Boolean World

Polecenie Top pozwala użytkownikom monitorować procesy i wykorzystanie zasobów systemowych w Linuksie. Jest to jedno z najbardziej użytecznych narzędzi w przyborniku administratora, i jest ono preinstalowane w każdej dystrybucji. W przeciwieństwie do innych poleceń takich jak ps, jest interaktywny, i możesz przeglądać listę procesów, zabić proces, i tak dalej.
W tym artykule, zamierzamy zrozumieć jak używać polecenia top.
Rozpoczęcie
Jak już pewnie się domyśliłeś, aby uruchomić top wystarczy wpisać to:
top
To uruchamia interaktywną aplikację wiersza poleceń, podobną do tej na poniższym zrzucie ekranu. Górna połowa wyjścia zawiera statystyki dotyczące procesów i wykorzystania zasobów, podczas gdy dolna połowa zawiera listę aktualnie uruchomionych procesów. Listę można przeglądać za pomocą klawiszy strzałek oraz klawiszy Page Up/Down. Aby zakończyć pracę, wystarczy nacisnąć klawisz „q”.
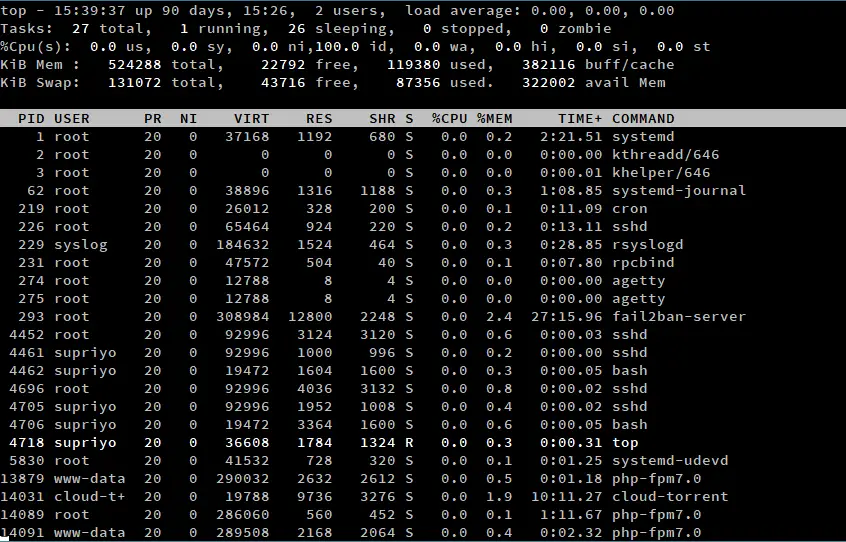
Istnieje wiele wariantów top, ale w dalszej części artykułu zajmiemy się najczęściej spotykanym – tym, który jest dostarczany z pakietem „procps-ng”. Możesz to zweryfikować uruchamiając:
top -v
Jeśli masz ten wariant, pojawi się to na wyjściu, tak jak poniżej:
procps-ng version 3.3.10
W interfejsie top’a dzieje się całkiem sporo, więc rozłożymy go kawałek po kawałku w następnej sekcji.
Zrozumienie interfejsu top’a: obszar podsumowania
Jak widzieliśmy wcześniej, wyjście top’a jest podzielone na dwie różne sekcje. W tej części artykułu, skupimy się na elementach znajdujących się w połowie wyjścia. Ten obszar nazywany jest również „obszarem podsumowania”.
Czas pracy systemu, czas pracy i sesje użytkowników

Na samej górze po lewej stronie ekranu (jak zaznaczono na powyższym zrzucie ekranu), top wyświetla aktualny czas. Następnie wyświetlany jest czas działania systemu, który informuje nas o czasie, przez jaki system był uruchomiony. Na przykład, w naszym przykładzie, aktualny czas to „15:39:37”, a system działa od 90 dni, 15 godzin i 26 minut.
Następnie wyświetlana jest liczba aktywnych sesji użytkownika. W tym przykładzie istnieją dwie aktywne sesje użytkownika. Sesje te mogą być wykonane albo na TTY (fizycznie w systemie, poprzez wiersz poleceń lub środowisko graficzne) lub na PTY (np. w oknie emulatora terminala lub przez SSH). W rzeczywistości, jeśli zalogujesz się do systemu Linux poprzez środowisko pulpitu, a następnie uruchomisz emulator terminala, okaże się, że będą dwie aktywne sesje.
Jeśli chcesz uzyskać więcej szczegółów na temat aktywnych sesji użytkownika, użyj polecenia who.
Użycie pamięci

Sekcja „memory” przedstawia informacje dotyczące wykorzystania pamięci przez system. Linie oznaczone jako „Mem” i „Swap” pokazują informacje odpowiednio o pamięci RAM i przestrzeni wymiany. Mówiąc najprościej, przestrzeń wymiany to część dysku twardego, która jest używana jak pamięć RAM. Kiedy pamięć RAM jest prawie pełna, rzadko używane obszary pamięci RAM są zapisywane w przestrzeni wymiany, gotowe do odzyskania później, gdy zajdzie taka potrzeba. Jednakże, ponieważ dostęp do dysków jest wolny, zbytnie poleganie na swapowaniu może zaszkodzić wydajności systemu.
Jak można się spodziewać, wartości „total”, „free” i „used” mają swoje zwykłe znaczenie. Wartość „avail mem” jest ilością pamięci, która może być przydzielona procesom bez powodowania większej ilości swapów.
Jądro Linuksa próbuje również zredukować czas dostępu do dysku na różne sposoby. Utrzymuje „pamięć podręczną dysku” w RAM, gdzie przechowywane są często używane regiony dysku. Dodatkowo, zapisy na dysku są przechowywane w „buforze dysku”, a jądro ostatecznie zapisuje je na dysku. Całkowita pamięć zużywana przez te elementy to wartość „buff/cache”. Może się to wydawać złe, ale tak nie jest – pamięć używana przez bufor zostanie przydzielona procesom w razie potrzeby.
Zadania

Sekcja „Zadania” pokazuje statystyki dotyczące procesów działających w systemie. Wartość „total” jest po prostu całkowitą liczbą procesów. Na przykład, na powyższym zrzucie ekranu, jest 27 uruchomionych procesów. Aby zrozumieć resztę wartości, potrzebujemy trochę informacji o tym, jak jądro Linuksa obsługuje procesy.
Procesy wykonują mieszankę pracy związanej z I/O (takiej jak czytanie dysków) i pracy związanej z CPU (takiej jak wykonywanie operacji arytmetycznych). Procesor jest bezczynny, gdy proces wykonuje operacje wejścia/wyjścia, więc OS przełącza się na wykonywanie innych procesów w tym czasie. Ponadto, system operacyjny pozwala na wykonywanie danego procesu przez bardzo krótki czas, a następnie przełącza się na inny proces. W ten sposób OS-y sprawiają wrażenie, jakby były „wielozadaniowe”. Wszystko to wymaga od nas śledzenia „stanu” procesu. W Linuksie, proces może znajdować się w jednym z tych stanów:
- Runnable (R): Proces w tym stanie jest albo wykonywany na CPU, albo jest obecny w kolejce uruchomień, gotowy do wykonania.
- Interruptible sleep (S): Procesy w tym stanie oczekują na zakończenie jakiegoś zdarzenia.
- Uśpienie bezprzerwowe (D): W tym przypadku proces czeka na zakończenie operacji wejścia/wyjścia.
- Zatrzymane (T): Procesy te zostały zatrzymane przez sygnał sterujący zadaniem (np. przez naciśnięcie Ctrl+Z) lub dlatego, że są śledzone.
- Zombie (Z): Jądro utrzymuje różne struktury danych w pamięci, aby śledzić procesy. Proces może utworzyć wiele procesów potomnych, a one mogą wyjść, gdy rodzic jest nadal w pobliżu. Jednak te struktury danych muszą być zachowane do czasu, aż rodzic uzyska informacje o stanie procesów potomnych. Takie zakończone procesy, których struktury danych wciąż są w pobliżu, nazywane są zombie.
Procesy w stanach D i S są wyświetlane jako „śpiące”, a te w stanie T jako „zatrzymane”. Liczba zombie jest pokazywana jako wartość „zombie”.
Użytkowanie CPU

Sekcja Użytkowanie CPU pokazuje procent czasu procesora poświęcony na różne zadania. Wartość us to czas, jaki procesor spędza na wykonywaniu procesów w przestrzeni użytkownika. Podobnie, wartość sy to czas spędzony na uruchamianiu procesów w przestrzeni jądra.
Linux używa wartości „nice” do określenia priorytetu procesu. Proces z wysoką wartością „nice” jest „milszy” dla innych procesów i otrzymuje niski priorytet. Analogicznie, procesy z niższą wartością „nice” otrzymują wyższy priorytet. Jak zobaczymy później, domyślna wartość „nice” może zostać zmieniona. Czas spędzony na wykonywaniu procesów z ręcznie ustawionym „nice” pojawia się jako wartość ni.
Po niej następuje id, czyli czas, w którym procesor pozostaje bezczynny. Większość systemów operacyjnych wprowadza procesor w tryb oszczędzania energii, gdy jest on bezczynny. Następna jest wartość wa, czyli czas, jaki procesor spędza na oczekiwaniu na zakończenie operacji wejścia/wyjścia.
Przerwania to sygnały do procesora o zdarzeniu, które wymaga natychmiastowej uwagi. Przerwania sprzętowe są zwykle używane przez urządzenia peryferyjne do informowania systemu o zdarzeniach, takich jak naciśnięcie klawisza na klawiaturze. Z drugiej strony, przerwania programowe są generowane przez określone instrukcje wykonywane przez procesor. W obu przypadkach obsługuje je system operacyjny, a czas poświęcony na obsługę przerwań sprzętowych i programowych jest podawany odpowiednio przez hi i si.
W środowisku zwirtualizowanym część zasobów procesora jest przydzielana każdej maszynie wirtualnej (VM). System operacyjny wykrywa, kiedy ma pracę do wykonania, ale nie może jej wykonać, ponieważ procesor jest zajęty przez inną maszynę wirtualną. Ilość czasu straconego w ten sposób to czas „kradzieży”, przedstawiony jako st.
Średnie obciążenie

Sekcja średnie obciążenie przedstawia średnie „obciążenie” w ciągu jednej, pięciu i piętnastu minut. „Obciążenie” jest miarą ilości pracy obliczeniowej wykonywanej przez system. W Linuksie, obciążenie to liczba procesów w stanach R i D w danym momencie. Wartość „średniego obciążenia” daje względną miarę tego, jak długo trzeba czekać na wykonanie zadań.
Zastanówmy się nad kilkoma przykładami, aby zrozumieć tę koncepcję. W systemie z jednym rdzeniem, średnia obciążenia 0,4 oznacza, że system wykonuje tylko 40% pracy, którą może wykonać. Średnia obciążenia równa 1 oznacza, że system jest dokładnie na poziomie wydajności – system zostanie przeciążony przez dodanie nawet odrobiny dodatkowej pracy. System ze średnią obciążenia 2.12 oznacza, że jest przeciążony o 112% więcej pracy niż może obsłużyć.
W systemie wielordzeniowym należy najpierw podzielić średnią obciążenia przez liczbę rdzeni procesora, aby uzyskać podobną miarę.
Dodatkowo, „średnia obciążenia” nie jest tak naprawdę typową „średnią”, jaką większość z nas zna. Jest to „wykładnicza średnia krocząca”, co oznacza, że niewielka część poprzednich średnich obciążeń jest uwzględniana w bieżącej wartości. Jeśli jesteś zainteresowany, ten artykuł omawia wszystkie szczegóły techniczne.
Zrozumienie interfejsu Top: obszar zadań
Obszar podsumowania jest stosunkowo prostszy i zawiera listę procesów. W tym rozdziale poznamy różne kolumny wyświetlane na domyślnym wyjściu top’a.
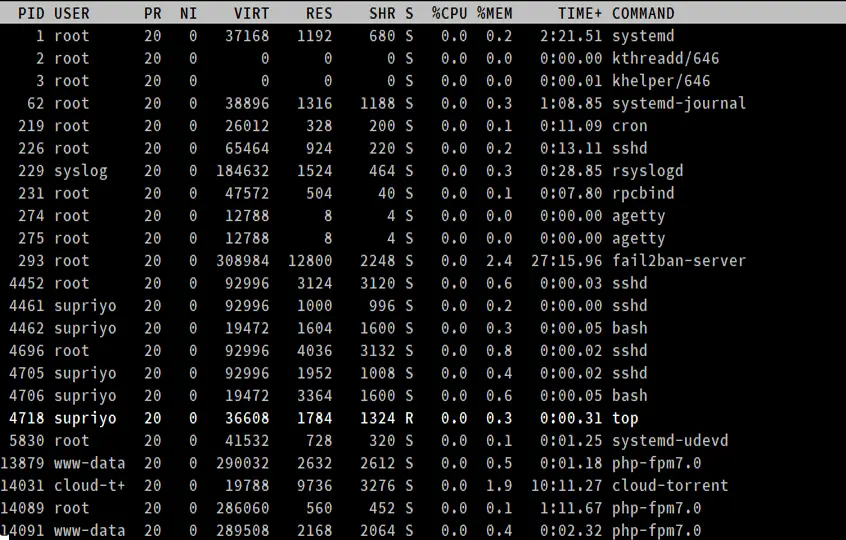
- PID
To jest ID procesu, unikalna dodatnia liczba całkowita identyfikująca proces.
- USER
Jest to „efektywna” nazwa użytkownika (która odpowiada identyfikatorowi użytkownika), który uruchomił proces. Linux przypisuje procesom rzeczywisty identyfikator użytkownika i efektywny identyfikator użytkownika; ten ostatni pozwala procesowi działać w imieniu innego użytkownika. (Na przykład, użytkownik niebędący rootem może podnieść się do rangi roota, aby zainstalować pakiet.)
- PR i NI
Pola „NI” pokazują wartość „nice” procesu. Pole „PR” pokazuje priorytet planowania procesu z perspektywy jądra. Wartość nice wpływa na priorytet procesu.
- VIRT, RES, SHR i %MEM
Te trzy pola są związane z zużyciem pamięci przez procesy. „VIRT” to całkowita ilość pamięci zużytej przez proces. Obejmuje ona kod programu, dane przechowywane przez proces w pamięci, a także wszelkie regiony pamięci, które zostały zamienione na dysk. „RES” to pamięć zużyta przez proces w RAM, a „%MEM” wyraża tę wartość jako procent całkowitej dostępnej pamięci RAM. Wreszcie, „SHR” to ilość pamięci współdzielonej z innymi procesami.
- S
Jak widzieliśmy wcześniej, proces może znajdować się w różnych stanach. To pole pokazuje stan procesu w postaci jednoliterowej.
- TIME+
Jest to całkowity czas procesora wykorzystany przez proces od momentu jego uruchomienia, z dokładnością do setnych części sekundy.
- COMMAND
Kolumna COMMAND pokazuje nazwy procesów.
Przykłady użycia poleceń Top
Do tej pory omówiliśmy interfejs Topa. Jednak może on również zarządzać procesami, a Ty możesz kontrolować różne aspekty działania top’a. W tej sekcji, zajmiemy się kilkoma przykładami.
W większości poniższych przykładów, musisz nacisnąć jakiś klawisz, gdy top jest uruchomiony. Pamiętaj, że wielkość liter ma znaczenie – więc jeśli naciśniesz „k”, gdy Caps Lock jest włączony, to faktycznie naciśniesz „K”, a polecenie nie zadziała, lub zrobi coś zupełnie innego.
Zabijanie procesów
Jeśli chcesz zabić proces, po prostu naciśnij 'k', gdy top jest uruchomiony. Spowoduje to wyświetlenie monitu, w którym należy podać identyfikator procesu i nacisnąć enter.
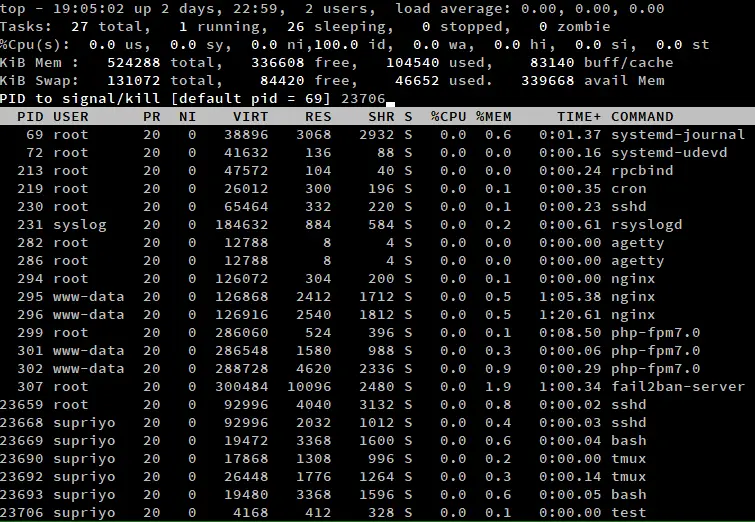
Następnie należy podać sygnał, za pomocą którego proces ma zostać zabity. Jeśli pozostawisz to pole puste, top użyje sygnału SIGTERM, który pozwala procesom kończyć pracę z wdziękiem. Jeśli chcesz zabić proces w sposób wymuszony, możesz wpisać tutaj SIGKILL. Możesz tu także wpisać numer sygnału. Na przykład, numer dla SIGTERM to 15, a SIGKILL to 9.
Jeśli zostawisz ID procesu puste i wciśniesz enter bezpośrednio, to zakończy się najwyższy proces na liście. Jak wspomnieliśmy wcześniej, możesz przewijać listę za pomocą klawiszy strzałek i w ten sposób zmienić proces, który chcesz zabić.
Sortowanie listy procesów
Jednym z najczęstszych powodów używania narzędzia takiego jak Top jest sprawdzenie, który proces zużywa najwięcej zasobów. Możesz nacisnąć następujące klawisze, aby posortować listę:
- ’M', aby posortować według użycia pamięci
- ’P', aby posortować według użycia CPU
- ’N', aby posortować według ID procesu
- ’T', aby posortować według czasu działania
Domyślnie Top wyświetla wszystkie wyniki w porządku malejącym. Możesz jednak przełączyć się na porządek rosnący, naciskając 'R'.
Możesz również posortować listę za pomocą przełącznika -o. Na przykład, jeśli chcesz posortować procesy według wykorzystania procesora, możesz to zrobić za pomocą:
top -o %CPU
W ten sam sposób możesz posortować listę według dowolnych atrybutów w obszarze podsumowania.
Wyświetlanie listy wątków zamiast procesów
Wcześniej poruszyliśmy temat tego, jak Linux przełącza się między procesami. Niestety, procesy nie współdzielą pamięci ani innych zasobów, co sprawia, że takie przełączanie jest dość powolne. Linux, podobnie jak wiele innych systemów operacyjnych, obsługuje „lekką” alternatywę, zwaną „wątkiem”. Są one częścią procesu i współdzielą pewne obszary pamięci i inne zasoby, ale mogą być uruchamiane współbieżnie, tak jak procesy.
Domyślnie top wyświetla na wyjściu listę procesów. Jeśli chcesz zamiast tego wyświetlić listę wątków, naciśnij 'H', gdy top jest uruchomiony. Zauważ, że w wierszu „Zadania” zamiast „Wątki” widnieje „Wątki”, a zamiast procesów wyświetlana jest liczba wątków.
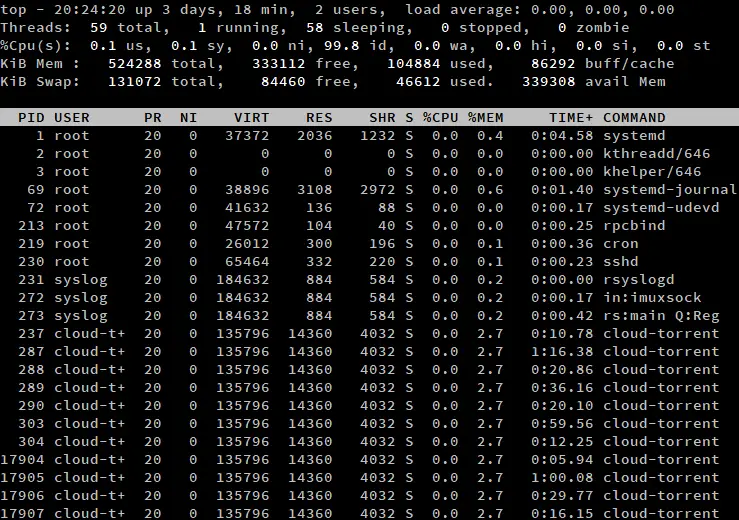
Zapewne zauważyłeś, że żaden z atrybutów na liście procesów nie uległ zmianie. Jak to możliwe, biorąc pod uwagę, że procesy różnią się od wątków? Wewnątrz jądra Linuksa, wątki i procesy są obsługiwane przy użyciu tych samych struktur danych. Dlatego każdy wątek ma swoje własne ID, stan i tak dalej.
Jeśli chcesz przełączyć się z powrotem do widoku procesów, naciśnij ponownie 'H'. Dodatkowo możesz użyć przełącznika -H aby domyślnie wyświetlać wątki.
top -H
Pokazywanie pełnych ścieżek
Domyślnie top nie pokazuje pełnej ścieżki do programu, ani nie rozróżnia procesów kernelspace od procesów userspace. Jeśli potrzebujesz tych informacji, naciśnij 'c', gdy top jest uruchomiony. Ponowne naciśnięcie 'c' spowoduje powrót do ustawień domyślnych.
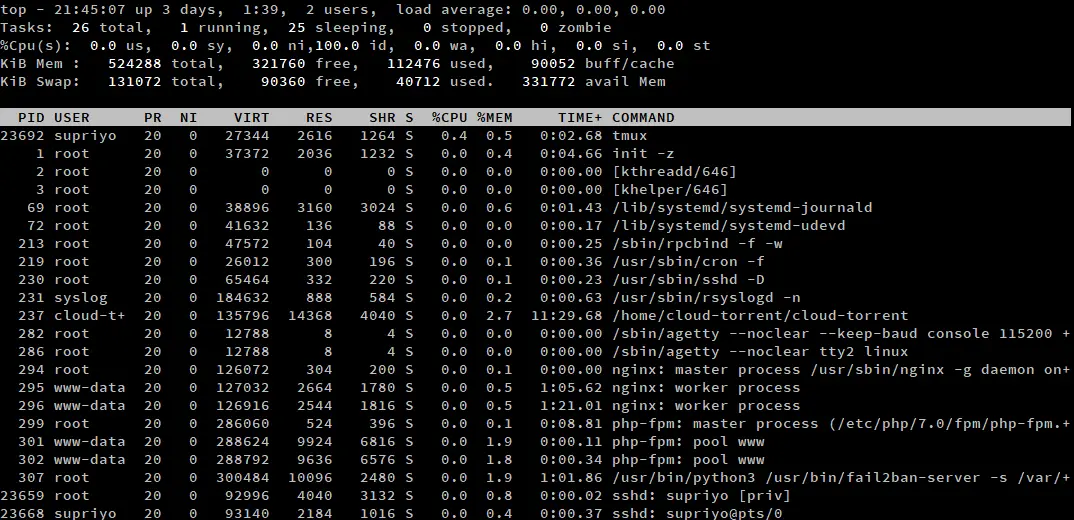
Procesy przestrzeni jądra są oznaczone nawiasami kwadratowymi wokół nich. Jako przykład, na powyższym zrzucie ekranu znajdują się dwa procesy jądra, kthreadd i khelper. W większości instalacji Linuksa, będzie ich zazwyczaj kilka więcej.
Alternatywnie, możesz również uruchomić top z argumentem -c:
top -c
Widok lasu
Czasami, możesz chcieć zobaczyć hierarchię procesów dziecko-rodzic. Można to zobaczyć za pomocą widoku lasu, naciskając 'v’/’V', gdy top jest uruchomiony.
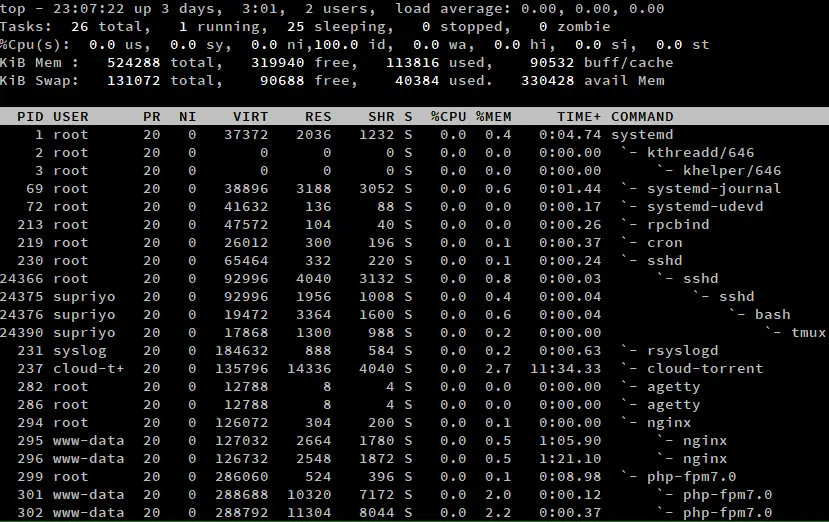
Jak widać na powyższym zrzucie ekranu, proces systemd był pierwszym, który uruchomił się w systemie. Uruchomił procesy takie jak sshd, który z kolei stworzył inne sshd procesy, i tak dalej.
Listowanie procesów od użytkownika
Aby wylistować procesy od określonego użytkownika, naciśnij 'u', gdy top jest uruchomiony. Następnie wpisz nazwę użytkownika, lub pozostaw pustą, aby wyświetlić procesy wszystkich użytkowników.
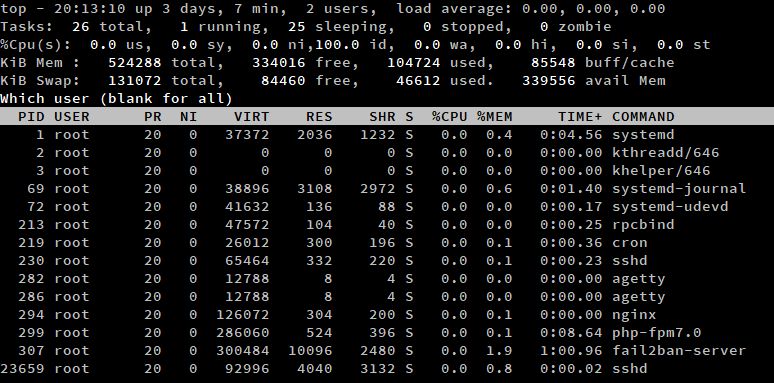
Alternatywnie, możesz uruchomić polecenie top z przełącznikiem -u. W tym przykładzie, mamy wylistowane wszystkie procesy z użytkownika root.
top -u root
Filtrowanie przez procesy
Jeśli masz dużo procesów do pracy, proste sortowanie nie będzie działać wystarczająco dobrze. W takiej sytuacji możesz skorzystać z filtrowania w topie, aby skupić się na kilku procesach. Aby aktywować ten tryb, naciśnij 'o’/’O'. Wewnątrz topu pojawi się znak zachęty, w którym można wpisać wyrażenie filtrujące.
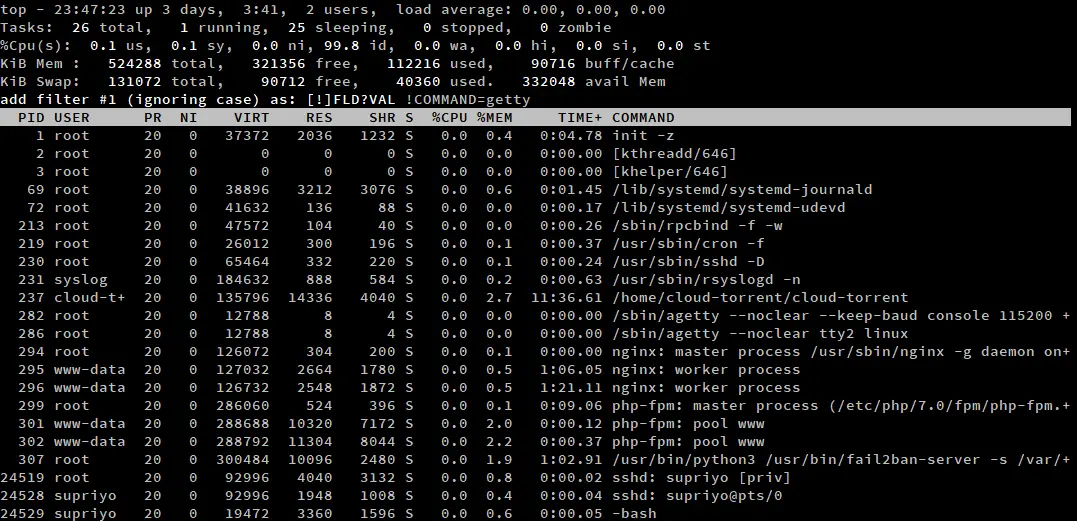
Wyrażenie filtrujące to zdanie określające relację między atrybutem a wartością. Niektóre przykłady filtrów to:
-
COMMAND=getty: Filtruj procesy, które zawierają „getty” w atrybucie COMMAND. -
!COMMAND=getty: Filtruj procesy, które nie mają „getty” w atrybucie COMMAND. -
%CPU>3.0: Filter processes which have a CPU utilization of more than 3%.
Po dodaniu filtra, możesz dalej redukować rzeczy dodając kolejne filtry. Aby wyczyścić wszystkie filtry, które dodałeś, wciśnij '='.
Zmiana domyślnego wyglądu statystyk CPU i pamięci
Jeśli pracujesz głównie w środowisku GUI, możesz nie lubić domyślnego sposobu pokazywania statystyk CPU i pamięci przez Top. Możesz nacisnąć 't' i 'm', aby zmienić styl wyświetlania statystyk CPU i pamięci. Oto zrzut ekranu, na którym raz wcisnęliśmy 't' i 'm'.
Jeśli naciśniesz 't' lub 'm' wielokrotnie, top przejdzie przez cztery różne widoki. Pierwsze dwa naciśnięcia powodują przejście przez dwa różne rodzaje pasków postępu. Jeśli naciśniesz klawisz po raz trzeci, pasek postępu zostanie ukryty. Jeśli naciśniesz klawisz ponownie, przywrócony zostanie domyślny, tekstowy licznik.
Zapisywanie ustawień
Jeśli wprowadziłeś jakieś zmiany w ustawieniach top, możesz je zapisać do późniejszego wykorzystania, naciskając 'W'. top zapisuje swoją konfigurację do pliku .toprc w Twoim katalogu domowym.
Podsumowanie
Komenda top jest niezwykle pomocna w monitorowaniu i zarządzaniu procesami w systemie Linux. Ten artykuł tylko zarysowuje powierzchnię, i jest sporo rzeczy, których nie poruszyliśmy. Na przykład, istnieje wiele więcej kolumn, które możesz dodać do top. Dla wszystkich tych rzeczy, upewnij się, że sprawdzisz stronę man przez uruchomienie man top w swoim systemie.
Jeśli podobał Ci się ten post, proszę podziel się nim 🙂