Algoritmo Random Forest con Python y Scikit-Learn
El bosque aleatorio es un tipo de algoritmo de aprendizaje automático supervisado basado en el aprendizaje por conjuntos. El aprendizaje por conjuntos es un tipo de aprendizaje en el que se unen diferentes tipos de algoritmos o el mismo algoritmo varias veces para formar un modelo de predicción más potente. El algoritmo de bosque aleatorio combina múltiples algoritmos del mismo tipo, es decir, múltiples árboles de decisión, dando como resultado un bosque de árboles, de ahí el nombre de «Bosque Aleatorio». El algoritmo de bosque aleatorio puede utilizarse tanto para tareas de regresión como de clasificación.
Cómo funciona el algoritmo de bosque aleatorio
Los siguientes son los pasos básicos que se siguen para realizar el algoritmo de bosque aleatorio:
- Elegir N registros aleatorios del conjunto de datos.
- Construya un árbol de decisión basado en estos N registros.
- Elija el número de árboles que desee en su algoritmo y repita los pasos 1 y 2.
- En el caso de un problema de regresión, para un nuevo registro, cada árbol del bosque predice un valor para Y (salida). El valor final se puede calcular tomando la media de todos los valores predichos por todos los árboles del bosque. O, en el caso de un problema de clasificación, cada árbol del bosque predice la categoría a la que pertenece el nuevo registro. Finalmente, el nuevo registro se asigna a la categoría que gana la mayoría de los votos.
Inventajas del uso de Random Forest
Como con cualquier algoritmo, hay ventajas y desventajas en su uso. En las siguientes dos secciones echaremos un vistazo a las ventajas y desventajas de usar el bosque aleatorio para la clasificación y la regresión.
- El algoritmo del bosque aleatorio no está sesgado, ya que, hay múltiples árboles y cada árbol se entrena en un subconjunto de datos. Básicamente, el algoritmo de bosque aleatorio se basa en el poder de «la multitud»; por lo tanto, el sesgo general del algoritmo se reduce.
- Este algoritmo es muy estable. Incluso si se introduce un nuevo punto de datos en el conjunto de datos, el algoritmo general no se ve muy afectado, ya que los nuevos datos pueden afectar a un árbol, pero es muy difícil que afecten a todos los árboles.
- El algoritmo de bosque aleatorio funciona bien cuando se tienen características tanto categóricas como numéricas.
- El algoritmo de bosque aleatorio también funciona bien cuando los datos tienen valores perdidos o no se han escalado bien (aunque hemos realizado el escalado de características en este artículo sólo con fines de demostración).
Desventajas del uso de bosques aleatorios
- Una de las principales desventajas de los bosques aleatorios reside en su complejidad. Requieren muchos más recursos computacionales, debido al gran número de árboles de decisión unidos.
- Debido a su complejidad, requieren mucho más tiempo para entrenar que otros algoritmos comparables.
A lo largo del resto de este artículo veremos cómo se puede utilizar la librería Scikit-Learn de Python para implementar el algoritmo de bosque aleatorio para resolver problemas de regresión, así como de clasificación.
Parte 1: Uso de los bosques aleatorios para la regresión
En esta sección estudiaremos cómo se pueden utilizar los bosques aleatorios para resolver problemas de regresión utilizando Scikit-Learn. En la siguiente sección resolveremos un problema de clasificación a través de bosques aleatorios.
Definición del problema
El problema aquí es predecir el consumo de gasolina (en millones de galones) en 48 de los estados de Estados Unidos basándose en el impuesto sobre la gasolina (en centavos), la renta per cápita (en dólares), las carreteras pavimentadas (en millas) y la proporción de población con el permiso de conducir.
Solución
Para resolver este problema de regresión utilizaremos el algoritmo random forest a través de la librería Scikit-Learn Python. Seguiremos el pipeline de aprendizaje automático tradicional para resolver este problema. Sigue estos pasos:
1. Importar librerías
Ejecuta el siguiente código para importar las librerías necesarias:
import pandas as pdimport numpy as np2. Importar el conjunto de datos
El conjunto de datos para este problema está disponible en:
https://drive.google.com/file/d/1mVmGNx6cbfvRHC_DvF12ZL3wGLSHD9f_/view
Para este tutorial, el conjunto de datos se ha descargado en la carpeta «Datasets» de la unidad «D». Tendrá que cambiar la ruta del archivo según su propia configuración.
Ejecute el siguiente comando para importar el conjunto de datos:
dataset = pd.read_csv('D:\Datasets\petrol_consumption.csv')Para obtener una vista de alto nivel de cómo es el conjunto de datos, ejecute el siguiente comando:
dataset.head()| Tasa_de_gasolina | Renta_promedio | Carreteras | Licencia_de_conducción(%) | Consumo_de_gasolina | |
|---|---|---|---|---|---|
| 0 | 9.0 | 3571 | 1976 | 0,525 | 541 | 1 | 9,0 | 4092 | 1250 | 0.572 | 524 |
| 2 | 9,0 | 3865 | 1586 | 0,580 | 561 |
| 7.5 | 4870 | 2351 | 0,529 | 414 | |
| 4 | 8,0 | 4399 | 431 | 0.544 | 410 |
Podemos ver que los valores de nuestro conjunto de datos no están muy bien escalados. Los escalaremos antes de entrenar el algoritmo.
3. Preparar los datos para el entrenamiento
En esta sección se realizarán dos tareas. La primera tarea consiste en dividir los datos en conjuntos de «atributos» y «etiquetas». Los datos resultantes se dividen en conjuntos de entrenamiento y de prueba.
El siguiente script divide los datos en atributos y etiquetas:
X = dataset.iloc.valuesy = dataset.iloc.valuesPor último, vamos a dividir los datos en conjuntos de entrenamiento y de prueba:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)4. Escalado de características
Sabemos que nuestro conjunto de datos aún no es un valor escalado, por ejemplo, el campo Promedio_Ingresos tiene valores en el rango de miles mientras que Impuesto_Petróleo tiene valores en el rango de decenas. Por lo tanto, sería beneficioso escalar nuestros datos (aunque, como se ha mencionado anteriormente, este paso no es tan importante para el algoritmo de bosques aleatorios). Para ello, utilizaremos la clase StandardScaler de Scikit-Learn. Ejecuta el siguiente código para hacerlo:
# Feature Scalingfrom sklearn.preprocessing import StandardScalersc = StandardScaler()X_train = sc.fit_transform(X_train)X_test = sc.transform(X_test)5. Entrenando el Algoritmo
Ahora que hemos escalado nuestro conjunto de datos, es el momento de entrenar nuestro algoritmo de bosque aleatorio para resolver este problema de regresión. Ejecuta el siguiente código:
from sklearn.ensemble import RandomForestRegressorregressor = RandomForestRegressor(n_estimators=20, random_state=0)regressor.fit(X_train, y_train)y_pred = regressor.predict(X_test)La clase RandomForestRegressor de la librería sklearn.ensemble se utiliza para resolver problemas de regresión a través de random forest. El parámetro más importante de la clase RandomForestRegressor es el parámetro n_estimators. Este parámetro define el número de árboles del bosque aleatorio. Empezaremos con n_estimator=20 para ver cómo se comporta nuestro algoritmo. Puedes encontrar los detalles de todos los parámetros de RandomForestRegressor aquí.
6. Evaluación del algoritmo
El último y definitivo paso para resolver un problema de aprendizaje automático es evaluar el rendimiento del algoritmo. Para los problemas de regresión, las métricas utilizadas para evaluar un algoritmo son el error medio absoluto, el error medio al cuadrado y el error medio al cuadrado. Ejecute el siguiente código para encontrar estos valores:
from sklearn import metricsprint('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))print('Root Mean Squared Error:', np.sqrt(metrics.mean_squared_error(y_test, y_pred)))El resultado será algo parecido a esto:
Mean Absolute Error: 51.765Mean Squared Error: 4216.16675Root Mean Squared Error: 64.932016371Con 20 árboles, el error cuadrático medio es de 64,93 que es mayor que el 10 por ciento del consumo medio de gasolina, es decir, 576,77. Esto puede indicar, entre otras cosas, que no hemos utilizado suficientes estimadores (árboles).
Si se cambia el número de estimadores a 200, los resultados son los siguientes:
Mean Absolute Error: 47.9825Mean Squared Error: 3469.7007375Root Mean Squared Error: 58.9041657058El siguiente gráfico muestra la disminución del valor del error cuadrático medio (RMSE) con respecto al número de estimadores. Aquí el eje X contiene el número de estimadores mientras que el eje Y contiene el valor del error medio cuadrático.
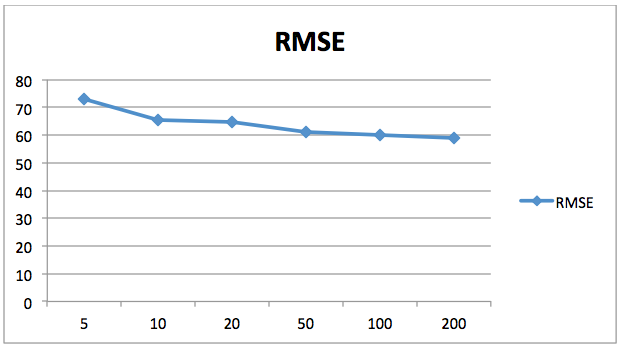
Puede ver que los valores de error disminuyen con el aumento del número de estimadores. Después de 200 la tasa de disminución del error disminuye, por lo que 200 es un buen número para n_estimators. Puede jugar con el número de árboles y otros parámetros para ver si puede obtener mejores resultados por su cuenta.
Parte 2: Uso de Random Forest para la clasificación
Definición del problema
La tarea aquí es predecir si un billete de banco es auténtico o no basado en cuatro atributos i.e. varianza de la imagen transformada en wavelet, asimetría, entropía y curtosis de la imagen.
Solución
Este es un problema de clasificación binaria y utilizaremos un clasificador de bosque aleatorio para resolver este problema. Los pasos seguidos para resolver este problema serán similares a los realizados para la regresión.
1. Importar librerías
import pandas as pdimport numpy as np2. Importar el conjunto de datos
El conjunto de datos se puede descargar desde el siguiente enlace:
https://drive.google.com/file/d/13nw-uRXPY8XIZQxKRNZ3yYlho-CYm_Qt/view
La información detallada sobre los datos está disponible en el siguiente enlace:
https://archive.ics.uci.edu/ml/datasets/banknote+authentication
El siguiente código importa el conjunto de datos:
dataset = pd.read_csv("D:/Datasets/bill_authentication.csv")Para obtener una vista de alto nivel del conjunto de datos, ejecute el siguiente comando:
dataset.head()| Varianza | Curiosidad | Curtosis | Entropía | Clase | |
|---|---|---|---|---|---|
| 0 | 3.62160 | 8,6661 | -2,8073 | -0,44699 | 0 |
| 1 | 4,54590 | 8,1674 | -2,4586 | -1.46210 | 0 |
| 2 | 3,86600 | -2,6383 | 1,9242 | 0,10645 | 0 |
| 9.5228 | -4,0112 | -3,59440 | 0 | ||
| 4 | 0,32924 | -4,4552 | 4,5718 | -0.98880 | 0 |
Al igual que ocurría con el conjunto de datos de regresión, los valores de este conjunto de datos no están muy bien escalados. El conjunto de datos se escalará antes de entrenar el algoritmo.
3. Preparación de los datos para el entrenamiento
El siguiente código divide los datos en atributos y etiquetas:
X = dataset.iloc.valuesy = dataset.iloc.valuesEl siguiente código divide los datos en conjuntos de entrenamiento y prueba:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)4. Escalado de características
Al igual que antes, el escalado de características funciona de la misma manera:
# Feature Scalingfrom sklearn.preprocessing import StandardScalersc = StandardScaler()X_train = sc.fit_transform(X_train)X_test = sc.transform(X_test)5. Entrenando el Algoritmo
Y de nuevo, ahora que hemos escalado nuestro conjunto de datos, podemos entrenar nuestros bosques aleatorios para resolver este problema de clasificación. Para ello, ejecutamos el siguiente código:
from sklearn.ensemble import RandomForestRegressorregressor = RandomForestRegressor(n_estimators=20, random_state=0)regressor.fit(X_train, y_train)y_pred = regressor.predict(X_test)En el caso de la regresión utilizamos la clase RandomForestRegressor de la librería sklearn.ensemble. Para la clasificación, utilizaremos la clase RandomForestClassifier de la librería sklearn.ensemble. La clase RandomForestClassifier también toma n_estimators como parámetro. Como antes, este parámetro define el número de árboles de nuestro bosque aleatorio. Volveremos a empezar con 20 árboles. Puedes encontrar los detalles de todos los parámetros de RandomForestClassifier aquí.
6. Evaluación del Algoritmo
Para los problemas de clasificación, las métricas utilizadas para evaluar un algoritmo son la exactitud, la matriz de confusión, la precisión, el recuerdo y los valores F1. Ejecuta el siguiente script para encontrar estos valores:
from sklearn.metrics import classification_report, confusion_matrix, accuracy_scoreprint(confusion_matrix(y_test,y_pred))print(classification_report(y_test,y_pred))print(accuracy_score(y_test, y_pred))El resultado será algo así:
1 117]] precision recall f1-score support 0 0.99 0.99 0.99 157 1 0.98 0.99 0.99 118 avg / total 0.99 0.99 0.99 2750.989090909091La precisión alcanzada por nuestro clasificador de bosque aleatorio con 20 árboles es del 98,90%. A diferencia de lo anterior, cambiar el número de estimadores para este problema no mejoró significativamente los resultados, como se muestra en el siguiente gráfico. Aquí el eje X contiene el número de estimadores mientras que el eje Y muestra la precisión.
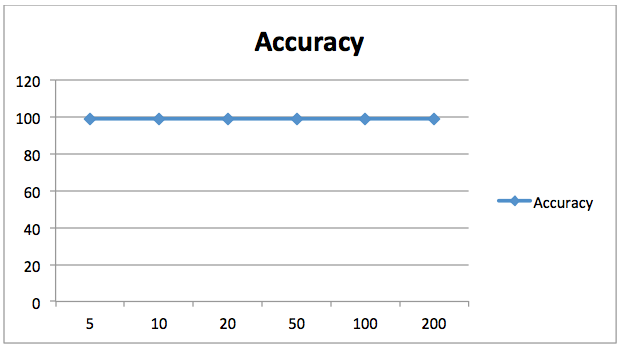
98,90% es una precisión bastante buena, por lo que no tiene mucho sentido aumentar nuestro número de estimadores de todos modos. Podemos ver que aumentar el número de estimadores no mejoró más la precisión.
Para mejorar la precisión, te sugeriría que jugaras con otros parámetros de la clase RandomForestClassifier y ver si puedes mejorar nuestros resultados.
Recursos
¿Quieres aprender más sobre Scikit-Learn y otros algoritmos de aprendizaje automático útiles como los bosques aleatorios? Puedes consultar algunos recursos más detallados, como un curso online:
- Ciencia de datos en Python, Pandas, Scikit-learn, Numpy, Matplotlib
- Python for Data Science and Machine Learning Bootcamp
- Aprendizaje automático A-Z: Hands-On Python & R In Data Science