales aislantes que no son interesantes.
Por último, se pueden rastrear los cables de una capa a otra, y reconstruir la lista de redes del circuito, que contiene toda la información del mismo.
Aplicaciones militaresEditar
La ingeniería inversa suele ser utilizada por personas para copiar tecnologías, dispositivos o información de otras naciones que han sido obtenidas por tropas regulares en el campo o por operaciones de inteligencia. Se utilizó a menudo durante la Segunda Guerra Mundial y la Guerra Fría. He aquí ejemplos conocidos de la Segunda Guerra Mundial y posteriores:
- Lata Jerry: Las fuerzas británicas y estadounidenses se dieron cuenta de que los alemanes tenían latas de gasolina con un excelente diseño. Hicieron ingeniería inversa de copias de esas latas, que se conocieron popularmente como «Jerry cans».
- Panzerschreck: Los alemanes capturaron un bazooka estadounidense durante la Segunda Guerra Mundial y le aplicaron ingeniería inversa para crear el Panzerschreck, de mayor tamaño.
- Tupolev Tu-4: en 1944, tres bombarderos B-29 estadounidenses que realizaban misiones sobre Japón se vieron obligados a aterrizar en la Unión Soviética. Los soviéticos, que no tenían un bombardero estratégico similar, decidieron copiar el B-29. En tres años, habían desarrollado el Tu-4, una copia casi perfecta.
- Radar SCR-584: copiado por la Unión Soviética tras la Segunda Guerra Mundial, es conocido por algunas modificaciones – СЦР-584, Бинокль-Д.
- Cohete V-2: Los documentos técnicos de la V-2 y las tecnologías relacionadas fueron capturados por los aliados occidentales al final de la guerra. Los estadounidenses centraron sus esfuerzos de ingeniería inversa a través de la Operación Paperclip, que condujo al desarrollo del cohete PGM-11 Redstone. Los soviéticos utilizaron a los ingenieros alemanes capturados para reproducir documentos y planos técnicos y trabajaron a partir del hardware capturado para hacer su clon del cohete, el R-1. Así comenzó el programa soviético de cohetes de posguerra, que condujo al R-7 y al inicio de la carrera espacial.
- El misil K-13/R-3S (nombre de informe de la OTAN AA-2 Atoll), una copia de ingeniería inversa soviética del AIM-9 Sidewinder, fue posible después de que un AIM-9B taiwanés alcanzara un MiG-17 chino sin explotar en septiembre de 1958. El misil quedó alojado en el fuselaje y el piloto regresó a la base con lo que los científicos soviéticos describirían como un curso universitario de desarrollo de misiles.
- Misil TOW BGM-71: en mayo de 1975, las negociaciones entre Irán y Hughes Missile Systems sobre la coproducción de los misiles TOW y Maverick se estancaron por desacuerdos en la estructura de precios, y la posterior revolución de 1979 puso fin a todos los planes de dicha coproducción. Más tarde, Irán consiguió aplicar la ingeniería inversa al misil y ahora produce su propia copia, el Toophan.
- China ha aplicado la ingeniería inversa a muchos ejemplos de hardware occidental y ruso, desde aviones de combate hasta misiles y vehículos de transporte de mercancías, como el MiG-15 (que se convirtió en el J-7) y el Su-33 (que se convirtió en el J-15). Análisis más recientes sobre el crecimiento militar de China han señalado las limitaciones inherentes a la ingeniería inversa para los sistemas de armas avanzados.
- Durante la Segunda Guerra Mundial, los criptógrafos polacos y británicos estudiaron las máquinas alemanas de cifrado de mensajes «Enigma» capturadas para detectar sus puntos débiles. A continuación, se simuló su funcionamiento en dispositivos electromecánicos, las «bombas, que probaron todas las posibles configuraciones del codificador de las máquinas «Enigma» que ayudaron a romper los mensajes codificados que habían sido enviados por los alemanes.
- También durante la Segunda Guerra Mundial, los científicos británicos analizaron y derrotaron una serie de sistemas de radionavegación cada vez más sofisticados utilizados por la Luftwaffe para realizar misiones de bombardeo guiadas por la noche. Las contramedidas británicas al sistema fueron tan efectivas que, en algunos casos, los aviones alemanes fueron guiados por señales para aterrizar en las bases de la RAF, ya que creían que habían regresado a territorio alemán.
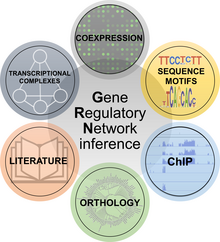
- Los métodos de coexpresión se basan en la noción de que si dos genes muestran un perfil de expresión similar, pueden estar relacionados aunque no se puede inferir simplemente una causalidad a partir de la coexpresión.
- Los métodos de motivos de secuencia analizan los promotores de los genes para encontrar dominios específicos de unión a factores de transcripción. Si se predice que un factor de transcripción se une a un promotor de un gen específico, se puede hipotetizar una conexión reguladora.
- Los métodos de inmunoprecipitación de cromatina (ChIP) investigan el perfil de unión al ADN de factores de transcripción elegidos en todo el genoma para inferir sus redes génicas descendentes.
- Los métodos de ortología transfieren el conocimiento de las redes génicas de una especie a otra.
- Los métodos literarios implementan la minería de textos y la investigación manual para identificar conexiones de redes génicas putativas o probadas experimentalmente.
- Los métodos de complejos transcripcionales aprovechan la información sobre las interacciones proteína-proteína entre los factores de transcripción, ampliando así el concepto de redes génicas para incluir los complejos reguladores transcripcionales.
Redes de genesEditar
Los conceptos de ingeniería inversa se han aplicado también a la biología, concretamente a la tarea de comprender la estructura y función de las redes reguladoras de genes. Éstas regulan casi todos los aspectos del comportamiento biológico y permiten a las células llevar a cabo procesos fisiológicos y respuestas a las perturbaciones. Entender la estructura y el comportamiento dinámico de las redes de genes es, por tanto, uno de los principales retos de la biología de sistemas, con repercusiones prácticas inmediatas en varias aplicaciones que van más allá de la investigación básica. Se han dividido generalmente en seis clases:
A menudo, la fiabilidad de las redes de genes se pone a prueba mediante experimentos de perturbación genética seguidos de una modelización dinámica, basada en el principio de que la eliminación de un nodo de la red tiene efectos predecibles en el funcionamiento de los nodos restantes de la red.Las aplicaciones de la ingeniería inversa de las redes de genes van desde la comprensión de los mecanismos de la fisiología de las plantas hasta la puesta de manifiesto de nuevas dianas para la terapia contra el cáncer.
Solapamiento con el derecho de patentesEditar
La ingeniería inversa se aplica principalmente a la obtención de la comprensión de un proceso o artefacto en el que la forma de su construcción, uso o procesos internos no ha sido aclarada por su creador.
Los artículos patentados no tienen que ser en sí mismos objeto de ingeniería inversa para ser estudiados, ya que la esencia de una patente es que los inventores proporcionen una divulgación pública detallada ellos mismos, y a cambio reciban la protección legal de la invención que se trate. Sin embargo, un artículo producido en virtud de una o varias patentes también podría incluir otra tecnología no patentada y no divulgada. De hecho, una motivación común de la ingeniería inversa es determinar si el producto de un competidor contiene una infracción de patente o de derechos de autor.