Apache Spark: Resilient Distributed Datasets
RDD rappresentano sia l’idea di come un grande set di dati è rappresentato in Apache Spark che l’astrazione per lavorare con esso. Questa sezione coprirà il primo aspetto, e le sezioni seguenti copriranno il secondo. Secondo il documento seminale su Spark, “gli RDD sono strutture di dati immutabili, tolleranti agli errori e parallele che permettono agli utenti di persistere esplicitamente i risultati intermedi in memoria, controllare il loro partizionamento per ottimizzare il posizionamento dei dati, e manipolarli utilizzando un ricco set di operatori”. Sezioniamo questa descrizione per capire veramente le idee dietro il concetto di RDD.
Immutabile
Gli RDD sono progettati per essere immutabili, il che significa che non è possibile modificare specificamente una particolare riga nel dataset rappresentato da quell’RDD. Potete chiamare una delle operazioni RDD disponibili per manipolare le righe nell’RDD nel modo che desiderate, ma questa operazione restituirà un nuovo RDD. L’RDD di base rimarrà invariato, e il nuovo RDD conterrà i dati nel modo in cui li avete alterati. L’immutabilità richiede che un RDD porti con sé le sue informazioni di discendenza che Spark sfrutta per fornire in modo efficiente capacità di tolleranza agli errori.
Tollerante agli errori
La capacità di elaborare più set di dati in parallelo richiede solitamente un cluster di macchine per ospitare ed eseguire la logica computazionale. Se una o più di queste macchine muore o diventa estremamente lenta a causa di circostanze impreviste, allora come influenzerà l’elaborazione complessiva dei dati di quei set di dati? La buona notizia è che Spark si occupa automaticamente di gestire il fallimento per conto dei suoi utenti, ricostruendo la parte fallita utilizzando le informazioni di lineage.
Strutture di dati parallele
Immaginate il caso in cui qualcuno vi dia un grande file di log di 1TB e vi venga chiesto di scoprire quante dichiarazioni di log contengono la parola “eccezione”. Una soluzione lenta sarebbe quella di iterare il file di log dall’inizio alla fine ed eseguire la logica per determinare se una particolare istruzione di log contiene la parola eccezione. Una soluzione più veloce sarebbe quella di dividere quel file da 1TB in diversi chunk ed eseguire la suddetta logica su ogni chunk in modo parallelizzato per accelerare il tempo complessivo di elaborazione. Ogni chunk contiene una collezione di righe. La collezione di righe è essenzialmente la struttura di dati che contiene un insieme di righe e fornisce la possibilità di iterare attraverso ogni riga. Ogni chunk contiene una collezione di righe, e tutti i chunk vengono elaborati in parallelo. È da qui che deriva la frase strutture di dati parallele.
In-Memory Computing
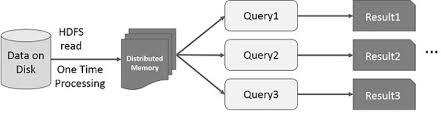
L’idea di accelerare il calcolo di grandi insiemi di dati che risiedono sui dischi in modo parallelizzato usando un cluster di macchine è stata introdotta da un documento MapReduce2 di Google. Questa idea è stata implementata e resa disponibile nel progetto open source Hadoop. Basandosi su questa solida base, RDD spinge il confine della velocità introducendo la possibilità di fare calcoli distribuiti in-memoria.
È sempre affascinante esaminare le storie che hanno portato alla creazione di un’idea innovativa. Nel mondo dell’elaborazione dei big data, una volta che si è in grado di estrarre intuizioni da grandi insiemi di dati in modo affidabile utilizzando un insieme di tecniche rudimentali, si desidera utilizzare tecniche più sofisticate per ridurre la quantità di tempo necessario per farlo. È qui che il calcolo distribuito in-memoria aiuta.
La tecnica sofisticata a cui mi riferisco è l’uso dell’apprendimento automatico per eseguire varie previsioni o per estrarre modelli da grandi serie di dati. Gli algoritmi di apprendimento automatico sono di natura iterativa, il che significa che hanno bisogno di passare attraverso molte iterazioni per arrivare a uno stato ottimale. È qui che il calcolo in-memoria distribuito può aiutare a ridurre il tempo di completamento da giorni a ore. Un altro caso d’uso che può beneficiare enormemente del calcolo in-memoria distribuito è il data mining interattivo, dove più query ad hoc vengono eseguite sullo stesso sottoinsieme di dati. Se quel sottoinsieme di dati viene conservato in memoria, queste query impiegheranno secondi e non minuti per essere completate.