Reverse engineering
MachinesEdit
Come la progettazione assistita dal computer (CAD) è diventata più popolare, il reverse engineering è diventato un metodo valido per creare un modello virtuale 3D di una parte fisica esistente da usare in CAD 3D, CAM, CAE, o altri software. Il processo di reverse engineering comporta la misurazione di un oggetto e la sua ricostruzione in un modello 3D. L’oggetto fisico può essere misurato usando tecnologie di scansione 3D come CMM, scanner laser, digitalizzatori a luce strutturata o scansione CT (tomografia computerizzata) industriale. I soli dati misurati, solitamente rappresentati come una nuvola di punti, mancano di informazioni topologiche e dell’intento progettuale. Le prime possono essere recuperate convertendo la nuvola di punti in una mesh a facce triangolari. L’ingegneria inversa mira ad andare oltre la produzione di una tale mesh e a recuperare l’intento progettuale in termini di semplici superfici analitiche dove appropriato (piani, cilindri, ecc.) e possibilmente superfici NURBS per produrre un modello CAD con rappresentazione dei confini. Il recupero di un tale modello permette di modificare un progetto per soddisfare nuovi requisiti, di generare un piano di produzione, ecc.
La modellazione ibrida è un termine comunemente usato quando NURBS e la modellazione parametrica sono implementate insieme. Usare una combinazione di superfici geometriche e a forma libera può fornire un potente metodo di modellazione 3D. Aree di dati a forma libera possono essere combinate con superfici geometriche esatte per creare un modello ibrido. Un tipico esempio di questo sarebbe il reverse engineering di una testa di cilindro, che include caratteristiche di fusione a forma libera, come le camicie d’acqua e le aree lavorate ad alta tolleranza.
Il reverse engineering è anche usato dalle aziende per portare la geometria fisica esistente in ambienti digitali di sviluppo del prodotto, per fare un record digitale 3D dei loro prodotti, o per valutare i prodotti della concorrenza. Si usa per analizzare come funziona un prodotto, cosa fa, quali componenti ha; stimare i costi; identificare potenziali violazioni di brevetti; ecc.
Value engineering, un’attività correlata che è anche usata dalle aziende, comporta la decostruzione e l’analisi dei prodotti. Tuttavia, l’obiettivo è quello di trovare opportunità per la riduzione dei costi.
SoftwareEdit
Nel 1990, l’Institute of Electrical and Electronics Engineers (IEEE) ha definito (software) reverse engineering (SRE) come “il processo di analisi di un sistema soggetto per identificare i componenti del sistema e le loro interrelazioni e per creare rappresentazioni del sistema in un’altra forma o ad un livello superiore di astrazione” in cui il “sistema soggetto” è il prodotto finale dello sviluppo del software. Il reverse engineering è un processo di solo esame, e il sistema software in esame non viene modificato, il che sarebbe altrimenti un re-engineering o una ristrutturazione. Il reverse engineering può essere eseguito da qualsiasi fase del ciclo del prodotto, non necessariamente dal prodotto finale funzionale.
Ci sono due componenti nel reverse engineering: ridocumentazione e recupero del design. La ridocumentazione è la creazione di una nuova rappresentazione del codice informatico in modo che sia più facile da capire. Nel frattempo, il recupero del design è l’uso della deduzione o del ragionamento dalla conoscenza generale o dall’esperienza personale del prodotto per comprendere pienamente la funzionalità del prodotto. Può anche essere visto come “andare all’indietro attraverso il ciclo di sviluppo”. In questo modello, l’output della fase di implementazione (in forma di codice sorgente) è invertito nella fase di analisi, in un’inversione del tradizionale modello a cascata. Un altro termine per questa tecnica è comprensione del programma. La Working Conference on Reverse Engineering (WCRE) è stata tenuta annualmente per esplorare ed espandere le tecniche di reverse engineering. L’ingegneria del software assistita dal computer (CASE) e la generazione automatica del codice hanno contribuito notevolmente nel campo del reverse engineering.
La tecnologia anti-tamper software come l’offuscamento è usata per scoraggiare sia il reverse engineering che la reingegnerizzazione del software proprietario e dei sistemi alimentati da software. In pratica, emergono due tipi principali di reverse engineering. Nel primo caso, il codice sorgente è già disponibile per il software, ma vengono scoperti aspetti di livello superiore del programma, che sono forse scarsamente documentati o documentati ma non più validi. Nel secondo caso, non c’è codice sorgente disponibile per il software, e qualsiasi sforzo per scoprire un possibile codice sorgente per il software è considerato ingegneria inversa. Il secondo uso del termine è più familiare alla maggior parte delle persone. L’ingegneria inversa del software può fare uso della tecnica di progettazione in camera bianca per evitare la violazione del copyright.
Su una nota correlata, il test della scatola nera nell’ingegneria del software ha molto in comune con l’ingegneria inversa. Il tester di solito ha l’API ma ha l’obiettivo di trovare bug e caratteristiche non documentate distruggendo il prodotto dall’esterno.
Altri scopi del reverse engineering includono la verifica della sicurezza, la rimozione della protezione della copia (“cracking”), l’aggiramento delle restrizioni di accesso spesso presenti nell’elettronica di consumo, la personalizzazione dei sistemi incorporati (come i sistemi di gestione del motore), le riparazioni o i retrofit interni, l’abilitazione di funzioni aggiuntive su hardware “storpiato” a basso costo (come alcuni chipset di schede grafiche), o anche la semplice soddisfazione della curiosità.
Modifica del software binario
Il reverse engineering binario viene eseguito se il codice sorgente di un software non è disponibile. Questo processo è talvolta chiamato reverse code engineering, o RCE. Per esempio, la decompilazione dei binari per la piattaforma Java può essere realizzata utilizzando Jad. Un caso famoso di ingegneria inversa è stata la prima implementazione non-IBM del BIOS del PC, che ha lanciato la storica industria IBM PC compatibile che è stata la piattaforma hardware dominante per molti anni. Il reverse engineering del software è protetto negli Stati Uniti dall’eccezione del fair use nella legge sul copyright. Il software Samba, che permette a sistemi che non eseguono Microsoft Windows di condividere file con sistemi che lo eseguono, è un classico esempio di ingegneria inversa del software, poiché il progetto Samba ha dovuto reingegnerizzare informazioni inedite su come funzionava la condivisione di file di Windows in modo che i computer non Windows potessero emularla. Il progetto Wine fa la stessa cosa per le API di Windows, e OpenOffice.org è una parte che lo fa per i formati di file di Microsoft Office. Il progetto ReactOS è ancora più ambizioso nei suoi obiettivi, sforzandosi di fornire compatibilità binaria (ABI e API) con gli attuali sistemi operativi Windows del ramo NT, il che permette al software e ai driver scritti per Windows di funzionare su una controparte di software libero (GPL) in camera bianca. WindowsSCOPE permette il reverse-engineering dell’intero contenuto della memoria live di un sistema Windows, incluso un reverse engineering grafico a livello binario di tutti i processi in esecuzione.
Un altro esempio classico, anche se non molto conosciuto, è che nel 1987 i Bell Laboratories hanno fatto il reverse-engineering del Mac OS System 4.1, originariamente in esecuzione sull’Apple Macintosh SE, in modo da poterlo eseguire sulle loro macchine RISC.
Tecniche di software binarioModifica
L’ingegneria inversa del software può essere realizzata con vari metodi.I tre gruppi principali di ingegneria inversa del software sono
- Analisi attraverso l’osservazione dello scambio di informazioni, più prevalente nell’ingegneria inversa del protocollo, che comporta l’uso di analizzatori di bus e sniffer di pacchetti, come per accedere a un bus di computer o a una connessione di rete di computer e rivelare i dati sul traffico. Il comportamento del bus o della rete può quindi essere analizzato per produrre un’implementazione autonoma che imita quel comportamento. Questo è particolarmente utile per il reverse engineering dei driver dei dispositivi. A volte, il reverse engineering sui sistemi embedded è notevolmente assistito da strumenti deliberatamente introdotti dal produttore, come le porte JTAG o altri mezzi di debug. In Microsoft Windows, i debugger di basso livello come SoftICE sono popolari.
- Disassemblare usando un disassemblatore, il che significa che il linguaggio macchina grezzo del programma viene letto e compreso nei suoi stessi termini, solo con l’aiuto di mnemotecniche del linguaggio macchina. Funziona su qualsiasi programma per computer, ma può richiedere un po’ di tempo, soprattutto per coloro che non sono abituati al codice macchina. L’Interactive Disassembler è uno strumento particolarmente popolare.
- Decompilazione utilizzando un decompilatore, un processo che cerca, con risultati variabili, di ricreare il codice sorgente in qualche linguaggio di alto livello per un programma disponibile solo in codice macchina o bytecode.
Classificazione del softwareModifica
La classificazione del software è il processo di identificazione delle somiglianze tra diversi binari di software (come due versioni diverse dello stesso binario) utilizzato per rilevare le relazioni di codice tra campioni di software. Il compito è stato tradizionalmente svolto manualmente per diverse ragioni (come l’analisi delle patch per il rilevamento delle vulnerabilità e la violazione del copyright), ma ora può essere fatto in qualche modo automaticamente per un gran numero di campioni.
Questo metodo viene utilizzato soprattutto per compiti di reverse engineering lunghi e approfonditi (analisi completa di un algoritmo complesso o un grande pezzo di software). In generale, la classificazione statistica è considerata un problema difficile, che è anche vero per la classificazione del software, e così poche soluzioni/strumenti che gestiscono bene questo compito.
Source codeEdit
Un certo numero di strumenti UML si riferisce al processo di importazione e analisi del codice sorgente per generare diagrammi UML come “reverse engineering”. Vedi Elenco degli strumenti UML.
Anche se UML è un approccio per fornire “reverse engineering”, più recenti progressi nelle attività di standard internazionali hanno portato allo sviluppo del Knowledge Discovery Metamodel (KDM). Lo standard fornisce un’ontologia per la rappresentazione intermedia (o astratta) dei costrutti del linguaggio di programmazione e le loro interrelazioni. Uno standard dell’Object Management Group (in procinto di diventare anche uno standard ISO), KDM ha iniziato a prendere piede nell’industria con lo sviluppo di strumenti e ambienti di analisi che possono fornire l’estrazione e l’analisi di codice sorgente, binario e byte. Per l’analisi del codice sorgente, l’architettura granulare degli standard KDM permette l’estrazione dei flussi del sistema software (dati, controllo e mappe delle chiamate), architetture e conoscenza del livello di business (regole, termini e processi). Lo standard permette l’uso di un formato di dati comune (XMI) che consente la correlazione dei vari strati di conoscenza del sistema per l’analisi dettagliata (come la causa principale, l’impatto) o l’analisi derivata (come l’estrazione del processo di business). Anche se gli sforzi per rappresentare i costrutti del linguaggio possono essere infiniti a causa del numero di linguaggi, la continua evoluzione dei linguaggi software e lo sviluppo di nuovi linguaggi, lo standard permette l’uso di estensioni per supportare l’ampio set di linguaggi e l’evoluzione. KDM è compatibile con UML, BPMN, RDF, e altri standard che permettono la migrazione in altri ambienti e quindi di sfruttare la conoscenza del sistema per sforzi come la trasformazione del sistema software e l’analisi del livello di business aziendale.
ProtocolliModifica
I protocolli sono insiemi di regole che descrivono i formati dei messaggi e come i messaggi vengono scambiati: la macchina a stati del protocollo. Di conseguenza, il problema del reverse-engineering dei protocolli può essere suddiviso in due sottoproblemi: il formato dei messaggi e il reverse-engineering della macchina a stati.
I formati dei messaggi sono stati tradizionalmente sottoposti a reverse-engineering attraverso un noioso processo manuale, che implicava l’analisi di come le implementazioni del protocollo elaborano i messaggi, ma la ricerca recente ha proposto una serie di soluzioni automatiche. Tipicamente, gli approcci automatici raggruppano i messaggi osservati in cluster usando varie analisi di clustering, o emulano l’implementazione del protocollo tracciando l’elaborazione dei messaggi.
C’è stato meno lavoro sul reverse-engineering delle state-machine dei protocolli. In generale, le state-machine dei protocolli possono essere apprese sia attraverso un processo di apprendimento offline, che osserva passivamente la comunicazione e tenta di costruire la state-machine più generale accettando tutte le sequenze di messaggi osservate, sia attraverso l’apprendimento online, che permette la generazione interattiva di sequenze di messaggi di prova e l’ascolto delle risposte a tali sequenze di prova. In generale, l’apprendimento offline di piccole state-machine è noto per essere NP-completo, ma l’apprendimento online può essere fatto in tempo polinomiale. Un approccio automatico offline è stato dimostrato da Comparetti et al. e un approccio online da Cho et al.
Anche altri componenti di protocolli tipici, come la crittografia e le funzioni di hash, possono essere sottoposti a reverse engineering automatico. Tipicamente, gli approcci automatici tracciano l’esecuzione delle implementazioni del protocollo e cercano di individuare i buffer in memoria che contengono pacchetti non crittografati.
Circuiti integrati/smart cardModifica
La reverse engineering è una forma invasiva e distruttiva di analisi di una smart card. L’attaccante usa prodotti chimici per incidere strato dopo strato della smart card e scatta foto con un microscopio elettronico a scansione (SEM). Questa tecnica può rivelare l’intera parte hardware e software della smart card. Il problema principale per l’attaccante è quello di mettere tutto nel giusto ordine per scoprire come tutto funziona. I fabbricanti della carta cercano di nascondere le chiavi e le operazioni mischiando le posizioni della memoria, ad esempio con lo scrambling del bus.
In alcuni casi, è anche possibile attaccare una sonda per misurare le tensioni mentre la smart card è ancora operativa. I produttori della carta impiegano sensori per rilevare e prevenire questo attacco. Questo attacco non è molto comune perché richiede sia un grande investimento in sforzi che attrezzature speciali che sono generalmente disponibili solo per i grandi produttori di chip. Inoltre, il profitto di questo attacco è basso poiché altre tecniche di sicurezza sono spesso usate come i conti ombra. È ancora incerto se gli attacchi contro le carte chip-and-PIN per replicare i dati di crittografia e poi per crackare i PIN possano fornire un attacco conveniente all’autenticazione multifattoriale.
Il reverse engineering completo procede in diversi passi principali.
Il primo passo dopo che le immagini sono state scattate con un SEM è la cucitura delle immagini insieme, che è necessaria perché ogni strato non può essere catturato da un singolo scatto. Un SEM deve spaziare attraverso l’area del circuito e prendere diverse centinaia di immagini per coprire l’intero strato. La cucitura delle immagini prende come input diverse centinaia di immagini e produce una singola immagine correttamente sovrapposta dello strato completo.
In seguito, gli strati cuciti devono essere allineati perché il campione, dopo l’incisione, non può essere messo ogni volta nella stessa posizione rispetto al SEM. Di conseguenza, le versioni cucite non si sovrappongono in modo corretto, come sul circuito reale. Di solito, si selezionano tre punti corrispondenti e si applica una trasformazione sulla base di questi.
Per estrarre la struttura del circuito, le immagini allineate e cucite devono essere segmentate, il che evidenzia i circuiti importanti e li separa dallo sfondo non interessante e dai materiali isolanti.
Infine, i fili possono essere tracciati da uno strato all’altro, e la netlist del circuito, che contiene tutte le informazioni del circuito, può essere ricostruita.
Applicazioni militariModifica
L’ingegneria inversa è spesso usata da persone per copiare tecnologie, dispositivi o informazioni di altre nazioni che sono state ottenute dalle truppe regolari sui campi o da operazioni di intelligence. È stato spesso usato durante la seconda guerra mondiale e la guerra fredda. Ecco esempi noti della seconda guerra mondiale e successive:
- Jerry can: Le forze britanniche e americane notarono che i tedeschi avevano taniche di benzina con un design eccellente. Realizzarono delle copie di quelle taniche, che furono popolarmente conosciute come “Jerry cans.”
- Panzerschreck: I tedeschi catturarono un bazooka americano durante la seconda guerra mondiale e lo reingegnerizzarono per creare il più grande Panzerschreck.
- Tupolev Tu-4: Nel 1944, tre bombardieri americani B-29 in missione sul Giappone furono costretti ad atterrare in Unione Sovietica. I sovietici, che non avevano un bombardiere strategico simile, decisero di copiare il B-29. In tre anni, avevano sviluppato il Tu-4, una copia quasi perfetta.
- Radar SCR-584: copiato dall’Unione Sovietica dopo la seconda guerra mondiale, è noto per alcune modifiche – СЦР-584, Бинокль-Д.
- Razzo V-2: I documenti tecnici per il V-2 e le tecnologie correlate furono catturati dagli alleati occidentali alla fine della guerra. Gli americani concentrarono i loro sforzi di reverse engineering attraverso l’operazione Paperclip, che portò allo sviluppo del razzo PGM-11 Redstone. I sovietici usarono gli ingegneri tedeschi catturati per riprodurre documenti tecnici e piani e lavorarono con l’hardware catturato per fare il loro clone del razzo, l’R-1. Così iniziò il programma di razzi sovietici del dopoguerra, che portò all’R-7 e all’inizio della corsa allo spazio.
- Il missile K-13/R-3S (nome di segnalazione NATO AA-2 Atoll), una copia sovietica reingegnerizzata dell’AIM-9 Sidewinder, fu reso possibile dopo che un AIM-9B di Taiwan colpì un MiG-17 cinese senza esplodere nel settembre 1958. Il missile si incastrò nella cellula, e il pilota tornò alla base con quello che gli scienziati sovietici avrebbero descritto come un corso universitario nello sviluppo di missili.
- Missile BGM-71 TOW: Nel maggio 1975, i negoziati tra l’Iran e Hughes Missile Systems sulla co-produzione dei missili TOW e Maverick si bloccarono per disaccordi nella struttura dei prezzi, la successiva rivoluzione del 1979 mise fine a tutti i piani per tale co-produzione. L’Iran è riuscito in seguito a fare il reverse engineering del missile e ora produce la propria copia, il Toophan.
- La Cina ha fatto il reverse engineering di molti esempi di hardware occidentale e russo, dagli aerei da combattimento ai missili e alle auto HMMWV, come il MiG-15 (che è diventato il J-7) e il Su-33 (che è diventato il J-15). Analisi più recenti della crescita militare della Cina hanno sottolineato i limiti intrinseci del reverse engineering per i sistemi d’arma avanzati.
- Durante la seconda guerra mondiale, i crittografi polacchi e britannici hanno studiato le macchine tedesche catturate per la crittografia dei messaggi “Enigma” alla ricerca di punti deboli. Il loro funzionamento è stato poi simulato su dispositivi elettromeccanici, “bombe”, che hanno provato tutte le possibili impostazioni di scrambler delle macchine “Enigma” che hanno aiutato la rottura dei messaggi in codice che erano stati inviati dai tedeschi.
- Anche durante la seconda guerra mondiale, gli scienziati britannici hanno analizzato e sconfitto una serie di sistemi di navigazione radio sempre più sofisticati utilizzati dalla Luftwaffe per eseguire missioni di bombardamento guidate di notte. Le contromisure britanniche al sistema furono così efficaci che in alcuni casi, gli aerei tedeschi furono indotti dai segnali ad atterrare nelle basi RAF poiché credevano di essere tornati in territorio tedesco.
Reti genicheModifica
I concetti di ingegneria inversa sono stati applicati anche alla biologia, in particolare al compito di comprendere la struttura e la funzione delle reti di regolazione genica. Esse regolano quasi ogni aspetto del comportamento biologico e permettono alle cellule di eseguire processi fisiologici e risposte alle perturbazioni. Comprendere la struttura e il comportamento dinamico delle reti geniche è quindi una delle sfide più importanti della biologia dei sistemi, con immediate ripercussioni pratiche in diverse applicazioni che vanno oltre la ricerca di base.Ci sono diversi metodi per il reverse engineering delle reti di regolazione genica utilizzando metodi di biologia molecolare e di scienza dei dati. Sono stati generalmente divisi in sei classi:
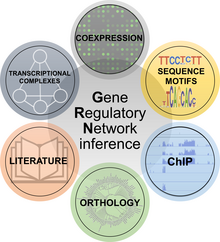
- I metodi di coespressione si basano sulla nozione che se due geni mostrano un profilo di espressione simile, possono essere correlati anche se nessuna causalità può essere semplicemente dedotta dalla coespressione.
- I metodi dei motivi di sequenza analizzano i promotori dei geni per trovare specifici domini di legame dei fattori di trascrizione. Se si prevede che un fattore di trascrizione leghi un promotore di un gene specifico, si può ipotizzare una connessione normativa.
- I metodi di ImmunoPrecipitazione della Cromatina (ChIP) indagano il profilo genomico del legame al DNA di fattori di trascrizione scelti per dedurre le loro reti geniche a valle.
- I metodi di ortologia trasferiscono la conoscenza della rete genica da una specie all’altra.
- I metodi letterari implementano il text mining e la ricerca manuale per identificare connessioni di reti geniche putative o sperimentalmente provate.
- I metodi dei complessi trascrizionali sfruttano le informazioni sulle interazioni proteina-proteina tra i fattori di trascrizione, estendendo così il concetto di reti geniche per includere complessi di regolazione trascrizionale.
Spesso, l’affidabilità delle reti geniche viene testata tramite esperimenti di perturbazione genetica seguiti da una modellazione dinamica, basata sul principio che la rimozione di un nodo della rete ha effetti prevedibili sul funzionamento dei restanti nodi della rete.Le applicazioni del reverse engineering delle reti geniche vanno dalla comprensione dei meccanismi della fisiologia delle piante all’evidenziazione di nuovi obiettivi per la terapia anticancro.
Sovrapposizione con il diritto dei brevettiModifica
L’ingegneria inversa si applica principalmente per ottenere la comprensione di un processo o di un artefatto in cui il modo della sua costruzione, uso, o processi interni non è stato reso chiaro dal suo creatore.
Gli oggetti brevettati non devono di per sé essere sottoposti a ingegneria inversa per essere studiati, perché l’essenza di un brevetto è che gli inventori stessi forniscono una divulgazione pubblica dettagliata, e in cambio ricevono la protezione legale dell’invenzione che è coinvolto. Tuttavia, un oggetto prodotto sotto uno o più brevetti potrebbe anche includere altra tecnologia che non è brevettata e non divulgata. Infatti, una motivazione comune del reverse engineering è quella di determinare se il prodotto di un concorrente contiene una violazione del brevetto o del copyright.