Boolean World

La commande top permet aux utilisateurs de surveiller les processus et l’utilisation des ressources système sous Linux. C’est l’un des outils les plus utiles de la boîte à outils d’un sysadmin, et elle est préinstallée sur chaque distribution. Contrairement à d’autres commandes telles que ps, elle est interactive, et vous pouvez parcourir la liste des processus, tuer un processus, et ainsi de suite.
Dans cet article, nous allons comprendre comment utiliser la commande top.
Démarrer
Comme vous l’avez peut-être déjà deviné, il suffit de taper ceci pour lancer top:
top
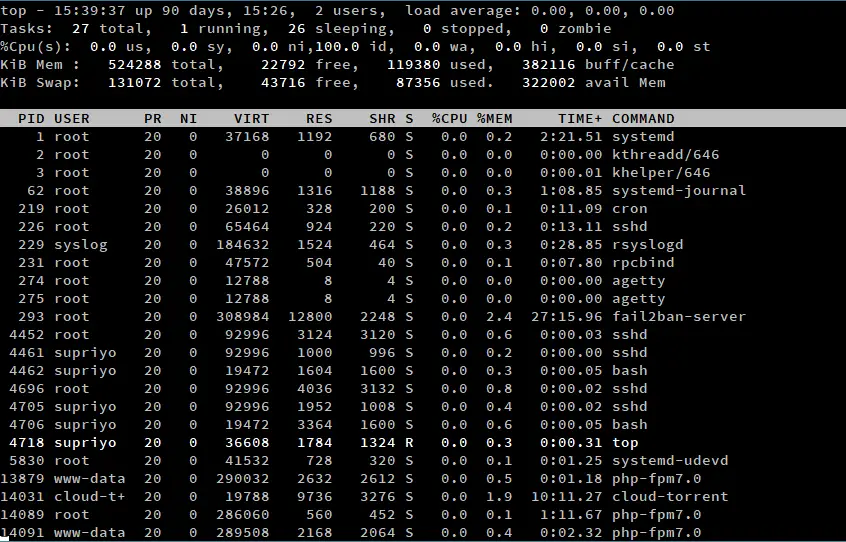
Ceci démarre une application interactive en ligne de commande, semblable à une dans la capture d’écran ci-dessous. La moitié supérieure de la sortie contient des statistiques sur les processus et l’utilisation des ressources, tandis que la moitié inférieure contient une liste des processus en cours d’exécution. Vous pouvez utiliser les touches fléchées et les touches Page Up/Down pour parcourir la liste. Si vous voulez quitter, appuyez simplement sur « q ».
Il existe un certain nombre de variantes de top, mais dans la suite de cet article, nous parlerons de la variante la plus courante – celle qui est fournie avec le paquet « procps-ng ». Vous pouvez vérifier cela en exécutant :
top -v
Si vous avez cette variante, cela apparaîtra dans la sortie, comme ceci :
procps-ng version 3.3.10
Il se passe pas mal de choses dans l’interface de top, nous allons donc la décomposer petit à petit dans la section suivante.
Comprendre l’interface de top : la zone de résumé
Comme nous l’avons vu précédemment, la sortie de top est divisée en deux sections différentes. Dans cette partie de l’article, nous allons nous concentrer sur les éléments de la moitié de la sortie. Cette région est également appelée « zone de résumé ».
Heure système, temps de fonctionnement et sessions utilisateur

Tout en haut à gauche de l’écran (comme indiqué dans la capture d’écran ci-dessus), top affiche l’heure actuelle. Elle est suivie de l’uptime du système, qui nous indique le temps pendant lequel le système a fonctionné. Par exemple, dans notre exemple, l’heure actuelle est « 15:39:37 », et le système fonctionne depuis 90 jours, 15 heures et 26 minutes.
Vient ensuite le nombre de sessions utilisateur actives. Dans cet exemple, il y a deux sessions utilisateur actives. Ces sessions peuvent être effectuées soit sur un TTY (physiquement sur le système, soit par la ligne de commande ou un environnement de bureau), soit sur un PTY (comme une fenêtre d’émulateur de terminal ou par SSH). En fait, si vous vous connectez à un système Linux via un environnement de bureau, puis lancez un émulateur de terminal, vous constaterez qu’il y aura deux sessions actives.
Si vous voulez obtenir plus de détails sur les sessions utilisateur actives, utilisez la commande who.
Utilisation de la mémoire

La section « mémoire » présente des informations concernant l’utilisation de la mémoire du système. Les lignes marquées « Mem » et « Swap » montrent les informations concernant respectivement la mémoire vive et l’espace swap. En termes simples, un espace d’échange est une partie du disque dur qui est utilisée comme la RAM. Lorsque la RAM est presque pleine, les régions peu utilisées de la RAM sont écrites dans l’espace d’échange, prêtes à être récupérées plus tard en cas de besoin. Cependant, comme l’accès aux disques est lent, le fait de trop compter sur l’espace d’échange peut nuire aux performances du système.
Comme vous vous y attendez naturellement, les valeurs « total », « libre » et « utilisé » ont leurs significations habituelles. La valeur « avail mem » est la quantité de mémoire qui peut être allouée aux processus sans provoquer davantage de swapping.
Le noyau Linux tente également de réduire les temps d’accès au disque de diverses manières. Il maintient un « cache disque » en RAM, où sont stockées les régions du disque fréquemment utilisées. En outre, les écritures sur le disque sont stockées dans un « tampon de disque », et le noyau les écrit éventuellement sur le disque. La mémoire totale consommée par ces opérations est la valeur « buff/cache ». Cela peut sembler être une mauvaise chose, mais ce n’est pas vraiment le cas – la mémoire utilisée par le cache sera allouée aux processus si nécessaire.
Tâches

La section « Tâches » présente des statistiques concernant les processus en cours d’exécution sur votre système. La valeur « total » correspond simplement au nombre total de processus. Par exemple, dans la capture d’écran ci-dessus, il y a 27 processus en cours d’exécution. Pour comprendre le reste des valeurs, nous avons besoin d’un peu de contexte sur la façon dont le noyau Linux gère les processus.
Les processus effectuent un mélange de travail lié aux E/S (comme la lecture des disques) et de travail lié au CPU (comme l’exécution d’opérations arithmétiques). Le CPU est inactif lorsqu’un processus effectue des E/S, les OS passent donc à l’exécution d’autres processus pendant ce temps. En outre, le système d’exploitation permet à un processus donné de s’exécuter pendant une très courte période, puis il passe à un autre processus. C’est ainsi que les systèmes d’exploitation donnent l’impression d’être « multitâches ». Pour faire tout cela, nous devons garder la trace de l' »état » d’un processus. Dans Linux, un processus peut être dans l’un de ces états:
- Runnable (R) : Un processus dans cet état est soit en train de s’exécuter sur l’unité centrale, soit présent sur la file d’attente d’exécution, prêt à être exécuté.
- Sommeil interruptible (S) : Les processus dans cet état attendent qu’un événement se termine.
- Sommeil ininterrompu (D) : Dans ce cas, un processus attend qu’une opération d’entrée/sortie se termine.
- Stopped (T) : Ces processus ont été arrêtés par un signal de contrôle de travail (comme en appuyant sur Ctrl+Z) ou parce qu’ils sont tracés.
- Zombie (Z) : Le noyau maintient diverses structures de données en mémoire pour garder la trace des processus. Un processus peut créer un certain nombre de processus enfants, et ceux-ci peuvent sortir alors que le parent est toujours là. Cependant, ces structures de données doivent être conservées jusqu’à ce que le parent obtienne le statut des processus enfants. Ces processus terminés dont les structures de données sont toujours là sont appelés zombies.
Les processus dans les états D et S sont représentés par « sleeping », et ceux dans l’état T sont représentés par « stopped ». Le nombre de zombies est indiqué par la valeur « zombie ».
Utilisation du CPU

La section d’utilisation du CPU indique le pourcentage de temps du CPU consacré à diverses tâches. La valeur us correspond au temps que le CPU passe à exécuter des processus en espace utilisateur. De même, la valeur sy est le temps passé à exécuter des processus en espace noyau.
Linux utilise une valeur « nice » pour déterminer la priorité d’un processus. Un processus avec une valeur « nice » élevée est « plus gentil » avec les autres processus, et obtient une faible priorité. De la même manière, les processus avec une valeur « nice » plus faible obtiennent une priorité plus élevée. Comme nous le verrons plus tard, la valeur par défaut de « nice » peut être modifiée. Le temps passé à exécuter des processus avec un « nice » défini manuellement apparaît comme la valeur ni.
Ceci est suivi par id, qui est le temps pendant lequel le CPU reste inactif. La plupart des systèmes d’exploitation mettent le processeur en mode d’économie d’énergie lorsqu’il est inactif. Vient ensuite la valeur wa, qui est le temps que le CPU passe à attendre que les E/S se terminent.
Les interruptions sont des signaux envoyés au processeur à propos d’un événement qui nécessite une attention immédiate. Les interruptions matérielles sont généralement utilisées par les périphériques pour informer le système d’événements, tels qu’une pression sur une touche du clavier. D’autre part, les interruptions logicielles sont générées par des instructions spécifiques exécutées sur le processeur. Dans les deux cas, le système d’exploitation les gère, et le temps passé à gérer les interruptions matérielles et logicielles est donné par hi et si respectivement.
Dans un environnement virtualisé, une partie des ressources du processeur est donnée à chaque machine virtuelle (VM). Le système d’exploitation détecte quand il a des travaux à effectuer, mais il ne peut pas les réaliser parce que le CPU est occupé sur une autre VM. La quantité de temps ainsi perdue est le temps « volé », représenté par st.
Moyenne de la charge

La section moyenne de la charge représente la « charge » moyenne sur une, cinq et quinze minutes. « La charge » est une mesure de la quantité de travail de calcul effectuée par un système. Sur Linux, la charge correspond au nombre de processus dans les états R et D à un moment donné. La valeur de « charge moyenne » vous donne une mesure relative du temps que vous devez attendre pour que les choses soient faites.
Prenons quelques exemples pour comprendre ce concept. Sur un système à un seul cœur, une moyenne de charge de 0,4 signifie que le système n’effectue que 40 % du travail qu’il peut faire. Une moyenne de charge de 1 signifie que le système est exactement à sa capacité – le système sera surchargé en ajoutant même un tout petit peu de travail supplémentaire. Un système avec une moyenne de charge de 2,12 signifie qu’il est surchargé par 112 % de travail supplémentaire qu’il ne peut pas gérer.
Sur un système multicœur, vous devez d’abord diviser la moyenne de charge avec le nombre de cœurs du processeur pour obtenir une mesure similaire.
En outre, la « moyenne de charge » n’est pas réellement la « moyenne » typique que la plupart d’entre nous connaissent. Il s’agit d’une « moyenne mobile exponentielle », ce qui signifie qu’une petite partie des moyennes de charge précédentes sont prises en compte dans la valeur actuelle. Si cela vous intéresse, cet article couvre tous les détails techniques.
Comprendre l’interface de top : la zone des tâches
La zone de résumé est comparativement plus simple, et elle contient une liste de processus. Dans cette section, nous allons apprendre les différentes colonnes affichées dans la sortie par défaut de top.
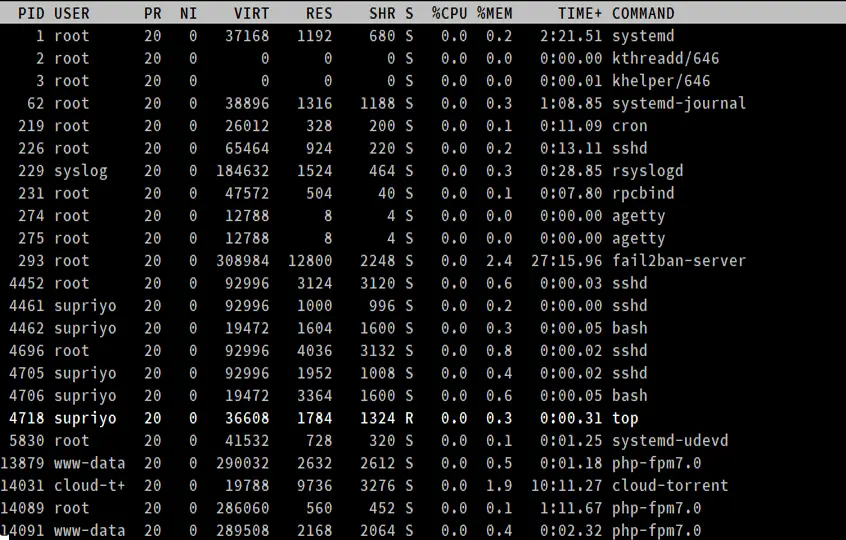
- PID
Il s’agit de l’ID du processus, un entier positif unique qui identifie un processus.
- USER
C’est le nom d’utilisateur « effectif » (qui correspond à un ID utilisateur) de l’utilisateur qui a lancé le processus. Linux attribue un ID utilisateur réel et un ID utilisateur effectif aux processus ; ce dernier permet à un processus d’agir au nom d’un autre utilisateur. (Par exemple, un utilisateur non root peut s’élever au rang de root afin d’installer un paquet.)
- PR et NI
Le champ « NI » indique la valeur « nice » d’un processus. Le champ « PR » indique la priorité d’ordonnancement du processus du point de vue du noyau. La valeur « nice » affecte la priorité d’un processus.
- VIRT, RES, SHR et %MEM
Ces trois champs sont liés avec à la consommation de mémoire des processus. « VIRT » est la quantité totale de mémoire consommée par un processus. Cela inclut le code du programme, les données stockées par le processus en mémoire, ainsi que toutes les régions de la mémoire qui ont été échangées sur le disque. « RES » est la mémoire consommée par le processus en RAM, et « %MEM » exprime cette valeur en pourcentage de la RAM totale disponible. Enfin, « SHR » est la quantité de mémoire partagée avec d’autres processus.
- S
Comme nous l’avons vu précédemment, un processus peut être dans différents états. Ce champ indique l’état du processus sous la forme d’une lettre unique.
- TIME+
Il s’agit du temps total de CPU utilisé par le processus depuis son démarrage, précis au centième de seconde.
- COMMAND
La colonne COMMAND indique le nom des processus.
Exemples d’utilisation de la commande top
Jusqu’ici, nous avons abordé l’interface de top. Cependant, il peut également gérer des processus, et vous pouvez contrôler divers aspects de la sortie de top. Dans cette section, nous allons prendre quelques exemples.
Dans la plupart des exemples ci-dessous, vous devez appuyer sur une touche pendant l’exécution de top. Gardez à l’esprit que ces pressions de touche sont sensibles à la casse – donc si vous appuyez sur « k » alors que le verrouillage des majuscules est activé, vous avez réellement appuyé sur un « K », et la commande ne fonctionnera pas, ou fera quelque chose d’entièrement différent.
Tuer des processus
Si vous voulez tuer un processus, appuyez simplement sur ‘k’ lorsque top est en cours d’exécution. Cela fera apparaître une invite, qui demandera l’ID du processus et appuiera sur ‘enter’.
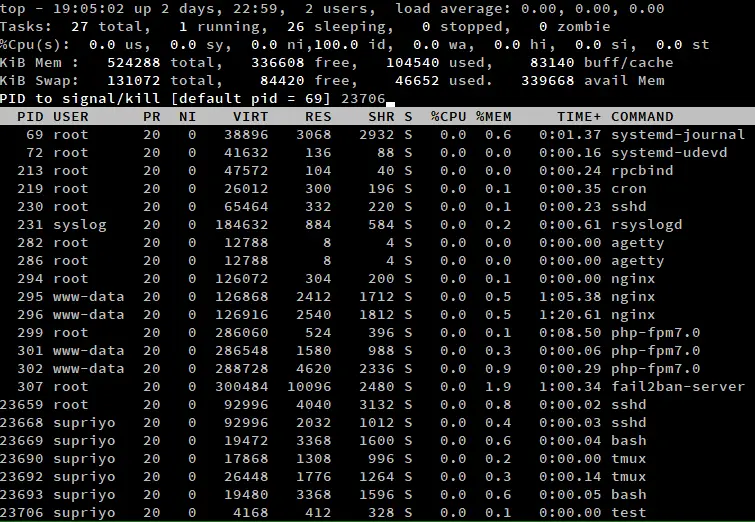
Puis, entrez le signal à l’aide duquel le processus doit être tué. Si vous laissez ce champ vide, top utilise un SIGTERM, qui permet aux processus de se terminer de manière gracieuse. Si vous voulez tuer un processus de force, vous pouvez taper SIGKILL ici. Vous pouvez également saisir le numéro du signal ici. Par exemple, le numéro de SIGTERM est 15 et celui de SIGKILL est 9.
Si vous laissez l’ID du processus vide et que vous appuyez directement sur la touche Entrée, cela mettra fin au processus le plus haut dans la liste. Comme nous l’avons mentionné précédemment, vous pouvez faire défiler la liste à l’aide des touches fléchées, et changer le processus que vous voulez tuer de cette façon.
Tri de la liste des processus
L’une des raisons les plus fréquentes d’utiliser un outil comme top est de savoir quel processus consomme le plus de ressources. Vous pouvez appuyer sur les touches suivantes pour trier la liste :
- « M » pour trier par utilisation de la mémoire
- « P » pour trier par utilisation du CPU
- « N » pour trier par ID de processus
- « T » pour trier par le temps d’exécution
Par défaut, top affiche tous les résultats par ordre décroissant. Cependant, vous pouvez passer à l’ordre ascendant en appuyant sur ‘R’.
Vous pouvez également trier la liste avec le commutateur -o. Par exemple, si vous voulez trier les processus par utilisation du CPU, vous pouvez le faire avec :
top -o %CPU
Vous pouvez trier la liste par n’importe quel attribut dans la zone de résumé de la même manière.
Affichage d’une liste de threads au lieu de processus
Nous avons précédemment abordé la façon dont Linux passe d’un processus à l’autre. Malheureusement, les processus ne partagent pas la mémoire ou d’autres ressources, ce qui rend ces commutations plutôt lentes. Linux, comme de nombreux autres systèmes d’exploitation, prend en charge une alternative « légère », appelée « thread ». Ils font partie d’un processus et partagent certaines régions de mémoire et d’autres ressources, mais ils peuvent être exécutés simultanément comme les processus.
Par défaut, top affiche une liste de processus dans sa sortie. Si vous voulez lister les threads à la place, appuyez sur ‘H’ lorsque top est en cours d’exécution. Remarquez que la ligne « Tâches » dit « Threads » à la place, et affiche le nombre de threads au lieu des processus.
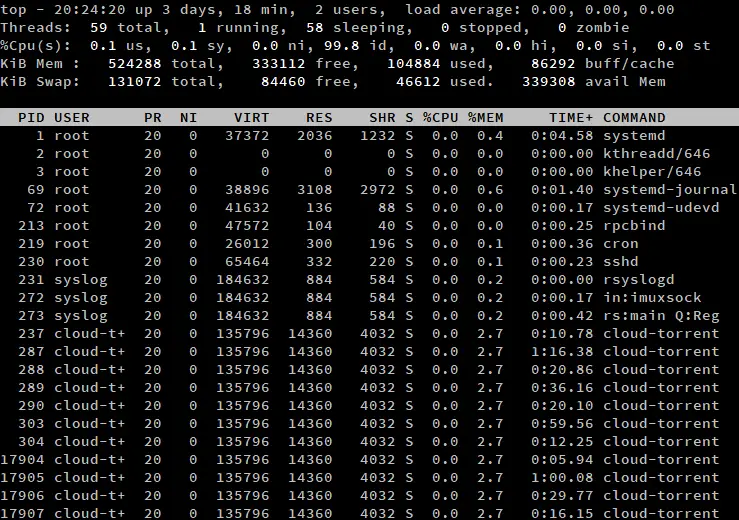
Vous avez peut-être remarqué qu’aucun des attributs de la liste des processus n’a changé. Comment cela est-il possible, étant donné que les processus diffèrent des threads ? À l’intérieur du noyau Linux, les threads et les processus sont gérés à l’aide des mêmes structures de données. Ainsi, chaque thread a son propre ID, son propre état et ainsi de suite.
Si vous voulez revenir à la vue des processus, appuyez à nouveau sur ‘H’. En outre, vous pouvez utiliser le commutateur -H pour afficher les threads par défaut.
top -H
Affichage des chemins complets
Par défaut, top n’affiche pas le chemin complet du programme, ni ne fait de distinction entre les processus en espace noyau et les processus en espace utilisateur. Si vous avez besoin de ces informations, appuyez sur ‘c’ lorsque top est en cours d’exécution. Appuyez à nouveau sur ‘c’ pour revenir à la valeur par défaut.
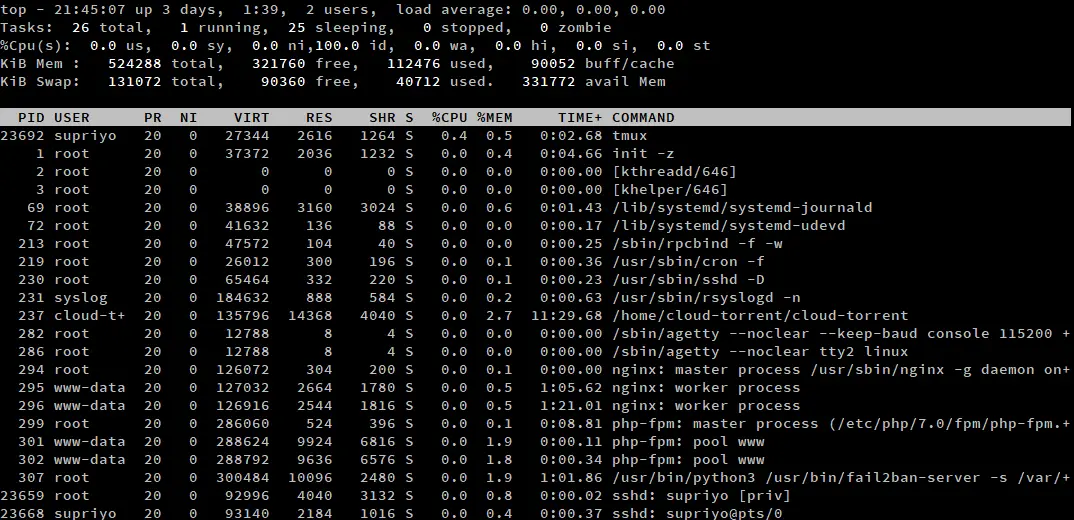
Les processus en espace noyau sont marqués par des crochets autour d’eux. À titre d’exemple, dans la capture d’écran ci-dessus, il y a deux processus du noyau, kthreadd et khelper. Sur la plupart des installations Linux, il y en aura généralement un peu plus.
Alternativement, vous pouvez également démarrer top avec l’argument -c:
top -c
Vue forestière
Parfois, vous pouvez vouloir voir la hiérarchie enfant-parent des processus. Vous pouvez voir cela avec la vue forestière, en appuyant sur ‘v’/’V’ lorsque top est en cours d’exécution.
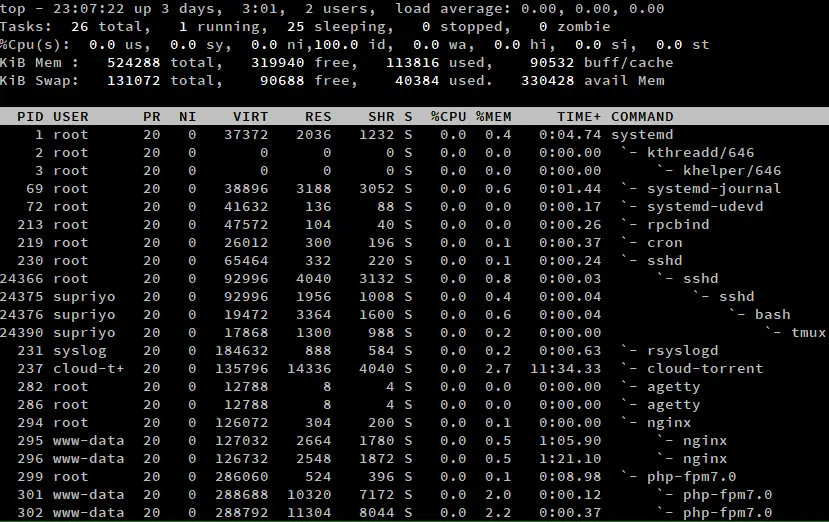
Comme vous pouvez le voir sur la capture d’écran ci-dessus, le processus systemd a été le premier à démarrer sur le système. Il a lancé des processus tels que sshd, qui ont à leur tour créé d’autres processus sshd, et ainsi de suite.
Lister les processus d’un utilisateur
Pour lister les processus d’un certain utilisateur, appuyez sur ‘u’ lorsque top est en cours d’exécution. Ensuite, tapez le nom d’utilisateur, ou laissez-le vide pour afficher les processus de tous les utilisateurs.
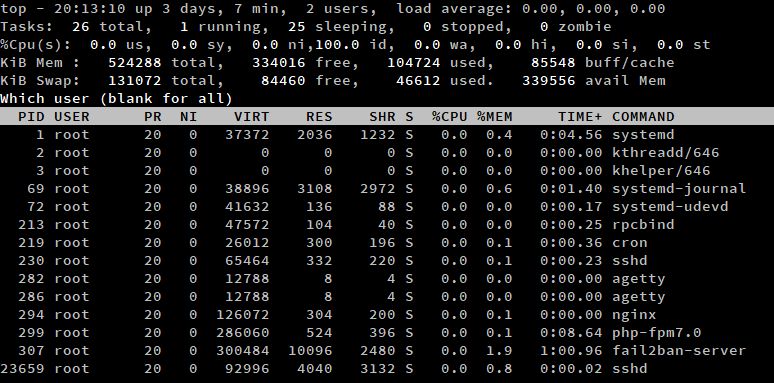
Alternativement, vous pouvez exécuter la commande top avec le commutateur -u. Dans cet exemple, nous avons listé tous les processus de l’utilisateur root.
top -u root
Filtrer à travers les processus
Si vous avez beaucoup de processus à travailler, un simple tri ne fonctionnera pas assez bien. Dans une telle situation, vous pouvez utiliser le filtrage de top pour vous concentrer sur quelques processus. Pour activer ce mode, appuyez sur ‘o’/’O’. Une invite apparaît à l’intérieur de top, et vous pouvez y saisir une expression de filtrage.
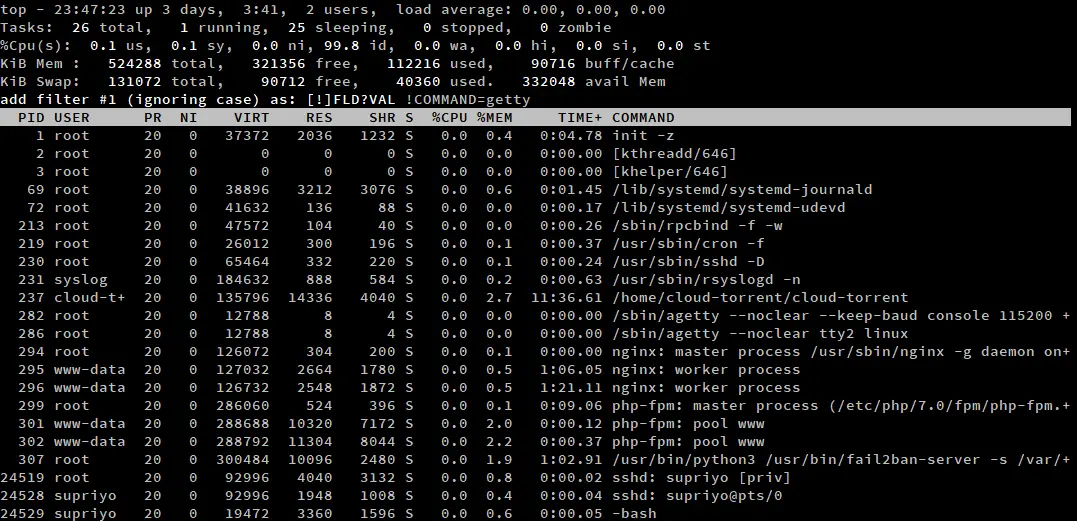
Une expression de filtrage est une déclaration qui spécifie une relation entre un attribut et une valeur. Voici quelques exemples de filtres :
-
COMMAND=getty: Filtrer les processus qui contiennent « getty » dans l’attribut COMMAND. -
!COMMAND=getty: Filtrer les processus qui n’ont pas « getty » dans l’attribut COMMAND. -
%CPU>3.0: Filtrer les processus qui ont une utilisation du CPU de plus de 3%.
Une fois que vous avez ajouté un filtre, vous pouvez encore élaguer les choses en ajoutant d’autres filtres. Pour effacer tous les filtres que vous avez ajoutés, appuyez sur ‘=’.
Changer l’aspect par défaut des statistiques du CPU et de la mémoire
Si vous êtes surtout à l’aise dans un environnement GUI, vous pourriez ne pas aimer la façon dont top affiche par défaut les statistiques du CPU et de la mémoire. Vous pouvez appuyer sur ‘t’ et ‘m’ pour changer le style des statistiques du CPU et de la mémoire. Voici une capture d’écran de top, où nous avons appuyé sur ‘t’ et ‘m’ une fois.
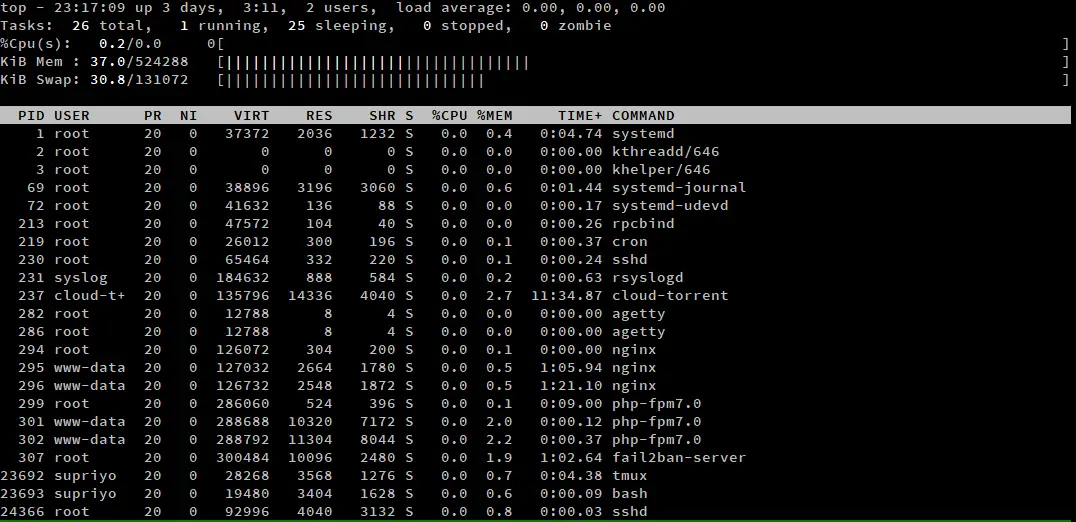
Si vous appuyez sur ‘t’ ou ‘m’ à plusieurs reprises, cela fait défiler quatre vues différentes. Lors des deux premières pressions, il fait défiler deux types différents de barres de progression. Si vous appuyez une troisième fois sur la touche, la barre de progression est masquée. Si vous appuyez à nouveau sur la touche, elle ramène les compteurs par défaut, basés sur le texte.
Sauvegarder vos paramètres
Si vous avez apporté des modifications à la sortie de top, vous pouvez les sauvegarder pour une utilisation ultérieure en appuyant sur ‘W’. top écrit sa configuration dans le fichier .toprc de votre répertoire personnel.
Conclusion
La commande top est extrêmement utile pour surveiller et gérer les processus sur un système Linux. Cet article ne fait qu’effleurer la surface, et il y a pas mal de choses que nous n’avons pas couvertes. Par exemple, il y a beaucoup plus de colonnes que vous pouvez ajouter à top. Pour toutes ces choses, assurez-vous de consulter la page de manuel en exécutant man top sur votre système.
Si vous avez aimé cet article, partagez-le 🙂
.