Apache Spark: Resilient Distributed Datasets
RDD reprezentują zarówno ideę tego, jak duży zbiór danych jest reprezentowany w Apache Spark, jak i abstrakcję do pracy z nim. W tej sekcji zajmiemy się tym pierwszym, a w kolejnych sekcjach zajmiemy się tym drugim. Zgodnie z dokumentem opisującym Sparka, „RDD są niezmiennymi, odpornymi na błędy, równoległymi strukturami danych, które pozwalają użytkownikom na jawne przechowywanie pośrednich wyników w pamięci, kontrolowanie ich partycjonowania w celu optymalizacji rozmieszczenia danych oraz manipulowanie nimi za pomocą bogatego zestawu operatorów.” Przeanalizujmy ten opis, aby naprawdę zrozumieć idee stojące za koncepcją RDD.
Immutable
RDD są zaprojektowane jako niezmienne, co oznacza, że nie można konkretnie modyfikować konkretnego wiersza w zbiorze danych reprezentowanym przez to RDD. Możesz wywołać jedną z dostępnych operacji na RDD, aby zmodyfikować wiersze w RDD w sposób, który chcesz, ale ta operacja zwróci nowy RDD. Podstawowy RDD pozostanie niezmieniony, a nowy RDD będzie zawierał dane w sposób, w jaki je zmieniłeś. Niezmienność wymaga, aby RDD posiadały informacje o swoim pochodzeniu, które Spark wykorzystuje do efektywnego zapewnienia odporności na błędy.
Tolerancja na błędy
Możliwość równoległego przetwarzania wielu zbiorów danych wymaga zazwyczaj klastra maszyn do hostowania i wykonywania logiki obliczeniowej. Jeśli jedna lub więcej z tych maszyn umrze lub stanie się wyjątkowo powolna z powodu nieoczekiwanych okoliczności, to jak to wpłynie na ogólne przetwarzanie danych z tych zbiorów? Dobrą wiadomością jest to, że Spark automatycznie zajmie się obsługą awarii w imieniu swoich użytkowników, odbudowując uszkodzoną część przy użyciu informacji o pochodzeniu.
Równoległe struktury danych
Wyobraź sobie przypadek użycia, w którym ktoś daje ci duży plik dziennika o rozmiarze 1TB, a ty masz dowiedzieć się, ile oświadczeń dziennika zawiera słowo „wyjątek”. Wolnym rozwiązaniem byłoby iterowanie przez ten plik dziennika od początku do końca i wykonanie logiki określającej, czy dane oświadczenie dziennika zawiera słowo wyjątek. Szybszym rozwiązaniem byłoby podzielenie pliku o rozmiarze 1 TB na kilka kawałków i wykonanie wspomnianej logiki na każdym z nich w sposób równoległy, aby przyspieszyć ogólny czas przetwarzania. Każdy fragment zawiera kolekcję wierszy. Kolekcja wierszy jest zasadniczo strukturą danych, która przechowuje zestaw wierszy i zapewnia możliwość iteracji przez każdy wiersz. Każdy chunk zawiera kolekcję wierszy, a wszystkie chunki są przetwarzane równolegle. Stąd właśnie pochodzi wyrażenie równoległe struktury danych.
In-Memory Computing
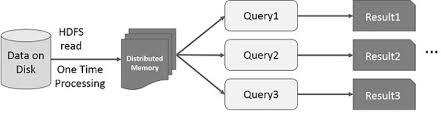
Pomysł przyspieszenia obliczeń dużych zbiorów danych, które rezydują na dyskach w sposób równoległy przy użyciu klastra maszyn został wprowadzony przez MapReduce paper2 z Google. Pomysł ten został zaimplementowany i udostępniony w projekcie open source Hadoop. Bazując na tym solidnym fundamencie, RDD przesuwa granicę prędkości wprowadzając możliwość wykonywania rozproszonych obliczeń in-memory.
Zawsze fascynujące jest badanie historii, które doprowadziły do powstania innowacyjnego pomysłu. W świecie przetwarzania big data, gdy już jesteś w stanie wydobyć wnioski z dużych zbiorów danych w niezawodny sposób, używając zestawu podstawowych technik, chcesz użyć bardziej zaawansowanych technik, aby skrócić czas potrzebny na wykonanie tego zadania. W tym właśnie pomagają rozproszone obliczenia in-memory.
Wyrafinowana technika, o której mówię, to wykorzystanie uczenia maszynowego do wykonywania różnych przewidywań lub do wydobywania wzorców z dużych zbiorów danych. Algorytmy uczenia maszynowego są z natury iteracyjne, co oznacza, że muszą przejść przez wiele iteracji, aby dojść do optymalnego stanu. To właśnie tutaj rozproszone obliczenia in-memory mogą pomóc w skróceniu czasu realizacji z dni do godzin. Innym przypadkiem użycia, który może ogromnie skorzystać z rozproszonych obliczeń in-memory, jest interaktywna eksploracja danych, gdzie wiele zapytań ad hoc jest wykonywanych na tym samym podzbiorze danych. Jeśli ten podzbiór danych jest przechowywany w pamięci, wykonanie tych zapytań zajmie sekundy, a nie minuty.