Algoritmo Random Forest con Python e Scikit-Learn
Random forest è un tipo di algoritmo di apprendimento automatico supervisionato basato sull’apprendimento in ensemble. L’ensemble learning è un tipo di apprendimento in cui si uniscono diversi tipi di algoritmi o lo stesso algoritmo più volte per formare un modello di predizione più potente. L’algoritmo della foresta casuale combina più algoritmi dello stesso tipo, cioè più alberi decisionali, ottenendo una foresta di alberi, da cui il nome “Random Forest”. L’algoritmo della foresta casuale può essere usato sia per compiti di regressione che di classificazione.
Come funziona l’algoritmo della foresta casuale
Questi sono i passi fondamentali coinvolti nell’esecuzione dell’algoritmo della foresta casuale:
- Prendi N record casuali dal set di dati.
- Costruisci un albero decisionale basato su questi N record.
- Scegli il numero di alberi che vuoi nel tuo algoritmo e ripeti i passi 1 e 2.
- In caso di un problema di regressione, per un nuovo record, ogni albero della foresta predice un valore per Y (output). Il valore finale può essere calcolato prendendo la media di tutti i valori predetti da tutti gli alberi della foresta. Oppure, nel caso di un problema di classificazione, ogni albero della foresta predice la categoria a cui appartiene il nuovo record. Infine, il nuovo record viene assegnato alla categoria che vince il voto di maggioranza.
Svantaggi dell’uso di Random Forest
Come ogni algoritmo, ci sono vantaggi e svantaggi nell’usarlo. Nelle prossime due sezioni daremo un’occhiata ai pro e ai contro dell’uso della foresta casuale per la classificazione e la regressione.
- L’algoritmo della foresta casuale non è distorto, poiché ci sono più alberi e ogni albero è addestrato su un sottoinsieme di dati. Fondamentalmente, l’algoritmo della foresta casuale si basa sul potere della “folla”; quindi la parzialità complessiva dell’algoritmo è ridotta.
- Questo algoritmo è molto stabile. Anche se un nuovo punto di dati viene introdotto nel set di dati, l’algoritmo complessivo non viene influenzato molto, poiché i nuovi dati possono avere un impatto su un albero, ma è molto difficile che abbiano un impatto su tutti gli alberi.
- L’algoritmo della foresta casuale funziona bene quando si hanno sia caratteristiche categoriche che numeriche.
- L’algoritmo della foresta casuale funziona bene anche quando i dati hanno valori mancanti o non sono stati scalati bene (anche se abbiamo eseguito lo scaling delle caratteristiche in questo articolo solo a scopo dimostrativo).
Svantaggi dell’uso della foresta casuale
- Un grande svantaggio delle foreste casuali sta nella loro complessità. Richiedono molte più risorse computazionali, a causa del grande numero di alberi decisionali uniti insieme.
- A causa della loro complessità, richiedono molto più tempo per addestrare rispetto ad altri algoritmi comparabili.
Nel resto di questo articolo vedremo come la libreria Scikit-Learn di Python può essere usata per implementare l’algoritmo della foresta casuale per risolvere problemi di regressione, così come di classificazione.
Parte 1: Uso della foresta casuale per la regressione
In questa sezione studieremo come le foreste casuali possono essere usate per risolvere problemi di regressione usando Scikit-Learn. Nella prossima sezione risolveremo il problema di classificazione tramite le foreste casuali.
Definizione del problema
Il problema qui è prevedere il consumo di benzina (in milioni di galloni) in 48 stati degli USA basandosi sulla tassa sulla benzina (in centesimi), sul reddito pro capite (dollari), sulle autostrade asfaltate (in miglia) e sulla percentuale di popolazione con la patente.
Soluzione
Per risolvere questo problema di regressione useremo l’algoritmo random forest tramite la libreria Scikit-Learn Python. Seguiremo la tradizionale pipeline di machine learning per risolvere questo problema. Segui questi passi:
1. Importare le librerie
Eseguire il seguente codice per importare le librerie necessarie:
import pandas as pdimport numpy as np2. Importare il dataset
Il dataset per questo problema è disponibile su:
https://drive.google.com/file/d/1mVmGNx6cbfvRHC_DvF12ZL3wGLSHD9f_/view
Per il bene di questo tutorial, il dataset è stato scaricato nella cartella “Datasets” del drive “D”. Dovrete cambiare il percorso del file in base alla vostra configurazione.
Esegui il seguente comando per importare il dataset:
dataset = pd.read_csv('D:\Datasets\petrol_consumption.csv')Per avere una visione di alto livello di come appare il dataset, esegui il seguente comando:
dataset.head()| Tassa_petrolio | Reddito_medio | Strade_pavimentate | Popolazione_conducente(%) | Consumo_di_benzina | |
|---|---|---|---|---|---|
| 0 | 9.0 | 3571 | 1976 | 0.525 | 541 |
| 1 | 9.0 | 4092 | 1250 | 0.572 | 524 |
| 2 | 9.0 | 3865 | 1586 | 0.580 | 561 |
| 3 | 7.5 | 4870 | 2351 | 0.529 | 414 |
| 4 | 8.0 | 4399 | 431 | 0.544 | 410 |
Possiamo vedere che i valori nel nostro dataset non sono molto ben scalati. Li ridimensioneremo prima di addestrare l’algoritmo.
3. Preparazione dei dati per l’addestramento
In questa sezione verranno eseguiti due compiti. Il primo compito è quello di dividere i dati in set di ‘attributi’ e ‘etichette’. I dati risultanti vengono poi divisi in insiemi di allenamento e di test.
Il seguente script divide i dati in attributi ed etichette:
X = dataset.iloc.valuesy = dataset.iloc.valuesFinalmente, dividiamo i dati in insiemi di allenamento e di test:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)4. Feature Scaling
Sappiamo che il nostro set di dati non è ancora un valore scalato, per esempio il campo Average_Income ha valori nell’ordine delle migliaia mentre Petrol_tax ha valori nell’ordine delle decine. Pertanto, sarebbe utile scalare i nostri dati (anche se, come detto prima, questo passo non è così importante per l’algoritmo delle foreste casuali). Per farlo, useremo la classe StandardScaler di Scikit-Learn. Eseguite il seguente codice per farlo:
# Feature Scalingfrom sklearn.preprocessing import StandardScalersc = StandardScaler()X_train = sc.fit_transform(X_train)X_test = sc.transform(X_test)5. Addestrare l’algoritmo
Ora che abbiamo scalato il nostro set di dati, è il momento di addestrare il nostro algoritmo random forest per risolvere questo problema di regressione. Eseguite il seguente codice:
from sklearn.ensemble import RandomForestRegressorregressor = RandomForestRegressor(n_estimators=20, random_state=0)regressor.fit(X_train, y_train)y_pred = regressor.predict(X_test)La classe RandomForestRegressor della libreria sklearn.ensemble è utilizzata per risolvere i problemi di regressione tramite la foresta casuale. Il parametro più importante della classe RandomForestRegressor è il parametro n_estimators. Questo parametro definisce il numero di alberi nella foresta casuale. Inizieremo con n_estimator=20 per vedere come si comporta il nostro algoritmo. Puoi trovare i dettagli per tutti i parametri di RandomForestRegressor qui.
6. Valutazione dell’algoritmo
L’ultimo e ultimo passo per risolvere un problema di apprendimento automatico è quello di valutare le prestazioni dell’algoritmo. Per i problemi di regressione le metriche usate per valutare un algoritmo sono l’errore assoluto medio, l’errore quadratico medio e l’errore quadratico medio. Eseguite il seguente codice per trovare questi valori:
from sklearn import metricsprint('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))print('Root Mean Squared Error:', np.sqrt(metrics.mean_squared_error(y_test, y_pred)))L’output sarà qualcosa di simile a questo:
Mean Absolute Error: 51.765Mean Squared Error: 4216.16675Root Mean Squared Error: 64.932016371Con 20 alberi, l’errore quadratico medio di radice è 64,93 che è maggiore del 10% del consumo medio di benzina cioè 576,77. Questo può indicare, tra le altre cose, che non abbiamo usato abbastanza stimatori (alberi).
Se il numero di stimatori viene cambiato a 200, i risultati sono i seguenti:
Mean Absolute Error: 47.9825Mean Squared Error: 3469.7007375Root Mean Squared Error: 58.9041657058Il grafico seguente mostra la diminuzione del valore dell’errore quadratico medio (RMSE) rispetto al numero di stimatori. Qui l’asse X contiene il numero di stimatori mentre l’asse Y contiene il valore dell’errore quadratico medio.
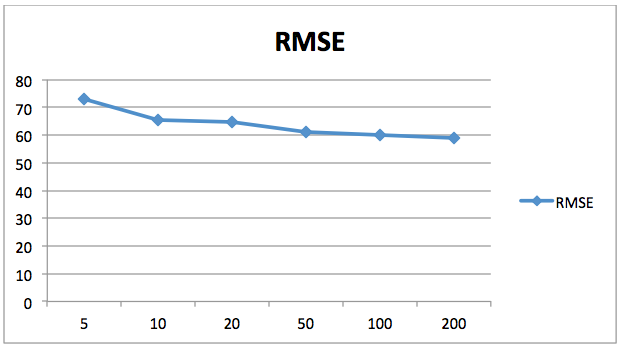
Si può vedere che i valori di errore diminuiscono con l’aumento del numero di stimatori. Dopo 200 il tasso di diminuzione dell’errore diminuisce, quindi 200 è un buon numero per n_estimators. Puoi giocare con il numero di alberi e altri parametri per vedere se puoi ottenere risultati migliori per conto tuo.
Parte 2: Usare Random Forest per la classificazione
Definizione del problema
Il compito qui è prevedere se una banconota è autentica o meno in base a quattro attributi i.e. varianza dell’immagine trasformata wavelet, skewness, entropia e curtosi dell’immagine.
Soluzione
Questo è un problema di classificazione binaria e useremo un classificatore di foresta casuale per risolvere questo problema. I passi seguiti per risolvere questo problema saranno simili a quelli eseguiti per la regressione.
1. Importare le librerie
import pandas as pdimport numpy as np2. Importare il dataset
Il dataset può essere scaricato dal seguente link:
https://drive.google.com/file/d/13nw-uRXPY8XIZQxKRNZ3yYlho-CYm_Qt/view
Le informazioni dettagliate sui dati sono disponibili al seguente link:
https://archive.ics.uci.edu/ml/datasets/banknote+authentication
Il seguente codice importa il dataset:
dataset = pd.read_csv("D:/Datasets/bill_authentication.csv")Per ottenere una vista di alto livello del dataset, esegui il seguente comando:
dataset.head()| Varianza | Skewness | Curtosi | Entropia | Classe | |
|---|---|---|---|---|---|
| 0 | 3.62160 | 8.6661 | -2.8073 | -0.44699 | 0 |
| 1 | 4.54590 | 8.1674 | -2.4586 | -1.46210 | 0 |
| 2 | 3.86600 | -2.6383 | 1.9242 | 0.10645 | 0 |
| 3 | 3.45660 | 9.5228 | -4.0112 | -3.59440 | 0 |
| 4 | 0.32924 | -4.4552 | 4.5718 | -0.98880 | 0 |
Come nel caso del dataset di regressione, i valori in questo dataset non sono molto ben scalati. Il dataset sarà scalato prima di addestrare l’algoritmo.
3. Preparazione dei dati per l’addestramento
Il seguente codice divide i dati in attributi ed etichette:
X = dataset.iloc.valuesy = dataset.iloc.valuesIl seguente codice divide i dati in set di allenamento e test:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)4. Feature Scaling
Come in precedenza, il feature scaling funziona allo stesso modo:
# Feature Scalingfrom sklearn.preprocessing import StandardScalersc = StandardScaler()X_train = sc.fit_transform(X_train)X_test = sc.transform(X_test)5. Addestrare l’algoritmo
E di nuovo, ora che abbiamo scalato il nostro set di dati, possiamo addestrare le nostre foreste casuali per risolvere questo problema di classificazione. Per farlo, eseguite il seguente codice:
from sklearn.ensemble import RandomForestRegressorregressor = RandomForestRegressor(n_estimators=20, random_state=0)regressor.fit(X_train, y_train)y_pred = regressor.predict(X_test)In caso di regressione abbiamo usato la classe RandomForestRegressor della libreria sklearn.ensemble. Per la classificazione, abbiamo RandomForestClassifier classe della libreria sklearn.ensemble. La classe RandomForestClassifier prende anche n_estimators come parametro. Come prima, questo parametro definisce il numero di alberi nella nostra foresta casuale. Inizieremo di nuovo con 20 alberi. Potete trovare i dettagli per tutti i parametri di RandomForestClassifier qui.
6. Valutazione dell’algoritmo
Per i problemi di classificazione le metriche usate per valutare un algoritmo sono l’accuratezza, la matrice di confusione, la precisione, il richiamo e i valori F1. Eseguite il seguente script per trovare questi valori:
from sklearn.metrics import classification_report, confusion_matrix, accuracy_scoreprint(confusion_matrix(y_test,y_pred))print(classification_report(y_test,y_pred))print(accuracy_score(y_test, y_pred))L’output sarà simile a questo:
1 117]] precision recall f1-score support 0 0.99 0.99 0.99 157 1 0.98 0.99 0.99 118 avg / total 0.99 0.99 0.99 2750.989090909091L’accuratezza raggiunta dal nostro classificatore random forest con 20 alberi è del 98,90%. A differenza di prima, cambiare il numero di stimatori per questo problema non ha migliorato significativamente i risultati, come mostrato nel grafico seguente. Qui l’asse X contiene il numero di stimatori mentre l’asse Y mostra l’accuratezza.
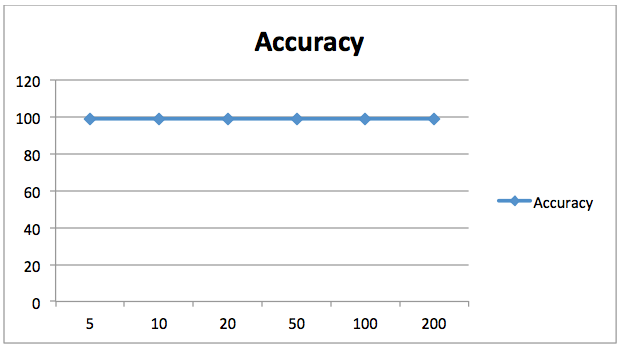
98.90% è un’accuratezza abbastanza buona, quindi non ha molto senso aumentare il nostro numero di stimatori. Possiamo vedere che aumentare il numero di stimatori non ha migliorato ulteriormente l’accuratezza.
Per migliorare l’accuratezza, vi suggerirei di giocare con altri parametri della classe RandomForestClassifier e vedere se potete migliorare i nostri risultati.
Risorse
Vuoi saperne di più su Scikit-Learn e altri utili algoritmi di apprendimento automatico come le foreste casuali? Puoi controllare alcune risorse più dettagliate, come un corso online:
- Data Science in Python, Pandas, Scikit-learn, Numpy, Matplotlib
- Python for Data Science and Machine Learning Bootcamp
- Machine Learning A-Z: Hands-On Python & R In Data Science