Algorithme Random Forest avec Python et Scikit-Learn
La forêt aléatoire est un type d’algorithme d’apprentissage automatique supervisé basé sur l’apprentissage d’ensemble. L’apprentissage d’ensemble est un type d’apprentissage où vous joignez différents types d’algorithmes ou le même algorithme plusieurs fois pour former un modèle de prédiction plus puissant. L’algorithme de la forêt aléatoire combine plusieurs algorithmes du même type, c’est-à-dire plusieurs arbres de décision, ce qui donne une forêt d’arbres, d’où le nom de « forêt aléatoire ». L’algorithme de la forêt aléatoire peut être utilisé pour les tâches de régression et de classification.
Comment fonctionne l’algorithme de la forêt aléatoire
Voici les étapes de base de l’exécution de l’algorithme de la forêt aléatoire :
- Prélever N enregistrements aléatoires dans l’ensemble de données.
- Construire un arbre de décision basé sur ces N enregistrements.
- Choisir le nombre d’arbres que vous voulez dans votre algorithme et répéter les étapes 1 et 2.
- Dans le cas d’un problème de régression, pour un nouvel enregistrement, chaque arbre de la forêt prédit une valeur pour Y (sortie). La valeur finale peut être calculée en prenant la moyenne de toutes les valeurs prédites par tous les arbres de la forêt. Ou, dans le cas d’un problème de classification, chaque arbre de la forêt prédit la catégorie à laquelle le nouvel enregistrement appartient. Enfin, le nouvel enregistrement est attribué à la catégorie qui remporte le vote majoritaire.
Avantages de l’utilisation de Random Forest
Comme pour tout algorithme, son utilisation présente des avantages et des inconvénients. Dans les deux prochaines sections, nous allons examiner les avantages et les inconvénients de l’utilisation de la forêt aléatoire pour la classification et la régression.
- L’algorithme de la forêt aléatoire n’est pas biaisé, car, il y a plusieurs arbres et chaque arbre est formé sur un sous-ensemble de données. Fondamentalement, l’algorithme de la forêt aléatoire s’appuie sur le pouvoir de » la foule » ; par conséquent, la partialité globale de l’algorithme est réduite.
- Cet algorithme est très stable. Même si un nouveau point de données est introduit dans l’ensemble de données, l’algorithme global n’est pas beaucoup affecté puisque les nouvelles données peuvent avoir un impact sur un arbre, mais il est très difficile pour lui d’avoir un impact sur tous les arbres.
- L’algorithme de forêt aléatoire fonctionne bien lorsque vous avez à la fois des caractéristiques catégorielles et numériques.
- L’algorithme de la forêt aléatoire fonctionne également bien lorsque les données ont des valeurs manquantes ou qu’elles n’ont pas été bien mises à l’échelle (bien que nous ayons effectué la mise à l’échelle des caractéristiques dans cet article uniquement à des fins de démonstration).
Inconvénients de l’utilisation de la forêt aléatoire
- Un inconvénient majeur des forêts aléatoires réside dans leur complexité. Elles nécessitaient beaucoup plus de ressources informatiques, en raison du grand nombre d’arbres de décision réunis.
- En raison de leur complexité, elles nécessitent beaucoup plus de temps pour s’entraîner que d’autres algorithmes comparables.
Dans la suite de cet article, nous verrons comment la bibliothèque Scikit-Learn de Python peut être utilisée pour mettre en œuvre l’algorithme de la forêt aléatoire afin de résoudre des problèmes de régression, ainsi que de classification.
Partie 1 : Utilisation de Random Forest pour la régression
Dans cette section, nous étudierons comment les forêts aléatoires peuvent être utilisées pour résoudre des problèmes de régression à l’aide de Scikit-Learn. Dans la section suivante, nous résoudrons un problème de classification via les forêts aléatoires.
Définition du problème
Le problème ici est de prédire la consommation d’essence (en millions de gallons) dans 48 des États américains en fonction de la taxe sur l’essence (en cents), du revenu par habitant (dollars), des autoroutes pavées (en miles) et de la proportion de la population ayant le permis de conduire.
Solution
Pour résoudre ce problème de régression, nous allons utiliser l’algorithme de la forêt aléatoire via la bibliothèque Scikit-Learn Python. Nous allons suivre le pipeline traditionnel d’apprentissage automatique pour résoudre ce problème. Suivez ces étapes :
1. Importer les bibliothèques
Exécutez le code suivant pour importer les bibliothèques nécessaires:
import pandas as pdimport numpy as np2. Importation du jeu de données
Le jeu de données pour ce problème est disponible à l’adresse:
https://drive.google.com/file/d/1mVmGNx6cbfvRHC_DvF12ZL3wGLSHD9f_/view
Pour les besoins de ce tutoriel, le jeu de données a été téléchargé dans le dossier « Datasets » du lecteur « D ». Vous devrez modifier le chemin du fichier en fonction de votre propre configuration.
Exécutez la commande suivante pour importer le jeu de données:
dataset = pd.read_csv('D:\Datasets\petrol_consumption.csv')Pour obtenir une vue de haut niveau de ce à quoi ressemble le jeu de données, exécutez la commande suivante :
dataset.head()| Taxe sur l’essence | Revenu moyen | Routes pavées | Population_permis_de_conduire(%) | Consommation_d’essence | |
|---|---|---|---|---|---|
| 0 | 9.0 | 3571 | 1976 | 0,525 | 541 |
| 1 | 9,0 | 4092 | 1250 | 0.572 | 524 |
| 2 | 9,0 | 3865 | 1586 | 0,580 | 561 |
| 3 | 7.5 | 4870 | 2351 | 0,529 | 414 |
| 4 | 8,0 | 4399 | 431 | 0.544 | 410 |
Nous pouvons voir que les valeurs de notre jeu de données ne sont pas très bien mises à l’échelle. Nous allons les mettre à l’échelle avant d’entraîner l’algorithme.
3. Préparation des données pour l’entraînement
Deux tâches seront effectuées dans cette section. La première tâche consiste à diviser les données en ensembles » attributs » et » étiquettes « . Les données résultantes sont ensuite divisées en ensembles de formation et de test.
Le script suivant divise les données en attributs et en étiquettes:
X = dataset.iloc.valuesy = dataset.iloc.valuesEnfin, divisons les données en ensembles de formation et de test:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)4. Mise à l’échelle des fonctionnalités
Nous savons que notre ensemble de données n’est pas encore une valeur mise à l’échelle, par exemple le champ Average_Income a des valeurs de l’ordre de milliers tandis que Petrol_tax a des valeurs de l’ordre de dizaines. Par conséquent, il serait bénéfique de mettre nos données à l’échelle (bien que, comme mentionné précédemment, cette étape ne soit pas aussi importante pour l’algorithme des forêts aléatoires). Pour ce faire, nous allons utiliser la classe StandardScaler de Scikit-Learn. Pour ce faire, exécutez le code suivant :
# Feature Scalingfrom sklearn.preprocessing import StandardScalersc = StandardScaler()X_train = sc.fit_transform(X_train)X_test = sc.transform(X_test)5. Entraînement de l’algorithme
Maintenant que nous avons mis à l’échelle notre ensemble de données, il est temps d’entraîner notre algorithme de forêt aléatoire pour résoudre ce problème de régression. Exécutez le code suivant :
from sklearn.ensemble import RandomForestRegressorregressor = RandomForestRegressor(n_estimators=20, random_state=0)regressor.fit(X_train, y_train)y_pred = regressor.predict(X_test)La classe RandomForestRegressor de la bibliothèque sklearn.ensemble est utilisée pour résoudre les problèmes de régression via la forêt aléatoire. Le paramètre le plus important de la classe RandomForestRegressor est le paramètre n_estimators. Ce paramètre définit le nombre d’arbres dans la forêt aléatoire. Nous allons commencer avec n_estimator=20 pour voir comment notre algorithme se comporte. Vous pouvez trouver les détails de tous les paramètres de RandomForestRegressor ici.
6. Évaluation de l’algorithme
La dernière et dernière étape de la résolution d’un problème d’apprentissage automatique consiste à évaluer les performances de l’algorithme. Pour les problèmes de régression, les métriques utilisées pour évaluer un algorithme sont l’erreur absolue moyenne, l’erreur quadratique moyenne et l’erreur quadratique moyenne. Exécutez le code suivant pour trouver ces valeurs:
from sklearn import metricsprint('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))print('Root Mean Squared Error:', np.sqrt(metrics.mean_squared_error(y_test, y_pred)))La sortie ressemblera à ceci:
Mean Absolute Error: 51.765Mean Squared Error: 4216.16675Root Mean Squared Error: 64.932016371Avec 20 arbres, l’erreur quadratique moyenne est de 64,93, ce qui est supérieur à 10 % de la consommation moyenne d’essence, soit 576,77. Cela peut indiquer, entre autres, que nous n’avons pas utilisé suffisamment d’estimateurs (arbres).
Si le nombre d’estimateurs passe à 200, les résultats sont les suivants :
Mean Absolute Error: 47.9825Mean Squared Error: 3469.7007375Root Mean Squared Error: 58.9041657058Le graphique suivant montre la diminution de la valeur de l’erreur quadratique moyenne (RMSE) en fonction du nombre d’estimateurs. Ici, l’axe X contient le nombre d’estimateurs tandis que l’axe Y contient la valeur de l’erreur quadratique moyenne.
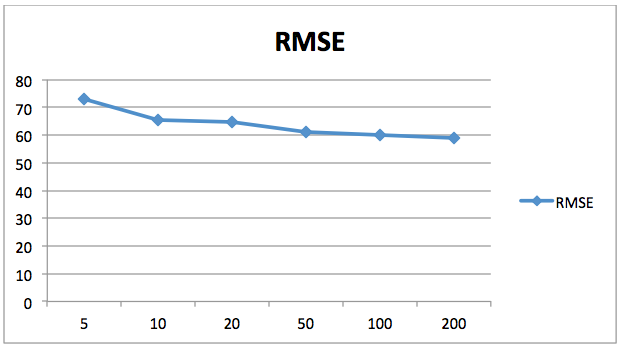
Vous pouvez voir que les valeurs d’erreur diminuent avec l’augmentation du nombre d’estimateurs. Après 200, le taux de diminution de l’erreur diminue, donc 200 est un bon nombre pour n_estimators. Vous pouvez jouer avec le nombre d’arbres et d’autres paramètres pour voir si vous pouvez obtenir de meilleurs résultats par vous-même.
Partie 2 : Utilisation de Random Forest pour la classification
Définition du problème
La tâche ici est de prédire si un billet de banque est authentique ou non en fonction de quatre attributs i.C’est-à-dire la variance de l’image transformée en ondelettes, l’asymétrie, l’entropie et la curtose de l’image.
Solution
Il s’agit d’un problème de classification binaire et nous utiliserons un classificateur de forêt aléatoire pour résoudre ce problème. Les étapes suivies pour résoudre ce problème seront similaires aux étapes réalisées pour la régression.
1. Importer les bibliothèques
import pandas as pdimport numpy as np2. Importation du jeu de données
Le jeu de données peut être téléchargé à partir du lien suivant:
https://drive.google.com/file/d/13nw-uRXPY8XIZQxKRNZ3yYlho-CYm_Qt/view
Les informations détaillées sur les données sont disponibles sur le lien suivant:
https://archive.ics.uci.edu/ml/datasets/banknote+authentication
Le code suivant importe le jeu de données :
dataset = pd.read_csv("D:/Datasets/bill_authentication.csv")Pour obtenir une vue de haut niveau du jeu de données, exécutez la commande suivante :
dataset.head()| Variance | Skewness | Curtosis | Entropie | Classe | |
|---|---|---|---|---|---|
| 0 | 3.62160 | 8,6661 | -2,8073 | -0,44699 | 0 | 1 | 4,54590 | 8,1674 | -2,4586 | -1.46210 | 0 |
| 2 | 3,86600 | -2,6383 | 1,9242 | 0,10645 | 0 | 3 | 3,45660 | 9.5228 | -4,0112 | -3,59440 | 0 | 4 | 0,32924 | -4,4552 | 4,5718 | -0.98880 | 0 |
Comme c’était le cas avec le jeu de données de régression, les valeurs de ce jeu de données ne sont pas très bien mises à l’échelle. Le jeu de données sera mis à l’échelle avant l’entraînement de l’algorithme.
3. Préparation des données pour l’entraînement
Le code suivant divise les données en attributs et en étiquettes:
X = dataset.iloc.valuesy = dataset.iloc.valuesLe code suivant divise les données en ensembles d’entraînement et de test:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)4. Mise à l’échelle des caractéristiques
Comme précédemment, la mise à l’échelle des caractéristiques fonctionne de la même manière:
# Feature Scalingfrom sklearn.preprocessing import StandardScalersc = StandardScaler()X_train = sc.fit_transform(X_train)X_test = sc.transform(X_test)5. Entraînement de l’algorithme
Et encore une fois, maintenant que nous avons mis à l’échelle notre ensemble de données, nous pouvons entraîner nos forêts aléatoires pour résoudre ce problème de classification. Pour ce faire, exécutez le code suivant :
from sklearn.ensemble import RandomForestRegressorregressor = RandomForestRegressor(n_estimators=20, random_state=0)regressor.fit(X_train, y_train)y_pred = regressor.predict(X_test)Dans le cas de la régression, nous avons utilisé la classe RandomForestRegressor de la bibliothèque sklearn.ensemble. Pour la classification, nous allons RandomForestClassifier classe de la bibliothèque sklearn.ensemble. La classe RandomForestClassifier prend également n_estimators comme paramètre. Comme précédemment, ce paramètre définit le nombre d’arbres de notre forêt aléatoire. Nous allons à nouveau commencer avec 20 arbres. Vous pouvez trouver les détails de tous les paramètres de RandomForestClassifier ici.
6. Évaluation de l’algorithme
Pour les problèmes de classification, les métriques utilisées pour évaluer un algorithme sont la précision, la matrice de confusion, le rappel de précision et les valeurs F1. Exécutez le script suivant pour trouver ces valeurs:
from sklearn.metrics import classification_report, confusion_matrix, accuracy_scoreprint(confusion_matrix(y_test,y_pred))print(classification_report(y_test,y_pred))print(accuracy_score(y_test, y_pred))La sortie ressemblera à ceci:
1 117]] precision recall f1-score support 0 0.99 0.99 0.99 157 1 0.98 0.99 0.99 118 avg / total 0.99 0.99 0.99 2750.989090909091La précision obtenue pour par notre classificateur de forêt aléatoire avec 20 arbres est de 98,90%. Contrairement à ce qui se passait auparavant, le fait de changer le nombre d’estimateurs pour ce problème n’a pas amélioré les résultats de manière significative, comme le montre le graphique suivant. Ici, l’axe des X contient le nombre d’estimateurs tandis que l’axe des Y montre la précision.
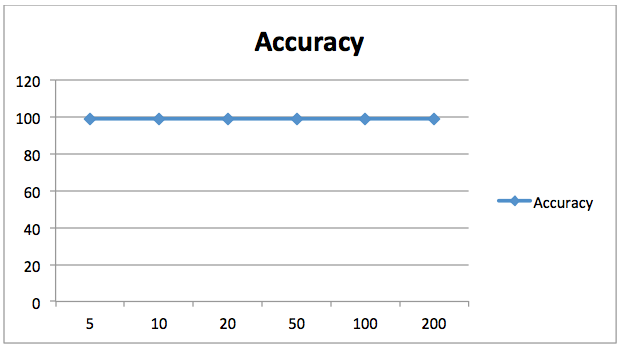
98,90% est une assez bonne précision, donc il n’y a pas beaucoup d’intérêt à augmenter notre nombre d’estimateurs de toute façon. Nous pouvons voir que l’augmentation du nombre d’estimateurs n’a pas amélioré davantage la précision.
Pour améliorer la précision, je vous suggère de jouer avec d’autres paramètres de la classe RandomForestClassifier et de voir si vous pouvez améliorer nos résultats.
Ressources
Vous voulez en savoir plus sur Scikit-Learn et d’autres algorithmes d’apprentissage automatique utiles comme les forêts aléatoires ? Vous pouvez consulter des ressources plus détaillées, comme un cours en ligne :
- Science des données en Python, Pandas, Scikit-learn, Numpy, Matplotlib
- Python pour la science des données et l’apprentissage automatique Bootcamp
- L’apprentissage automatique de A à Z : Hands-On Python & R In Data Science
.