Inżynieria odwrotna
MachinesEdit
Ponieważ projektowanie wspomagane komputerowo (CAD) stało się bardziej popularne, inżynieria odwrotna stała się realną metodą tworzenia wirtualnego modelu 3D istniejącej części fizycznej do wykorzystania w programach 3D CAD, CAM, CAE lub innych. Proces inżynierii odwrotnej polega na pomiarze obiektu, a następnie odtworzeniu go jako modelu 3D. Fizyczny obiekt może być mierzony przy użyciu technologii skanowania 3D, takich jak maszyny CMM, skanery laserowe, digitalizatory światła strukturalnego lub przemysłowe skanowanie CT (tomografia komputerowa). Same dane pomiarowe, zwykle reprezentowane jako chmura punktów, nie zawierają informacji topologicznych i intencji projektowych. Te pierwsze mogą być odzyskane poprzez konwersję chmury punktów na siatkę trójkątów. Inżynieria odwrotna ma na celu wyjście poza tworzenie takiej siatki i odzyskanie intencji projektowych w postaci prostych powierzchni analitycznych (płaszczyzn, cylindrów, itp.), a także ewentualnie powierzchni NURBS w celu uzyskania modelu CAD z reprezentacją graniczną. Odzyskanie takiego modelu pozwala na modyfikację projektu w celu spełnienia nowych wymagań, wygenerowanie planu produkcji, itp.
Modelowanie hybrydowe jest powszechnie używanym terminem, gdy modelowanie NURBS i parametryczne są zaimplementowane razem. Użycie kombinacji powierzchni geometrycznych i swobodnych może zapewnić potężną metodę modelowania 3D. Obszary danych o swobodnym kształcie mogą być połączone z dokładnymi powierzchniami geometrycznymi w celu utworzenia modelu hybrydowego. Typowym przykładem może być inżynieria odwrotna głowicy cylindra, która zawiera dowolnie ukształtowane elementy odlewane, takie jak płaszcze wodne i obszary o wysokiej tolerancji obróbki skrawaniem.
Inżynieria odwrotna jest również wykorzystywana przez firmy do wprowadzenia istniejącej geometrii fizycznej do cyfrowych środowisk rozwoju produktu, do tworzenia cyfrowego zapisu 3D własnych produktów lub do oceny produktów konkurencji. Jest ona wykorzystywana do analizowania, jak działa produkt, co robi, jakie ma komponenty; szacowania kosztów; identyfikowania potencjalnych naruszeń patentów itp.
Inżynieria wartości, pokrewna działalność, która jest również wykorzystywana przez firmy, polega na dekonstrukcji i analizie produktów. Celem jest jednak znalezienie możliwości cięcia kosztów.
SoftwareEdit
W 1990 roku Institute of Electrical and Electronics Engineers (IEEE) zdefiniował inżynierię odwrotną (SRE) jako „proces analizy systemu przedmiotowego w celu zidentyfikowania jego komponentów i ich wzajemnych powiązań oraz stworzenia reprezentacji systemu w innej formie lub na wyższym poziomie abstrakcji”, w którym „system przedmiotowy” jest produktem końcowym rozwoju oprogramowania. Inżynieria odwrotna jest procesem wyłącznie badawczym, a badany system oprogramowania nie jest modyfikowany, co w przeciwnym razie byłoby reengineeringiem lub restrukturyzacją. Inżynieria odwrotna może być wykonywana z dowolnego etapu cyklu produktu, niekoniecznie z funkcjonalnego produktu końcowego.
W inżynierii odwrotnej występują dwa komponenty: redokumentacja i odzyskiwanie projektu. Redokumentacja polega na stworzeniu nowej reprezentacji kodu komputerowego, tak aby był on łatwiejszy do zrozumienia. Tymczasem, odzyskiwanie projektu jest wykorzystaniem dedukcji lub rozumowania z wiedzy ogólnej lub osobistego doświadczenia produktu, aby w pełni zrozumieć jego funkcjonalność. Może być również postrzegane jako „cofanie się przez cykl rozwoju”. W tym modelu, wyjście z fazy implementacji (w formie kodu źródłowego) jest cofane do fazy analizy, w odwróceniu tradycyjnego modelu wodospadowego. Innym terminem dla tej techniki jest rozumienie programu. Konferencja robocza na temat inżynierii odwrotnej (WCRE) jest organizowana corocznie w celu zbadania i rozszerzenia technik inżynierii odwrotnej. Komputerowo wspomagana inżynieria oprogramowania (CASE) i zautomatyzowane generowanie kodu wniosły ogromny wkład w dziedzinę inżynierii odwrotnej.
Technologia antytamperowska oprogramowania, taka jak obfuskacja, jest używana do powstrzymania zarówno inżynierii odwrotnej, jak i ponownego projektowania oprogramowania własnościowego i systemów zasilanych oprogramowaniem. W praktyce, pojawiają się dwa główne typy inżynierii wstecznej. W pierwszym przypadku, kod źródłowy oprogramowania jest już dostępny, ale odkrywane są aspekty wyższego poziomu programu, które być może są słabo udokumentowane lub udokumentowane, ale już nieaktualne. W drugim przypadku, nie ma dostępnego kodu źródłowego dla oprogramowania, a wszelkie wysiłki w kierunku odkrycia jednego możliwego kodu źródłowego dla oprogramowania są uważane za inżynierię wsteczną. Drugie zastosowanie tego terminu jest bardziej znane większości ludzi. Inżynieria odwrotna oprogramowania może wykorzystywać technikę czystego pokoju w celu uniknięcia naruszenia praw autorskich.
Przy okazji, testowanie czarnej skrzynki w inżynierii oprogramowania ma wiele wspólnego z inżynierią odwrotną. Tester zazwyczaj posiada API, ale jego celem jest znalezienie błędów i nieudokumentowanych funkcji poprzez przeczesanie produktu z zewnątrz.
Inne cele inżynierii odwrotnej obejmują audyt bezpieczeństwa, usuwanie zabezpieczeń przed kopiowaniem („cracking”), obchodzenie ograniczeń dostępu często obecnych w elektronice użytkowej, dostosowywanie systemów wbudowanych (takich jak systemy zarządzania silnikiem), wewnętrzne naprawy lub modernizacje, umożliwienie dodatkowych funkcji na tanim „okaleczonym” sprzęcie (takim jak niektóre zestawy układów kart graficznych), a nawet zwykłe zaspokojenie ciekawości.
Binarny softwareEdit
Binarna inżynieria wsteczna jest wykonywana jeśli kod źródłowy oprogramowania jest niedostępny. Proces ten jest czasem określany jako inżynieria kodu wstecznego, lub RCE. Na przykład, dekompilacja binariów dla platformy Java może być dokonana przy użyciu programu Jad. Jednym ze słynnych przypadków inżynierii odwrotnej była pierwsza implementacja BIOS-u komputera PC przez firmę inną niż IBM, co zapoczątkowało historyczny przemysł komputerów kompatybilnych z IBM PC, który przez wiele lat był dominującą platformą sprzętową. Inżynieria wsteczna oprogramowania jest chroniona w USA przez wyjątek fair use w prawie autorskim. Oprogramowanie Samba, które pozwala systemom bez systemu Microsoft Windows współdzielić pliki z systemami, które go używają, jest klasycznym przykładem inżynierii wstecznej oprogramowania, ponieważ projekt Samba musiał odtworzyć niepublikowane informacje o tym, jak działa współdzielenie plików w Windows, aby komputery bez Windows mogły je emulować. Projekt Wine robi to samo dla Windows API, a OpenOffice.org jest jedną ze stron, która robi to dla formatów plików Microsoft Office. Projekt ReactOS jest jeszcze bardziej ambitny w swoich celach, ponieważ dąży do zapewnienia binarnej (ABI i API) zgodności z obecnymi systemami operacyjnymi Windows z gałęzi NT, co pozwala oprogramowaniu i sterownikom napisanym dla Windows działać w czystym pomieszczeniu na poddanym inżynierii wstecznej odpowiedniku wolnego oprogramowania (GPL). WindowsSCOPE pozwala na inżynierię wsteczną pełnej zawartości pamięci operacyjnej systemu Windows, włączając w to binarną, graficzną inżynierię wsteczną wszystkich uruchomionych procesów.
Innym klasycznym, choć mało znanym, przykładem jest to, że w 1987 roku Bell Laboratories dokonało inżynierii wstecznej systemu Mac OS System 4.1, pierwotnie działającego na Apple Macintosh SE, tak aby można go było uruchomić na własnych maszynach RISC.
Techniki oprogramowania binarnegoEdit
Inżynieria wsteczna oprogramowania może być osiągnięta różnymi metodami. Trzy główne grupy inżynierii wstecznej oprogramowania to
- Analiza poprzez obserwację wymiany informacji, najbardziej rozpowszechniona w inżynierii wstecznej protokołów, która obejmuje użycie analizatorów magistrali i snifferów pakietów, takich jak dostęp do magistrali komputerowej lub połączenia sieci komputerowej i ujawnienie danych o ruchu na nich. Bus lub zachowanie sieci może być następnie analizowane w celu wytworzenia samodzielnej implementacji, która naśladuje to zachowanie. Jest to szczególnie przydatne dla inżynierii odwrotnej sterowników urządzeń. Czasami inżynieria wsteczna w systemach wbudowanych jest znacznie ułatwiona dzięki narzędziom celowo wprowadzonym przez producenta, takim jak porty JTAG lub inne środki debugowania. W systemie Microsoft Windows popularne są niskopoziomowe debuggery, takie jak SoftICE.
- Dezasemblacja przy użyciu disassemblera, co oznacza, że surowy język maszynowy programu jest odczytywany i rozumiany w jego własnych kategoriach, tylko z pomocą mnemotechnik języka maszynowego. Działa to na każdym programie komputerowym, ale może zająć sporo czasu, szczególnie tym, którzy nie są przyzwyczajeni do kodu maszynowego. Szczególnie popularnym narzędziem jest Interactive Disassembler.
- Dekompilacja przy użyciu dekompilatora, procesu, który próbuje, z różnym skutkiem, odtworzyć kod źródłowy w jakimś języku wysokiego poziomu dla programu dostępnego tylko w kodzie maszynowym lub bajtkodzie.
Klasyfikacja oprogramowaniaEdit
Klasyfikacja oprogramowania to proces identyfikacji podobieństw między różnymi binariami oprogramowania (takimi jak dwie różne wersje tego samego binarnego), używany do wykrywania relacji kodu między próbkami oprogramowania. Zadanie to było tradycyjnie wykonywane ręcznie z wielu powodów (takich jak analiza łat w celu wykrycia podatności i naruszenia praw autorskich), ale obecnie może być wykonywane w sposób nieco automatyczny dla dużych liczb próbek.
Metoda ta jest używana głównie do długich i dokładnych zadań inżynierii wstecznej (kompletna analiza złożonego algorytmu lub dużego fragmentu oprogramowania). Ogólnie rzecz biorąc, klasyfikacja statystyczna jest uważana za trudny problem, co jest również prawdą w przypadku klasyfikacji oprogramowania, a więc niewiele rozwiązań / narzędzi, które dobrze radzą sobie z tym zadaniem.
Source codeEdit
Liczba narzędzi UML odnosi się do procesu importowania i analizowania kodu źródłowego w celu wygenerowania diagramów UML jako „inżynierii odwrotnej”. Zobacz Lista narzędzi UML.
Ale chociaż UML jest jednym z podejść do zapewnienia „inżynierii odwrotnej” bardziej niedawne postępy w międzynarodowych działaniach normalizacyjnych doprowadziły do opracowania Knowledge Discovery Metamodel (KDM). Standard ten dostarcza ontologii dla pośredniej (lub wyabstrahowanej) reprezentacji konstrukcji języka programowania i ich wzajemnych powiązań. Jako standard Object Management Group (na drodze do stania się również standardem ISO), KDM zaczął być wykorzystywany w przemyśle wraz z rozwojem narzędzi i środowisk analitycznych, które mogą zapewnić ekstrakcję i analizę kodu źródłowego, binarnego i bajtowego. Dla analizy kodu źródłowego, granularna architektura standardów KDM umożliwia ekstrakcję przepływów systemu oprogramowania (dane, sterowanie i mapy połączeń), architektury i wiedzy warstwy biznesowej (reguły, terminy i procesy). Standard pozwala na użycie wspólnego formatu danych (XMI) umożliwiającego korelację różnych warstw wiedzy o systemie dla szczegółowej analizy (np. root cause, impact) lub analizy pochodnej (np. ekstrakcja procesów biznesowych). Chociaż wysiłki w celu reprezentacji konstrukcji językowych mogą nie mieć końca ze względu na liczbę języków, ciągłą ewolucję języków oprogramowania i rozwój nowych języków, standard pozwala na użycie rozszerzeń w celu wsparcia szerokiego zestawu języków, jak również ewolucji. KDM jest kompatybilny z UML, BPMN, RDF i innymi standardami umożliwiającymi migrację do innych środowisk, a tym samym wykorzystanie wiedzy o systemie w takich działaniach, jak transformacja systemu oprogramowania i analiza warstwy biznesowej przedsiębiorstwa.
ProtokołyEdit
Protokoły są zestawami reguł opisujących formaty wiadomości i sposób, w jaki wiadomości są wymieniane: maszyna stanu protokołu. W związku z tym, problem inżynierii wstecznej protokołów może być podzielony na dwa podproblemy: format wiadomości i inżynierię wsteczną maszyny stanów.
Formaty wiadomości były tradycyjnie inżynierią wsteczną poprzez żmudny ręczny proces, który obejmował analizę tego, jak implementacje protokołów przetwarzają wiadomości, ale ostatnie badania zaproponowały szereg automatycznych rozwiązań. Zazwyczaj automatyczne podejścia grupują obserwowane wiadomości w klastry przy użyciu różnych analiz klasteryzacji, lub emulują implementację protokołu śledząc przetwarzanie wiadomości.
Mniej pracy włożono w inżynierię wsteczną mechanizmów stanów protokołów. Ogólnie rzecz biorąc, maszyny stanów protokołów mogą być poznane albo poprzez proces uczenia offline, który pasywnie obserwuje komunikację i próbuje zbudować najbardziej ogólną maszynę stanów akceptującą wszystkie zaobserwowane sekwencje wiadomości, albo poprzez uczenie online, które pozwala na interaktywne generowanie sekwencji wiadomości i słuchanie odpowiedzi na te sekwencje. Ogólnie wiadomo, że uczenie offline małych maszyn stanów jest NP-complete, ale uczenie online może być wykonane w czasie wielomianowym. Automatyczne podejście offline zostało zademonstrowane przez Comparetti et al., a podejście online przez Cho et al.
Inne składniki typowych protokołów, takie jak funkcje szyfrowania i haszowania, mogą być również automatycznie odwzorowane. Zazwyczaj, automatyczne podejścia śledzą wykonanie implementacji protokołu i próbują wykryć bufory w pamięci przechowujące niezaszyfrowane pakiety.
Układy scalone/karty inteligentneEdit
Inżynieria wsteczna jest inwazyjną i destrukcyjną formą analizy karty inteligentnej. Atakujący używa środków chemicznych do wytrawiania kolejnych warstw karty i wykonuje zdjęcia za pomocą skaningowego mikroskopu elektronowego (SEM). Ta technika może ujawnić kompletną część sprzętową i programową karty inteligentnej. Głównym problemem dla atakującego jest doprowadzenie wszystkiego do właściwego porządku, aby dowiedzieć się, jak to wszystko działa. Twórcy karty starają się ukryć klucze i operacje, mieszając pozycje w pamięci, na przykład przez zakodowanie magistrali.
W niektórych przypadkach możliwe jest nawet podłączenie sondy do pomiaru napięcia, gdy karta inteligentna jest jeszcze sprawna. Twórcy karty stosują czujniki, aby wykryć i zapobiec temu atakowi. Atak ten nie jest zbyt powszechny, ponieważ wymaga zarówno dużych nakładów pracy, jak i specjalnego sprzętu, który jest zazwyczaj dostępny tylko dla dużych producentów chipów. Ponadto, zysk z tego ataku jest niski, ponieważ często stosowane są inne techniki zabezpieczeń, takie jak konta „shadow account”. Wciąż nie jest pewne, czy ataki na karty z chipem i PIN-em, mające na celu replikację danych szyfrujących, a następnie złamanie PIN-ów, stanowiłyby opłacalny atak na uwierzytelnianie wieloczynnikowe.
Pełna inżynieria odwrotna przebiega w kilku głównych krokach.
Pierwszym krokiem po zrobieniu zdjęć za pomocą SEM jest zszycie obrazów razem, co jest konieczne, ponieważ każda warstwa nie może być uchwycona przez pojedyncze ujęcie. SEM musi przeczesać obszar obwodu i wykonać kilkaset zdjęć, aby pokryć całą warstwę. Zszywanie obrazów bierze jako dane wejściowe kilkaset zdjęć i daje pojedynczy, prawidłowo nałożony obraz całej warstwy.
Następnie, zszyte warstwy muszą być wyrównane, ponieważ próbka po wytrawieniu nie może być umieszczona dokładnie w tej samej pozycji względem SEM za każdym razem. Dlatego zszyte wersje nie będą zachodzić na siebie w sposób prawidłowy, jak na prawdziwym obwodzie. Zazwyczaj wybiera się trzy odpowiadające sobie punkty i na tej podstawie stosuje się transformację.
Aby wyodrębnić strukturę obwodu, wyrównane, zszyte obrazy muszą zostać poddane segmentacji, która uwydatnia ważne obwody i oddziela je od nieciekawego tła i materiałów izolacyjnych.
Wreszcie, przewody mogą być śledzone z jednej warstwy do następnej, a lista sieciowa obwodu, która zawiera wszystkie informacje o obwodzie, może być zrekonstruowana.
Zastosowania wojskoweEdit
Inżynieria odwrotna jest często wykorzystywana przez ludzi do kopiowania technologii, urządzeń lub informacji innych narodów, które zostały uzyskane przez regularne wojska w terenie lub przez operacje wywiadowcze. Była ona często stosowana podczas II wojny światowej i zimnej wojny. Oto znane przykłady z okresu II wojny światowej i późniejsze:
- Puszka Jerry’ego: Brytyjskie i amerykańskie siły zauważyły, że Niemcy mieli puszki z benzyną o doskonałym projekcie. Stworzyli oni kopie tych puszek, które były popularnie znane jako „puszki Jerry’ego”.
- Panzerschreck: Niemcy zdobyli amerykańską bazookę podczas II wojny światowej i zmodyfikowali ją, aby stworzyć większą Panzerschreck.
- Tupolew Tu-4: W 1944 roku trzy amerykańskie bombowce B-29 na misjach nad Japonią zostały zmuszone do lądowania w Związku Radzieckim. Sowieci, którzy nie posiadali podobnego bombowca strategicznego, postanowili skopiować B-29. W ciągu trzech lat stworzyli Tu-4, prawie idealną kopię.
- Radar SCR-584: skopiowany przez Związek Radziecki po II wojnie światowej, znany jest z kilku modyfikacji – СЦР-584, Бинокль-Д.
- Rakieta V-2: Dokumenty techniczne dotyczące V-2 i powiązanych technologii zostały zdobyte przez zachodnich aliantów pod koniec wojny. Amerykanie skoncentrowali swoje wysiłki w zakresie inżynierii odwrotnej w ramach operacji Paperclip, która doprowadziła do opracowania rakiety PGM-11 Redstone. Sowieci wykorzystali zdobytych niemieckich inżynierów do odtworzenia dokumentów technicznych i planów, a także pracowali na zdobytym sprzęcie, aby stworzyć swój klon rakiety, R-1. W ten sposób rozpoczął się powojenny radziecki program rakietowy, który doprowadził do powstania R-7 i rozpoczęcia wyścigu kosmicznego.
- Pocisk K-13/R-3S (NATO-wska nazwa AA-2 Atoll), radziecka kopia AIM-9 Sidewinder, stała się możliwa po tym, jak tajwański AIM-9B trafił chińskiego MiG-17 bez wybuchu we wrześniu 1958 roku. Pocisk utknął w płatowcu, a pilot wrócił do bazy z czymś, co radzieccy naukowcy określiliby jako uniwersytecki kurs rozwoju pocisków.
- Pocisk BGM-71 TOW: W maju 1975 roku negocjacje między Iranem a Hughes Missile Systems w sprawie koprodukcji pocisków TOW i Maverick utknęły w martwym punkcie z powodu nieporozumień dotyczących struktury cenowej, a późniejsza rewolucja w 1979 roku zakończyła wszelkie plany takiej koprodukcji. Iran był później sukces w reverse-engineering pocisku i teraz produkuje swoją własną kopię, Toophan.
- Chiny odwrócił inżynierii wiele przykładów zachodnich i rosyjskich sprzętu, z samolotów myśliwskich do pocisków i samochodów HMMWV, takich jak MiG-15 (który stał się J-7) i Su-33 (który stał się J-15). Nowsze analizy rozwoju wojskowego Chin wskazały na nieodłączne ograniczenia inżynierii odwrotnej dla zaawansowanych systemów uzbrojenia.
- Podczas II wojny światowej polscy i brytyjscy kryptografowie badali zdobyte niemieckie maszyny szyfrujące wiadomości „Enigma” w poszukiwaniu słabych punktów. Ich działanie było następnie symulowane na urządzeniach elektromechanicznych, „bombach”, które wypróbowywały wszystkie możliwe ustawienia scramblerów maszyn „Enigma”, co pomogło w złamaniu zakodowanych wiadomości, które zostały wysłane przez Niemców.
- Również podczas II wojny światowej, brytyjscy naukowcy analizowali i pokonali serię coraz bardziej wyrafinowanych systemów radionawigacyjnych używanych przez Luftwaffe do wykonywania kierowanych misji bombowych w nocy. Brytyjskie środki przeciwdziałania systemowi były tak skuteczne, że w niektórych przypadkach niemieckie samoloty były prowadzone przez sygnały do lądowania w bazach RAF, ponieważ wierzyły, że wróciły na niemieckie terytorium.
Sieci genoweEdit
Koncepcje inżynierii odwrotnej zostały zastosowane również w biologii, a konkretnie do zadania zrozumienia struktury i funkcji sieci regulacyjnych genów. Regulują one niemal każdy aspekt biologicznego zachowania i pozwalają komórkom na przeprowadzanie procesów fizjologicznych i odpowiedzi na zakłócenia. Zrozumienie struktury i dynamicznego zachowania sieci genów jest zatem jednym z najważniejszych wyzwań biologii systemów, z natychmiastowymi praktycznymi reperkusjami w kilku zastosowaniach, które wykraczają poza badania podstawowe. Istnieje kilka metod odwrotnej inżynierii sieci regulacyjnych genów przy użyciu metod biologii molekularnej i nauki o danych. Zostały one ogólnie podzielone na sześć klas:
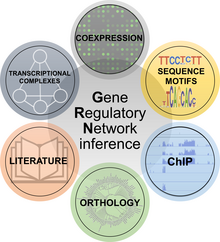
- Metody koekspresyjne opierają się na założeniu, że jeśli dwa geny wykazują podobny profil ekspresji, to mogą być ze sobą powiązane, choć na podstawie koekspresji nie można po prostu wnioskować o przyczynowości.
- Metody motywów sekwencji analizują promotory genów w celu znalezienia specyficznych domen wiążących czynniki transkrypcyjne. Jeśli przewiduje się, że czynnik transkrypcyjny wiąże się z promotorem określonego genu, można wysunąć hipotezę o powiązaniach regulacyjnych.
- Metody chromatynowej immunoprecypitacji (ChIP) badają profil wiązania DNA wybranych czynników transkrypcyjnych w całym genomie, aby wnioskować o ich sieci genów.
- Metody ortologiczne przenoszą wiedzę o sieci genów z jednego gatunku na drugi.
- Metody literaturowe wykorzystują eksplorację tekstów i badania manualne do identyfikacji domniemanych lub potwierdzonych eksperymentalnie połączeń sieci genowych.
- Metody kompleksów transkrypcyjnych wykorzystują informacje o interakcjach białko-białko pomiędzy czynnikami transkrypcyjnymi, rozszerzając w ten sposób koncepcję sieci genowych o kompleksy regulacyjne transkrypcji.
Często niezawodność sieci genowych testuje się poprzez eksperymenty z perturbacjami genetycznymi, po których następuje modelowanie dynamiczne, oparte na zasadzie, że usunięcie jednego węzła sieci ma przewidywalny wpływ na funkcjonowanie pozostałych węzłów sieci.Zastosowania inżynierii odwrotnej sieci genowych sięgają od zrozumienia mechanizmów fizjologii roślin do wskazania nowych celów terapii przeciwnowotworowej.
Pokrywanie się z prawem patentowymEdit
Inżynieria odwrotna odnosi się przede wszystkim do zdobywania zrozumienia procesu lub artefaktu, w którym sposób jego budowy, użycia lub wewnętrznych procesów nie został wyjaśniony przez jego twórcę.
Przedmioty opatentowane nie muszą być same w sobie poddane inżynierii odwrotnej, aby mogły być badane, ponieważ istotą patentu jest to, że wynalazcy sami zapewniają szczegółowe publiczne ujawnienie, a w zamian otrzymują ochronę prawną wynalazku, który jest z nim związany. Jakkolwiek, przedmiot wyprodukowany na podstawie jednego lub więcej patentów może także zawierać inną technologię, która nie jest opatentowana i nie ujawniona. W rzeczy samej, jedną z powszechnych motywacji inżynierii wstecznej jest ustalenie, czy produkt konkurenta zawiera naruszenie patentu lub praw autorskich.