Ingénierie inverse
MachinesEdit
Avec la popularité croissante de la conception assistée par ordinateur (CAO), l’ingénierie inverse est devenue une méthode viable pour créer un modèle virtuel 3D d’une pièce physique existante à utiliser dans un logiciel de CAO 3D, de FAO, d’IAO ou autre. Le processus de rétro-ingénierie consiste à mesurer un objet, puis à le reconstruire sous forme de modèle 3D. L’objet physique peut être mesuré à l’aide de technologies de numérisation 3D telles que les MMT, les scanners laser, les numériseurs à lumière structurée ou la tomographie industrielle (tomodensitométrie). Les données mesurées seules, généralement représentées sous la forme d’un nuage de points, manquent d’informations topologiques et d’intentions de conception. Les premières peuvent être récupérées en convertissant le nuage de points en un maillage à faces triangulaires. La rétro-ingénierie vise à aller au-delà de la production d’un tel maillage et à récupérer l’intention de conception en termes de surfaces analytiques simples le cas échéant (plans, cylindres, etc.) et éventuellement de surfaces NURBS pour produire un modèle CAO de représentation des limites. La récupération d’un tel modèle permet de modifier une conception pour répondre à de nouvelles exigences, de générer un plan de fabrication, etc.
La modélisation hybride est un terme couramment utilisé lorsque la modélisation NURBS et la modélisation paramétrique sont mises en œuvre ensemble. L’utilisation d’une combinaison de surfaces géométriques et de formes libres peut fournir une méthode puissante de modélisation 3D. Des zones de données de forme libre peuvent être combinées avec des surfaces géométriques exactes pour créer un modèle hybride. Un exemple typique serait la rétroconception d’une culasse, qui comprend des caractéristiques moulées de forme libre, telles que des chemises d’eau et des zones usinées à haute tolérance.
La rétroconception est également utilisée par les entreprises pour amener la géométrie physique existante dans des environnements de développement de produits numériques, pour réaliser un enregistrement numérique en 3D de leurs propres produits ou pour évaluer les produits des concurrents. Elle est utilisée pour analyser le fonctionnement d’un produit, ce qu’il fait, quels sont ses composants ; estimer les coûts ; identifier les violations potentielles de brevets ; etc.
L’ingénierie de la valeur, une activité connexe également utilisée par les entreprises, consiste à déconstruire et à analyser les produits. Cependant, l’objectif est de trouver des possibilités de réduction des coûts.
SoftwareEdit
En 1990, l’Institute of Electrical and Electronics Engineers (IEEE) a défini l’ingénierie inverse (logicielle) comme « le processus d’analyse d’un système sujet pour identifier les composants du système et leurs interrelations et pour créer des représentations du système sous une autre forme ou à un niveau d’abstraction plus élevé » dans lequel le « système sujet » est le produit final du développement logiciel. La rétroingénierie est un processus d’examen uniquement, et le système logiciel considéré n’est pas modifié, ce qui serait autrement une réingénierie ou une restructuration. La rétroingénierie peut être effectuée à partir de n’importe quelle étape du cycle du produit, pas nécessairement à partir du produit final fonctionnel.
La rétroingénierie comporte deux composantes : la redocumentation et la récupération de la conception. La redocumentation est la création d’une nouvelle représentation du code informatique afin qu’il soit plus facile à comprendre. Parallèlement, la récupération de la conception est l’utilisation de la déduction ou du raisonnement à partir de connaissances générales ou d’une expérience personnelle du produit pour comprendre pleinement la fonctionnalité du produit. Elle peut également être considérée comme un « retour en arrière dans le cycle de développement ». Dans ce modèle, le résultat de la phase de mise en œuvre (sous forme de code source) fait l’objet d’une rétro-ingénierie pour revenir à la phase d’analyse, dans une inversion du modèle traditionnel en cascade. Un autre terme pour cette technique est la compréhension du programme. La Conférence de travail sur l’ingénierie inverse (WCRE) se tient chaque année pour explorer et développer les techniques d’ingénierie inverse. L’ingénierie logicielle assistée par ordinateur (CASE) et la génération de code automatisée ont largement contribué au domaine de la rétro-ingénierie.
La technologie anti-tamper des logiciels comme l’obfuscation est utilisée pour dissuader à la fois la rétro-ingénierie et la réingénierie des logiciels propriétaires et des systèmes alimentés par des logiciels. En pratique, deux principaux types de rétro-ingénierie émergent. Dans le premier cas, le code source du logiciel est déjà disponible, mais les aspects de plus haut niveau du programme, qui sont peut-être mal documentés ou documentés mais qui ne sont plus valables, sont découverts. Dans le second cas, il n’y a pas de code source disponible pour le logiciel, et tout effort visant à découvrir un code source possible pour le logiciel est considéré comme de l’ingénierie inverse. La deuxième utilisation du terme est plus familière à la plupart des gens. La rétro-ingénierie d’un logiciel peut faire appel à la technique de conception en salle blanche pour éviter toute violation du droit d’auteur.
Dans un registre connexe, le test de la boîte noire en génie logiciel a beaucoup de points communs avec la rétro-ingénierie. Le testeur dispose généralement de l’API mais a pour objectifs de trouver des bogues et des fonctionnalités non documentées en défonçant le produit de l’extérieur.
Les autres objectifs de l’ingénierie inverse incluent l’audit de sécurité, la suppression de la protection contre la copie (« cracking »), le contournement des restrictions d’accès souvent présentes dans l’électronique grand public, la personnalisation des systèmes embarqués (tels que les systèmes de gestion du moteur), les réparations ou les rétrofits en interne, l’activation de fonctionnalités supplémentaires sur du matériel « estropié » à faible coût (comme certains jeux de puces de cartes graphiques), ou même la simple satisfaction de la curiosité.
Édition de logiciels binaires
L’ingénierie inverse binaire est effectuée si le code source d’un logiciel n’est pas disponible. Ce processus est parfois appelé ingénierie de code inverse, ou RCE. Par exemple, la décompilation de binaires pour la plate-forme Java peut être accomplie en utilisant Jad. Un cas célèbre d’ingénierie inverse a été la première implémentation non-IBM du BIOS pour PC, qui a donné le coup d’envoi de l’industrie historique des ordinateurs compatibles IBM, qui a été la plate-forme matérielle informatique largement dominante pendant de nombreuses années. L’ingénierie inverse des logiciels est protégée aux États-Unis par l’exception d’usage loyal de la loi sur le droit d’auteur. Le logiciel Samba, qui permet à des systèmes qui n’utilisent pas Microsoft Windows de partager des fichiers avec des systèmes qui l’utilisent, est un exemple classique de rétro-ingénierie logicielle puisque le projet Samba a dû faire de la rétro-ingénierie d’informations non publiées sur le fonctionnement du partage de fichiers de Windows afin que les ordinateurs non Windows puissent l’émuler. Le projet Wine fait la même chose pour l’API Windows, et OpenOffice.org fait de même pour les formats de fichiers Microsoft Office. Le projet ReactOS est encore plus ambitieux dans ses objectifs en s’efforçant de fournir une compatibilité binaire (ABI et API) avec les systèmes d’exploitation Windows actuels de la branche NT, ce qui permet aux logiciels et aux pilotes écrits pour Windows de fonctionner sur une contrepartie en salle blanche de rétro-ingénierie de logiciels libres (GPL). WindowsSCOPE permet la rétro-ingénierie du contenu complet de la mémoire vive d’un système Windows, y compris une rétro-ingénierie graphique de niveau binaire de tous les processus en cours d’exécution.
Un autre exemple classique, bien que peu connu, est qu’en 1987, les Laboratoires Bell ont procédé à la rétro-ingénierie du système Mac OS 4.1, fonctionnant à l’origine sur le Macintosh SE d’Apple, afin de pouvoir l’exécuter sur leurs propres machines RISC.
Techniques de logiciels binairesEdit
La rétro-ingénierie des logiciels peut être accomplie par diverses méthodes.Les trois principaux groupes de rétro-ingénierie logicielle sont
- L’analyse par l’observation de l’échange d’informations, la plus répandue dans la rétro-ingénierie des protocoles, qui implique l’utilisation d’analyseurs de bus et de renifleurs de paquets, par exemple pour accéder à un bus informatique ou à une connexion de réseau informatique et révéler les données de trafic qui s’y trouvent. Le comportement du bus ou du réseau peut alors être analysé pour produire une mise en œuvre autonome qui imite ce comportement. Cela est particulièrement utile pour la rétro-ingénierie des pilotes de périphériques. Parfois, la rétro-ingénierie sur les systèmes embarqués est grandement facilitée par des outils délibérément introduits par le fabricant, tels que les ports JTAG ou d’autres moyens de débogage. Dans Microsoft Windows, les débogueurs de bas niveau tels que SoftICE sont populaires.
- Désassemblage à l’aide d’un désassembleur, ce qui signifie que le langage machine brut du programme est lu et compris dans ses propres termes, uniquement à l’aide de mnémoniques du langage machine. Cela fonctionne sur n’importe quel programme informatique mais peut prendre un certain temps, surtout pour ceux qui ne sont pas habitués au code machine. Le désassembleur interactif est un outil particulièrement populaire.
- Décompilation à l’aide d’un décompilateur, un processus qui tente, avec des résultats variables, de recréer le code source dans un certain langage de haut niveau pour un programme uniquement disponible en code machine ou en bytecode.
Classification de logicielsEdit
La classification de logiciels est le processus d’identification des similitudes entre différents binaires de logiciels (comme deux versions différentes du même binaire) utilisé pour détecter les relations de code entre les échantillons de logiciels. Cette tâche était traditionnellement effectuée manuellement pour plusieurs raisons (comme l’analyse des correctifs pour la détection des vulnérabilités et la violation des droits d’auteur), mais elle peut maintenant être effectuée de manière quelque peu automatique pour un grand nombre d’échantillons.
Cette méthode est surtout utilisée pour les tâches de rétroingénierie longues et approfondies (analyse complète d’un algorithme complexe ou d’un gros morceau de logiciel). En général, la classification statistique est considérée comme un problème difficile, ce qui est également vrai pour la classification des logiciels, et donc peu de solutions/outils qui gèrent bien cette tâche.
Source codeEdit
Un certain nombre d’outils UML font référence au processus d’importation et d’analyse du code source pour générer des diagrammes UML en tant que « reverse engineering ». Voir Liste des outils UML.
Bien qu’UML soit une approche permettant de fournir une « ingénierie inverse », des avancées plus récentes dans les activités de normalisation internationale ont abouti au développement du Knowledge Discovery Metamodel (KDM). Cette norme fournit une ontologie pour la représentation intermédiaire (ou abstraite) des constructions du langage de programmation et de leurs interrelations. Norme de l’Object Management Group (en passe de devenir une norme ISO), KDM a commencé à s’imposer dans l’industrie avec le développement d’outils et d’environnements d’analyse permettant l’extraction et l’analyse du code source, binaire et octet. Pour l’analyse du code source, l’architecture granulaire de la norme KDM permet l’extraction des flux de systèmes logiciels (données, contrôle et cartes d’appel), des architectures et des connaissances de la couche métier (règles, termes et processus). La norme permet l’utilisation d’un format de données commun (XMI) permettant la corrélation des différentes couches de connaissance du système pour une analyse détaillée (telle que la cause première, l’impact) ou une analyse dérivée (telle que l’extraction de processus métier). Bien que les efforts pour représenter les constructions de langage puissent être sans fin en raison du nombre de langages, de l’évolution continue des langages logiciels et du développement de nouveaux langages, la norme permet l’utilisation d’extensions pour prendre en charge le vaste ensemble de langages ainsi que l’évolution. KDM est compatible avec UML, BPMN, RDF, et d’autres normes permettant la migration dans d’autres environnements et ainsi de tirer parti de la connaissance du système pour des efforts tels que la transformation des systèmes logiciels et l’analyse de la couche métier de l’entreprise.
ProtocolesEdit
Les protocoles sont des ensembles de règles qui décrivent les formats de messages et la façon dont les messages sont échangés : la machine d’état du protocole. En conséquence, le problème de la rétro-ingénierie des protocoles peut être partitionné en deux sous-problèmes : le format des messages et la rétro-ingénierie de la machine à états.
Les formats des messages ont traditionnellement été rétro-ingéniés par un processus manuel fastidieux, qui impliquait l’analyse de la façon dont les implémentations des protocoles traitent les messages, mais des recherches récentes ont proposé un certain nombre de solutions automatiques. Typiquement, les approches automatiques regroupent les messages d’observation en clusters en utilisant diverses analyses de clustering, ou bien elles émulent l’implémentation du protocole en traçant le traitement des messages.
Il y a eu moins de travaux sur la rétro-ingénierie des state-machines des protocoles. En général, les state-machines des protocoles peuvent être appris soit par un processus d’apprentissage hors ligne, qui observe passivement la communication et tente de construire le state-machine le plus général acceptant toutes les séquences de messages observées, et l’apprentissage en ligne, qui permet la génération interactive de séquences de messages de sondage et l’écoute des réponses à ces séquences de sondage. En général, l’apprentissage hors ligne de petites machines d’état est connu pour être NP-complet, mais l’apprentissage en ligne peut être fait en temps polynomial. Une approche automatique hors ligne a été démontrée par Comparetti et al. et une approche en ligne par Cho et al.
D’autres composants de protocoles typiques, comme les fonctions de cryptage et de hachage, peuvent également faire l’objet d’une rétro-ingénierie automatique. Généralement, les approches automatiques tracent l’exécution des implémentations de protocoles et tentent de détecter les tampons en mémoire contenant des paquets non chiffrés.
Circuits intégrés/cartes à puceModification
L’ingénierie inverse est une forme invasive et destructive d’analyse d’une carte à puce. L’attaquant utilise des produits chimiques pour décaper couche après couche la carte à puce et prend des photos avec un microscope électronique à balayage (MEB). Cette technique peut révéler toute la partie matérielle et logicielle de la carte à puce. Le problème majeur pour l’attaquant est de tout remettre dans le bon ordre pour savoir comment tout fonctionne. Les fabricants de la carte essaient de cacher les clés et les opérations en mélangeant les positions de la mémoire, par exemple en brouillant le bus.
Dans certains cas, il est même possible de fixer une sonde pour mesurer les tensions alors que la carte à puce est encore opérationnelle. Les fabricants de la carte emploient des capteurs pour détecter et empêcher cette attaque. Cette attaque n’est pas très courante car elle nécessite à la fois un gros investissement en efforts et un équipement spécial qui n’est généralement disponible que pour les grands fabricants de puces. En outre, le gain de cette attaque est faible puisque d’autres techniques de sécurité sont souvent utilisées, comme les comptes fantômes. Il n’est pas encore certain que les attaques contre les cartes à puce visant à répliquer les données de cryptage, puis à craquer les codes PIN, constitueraient une attaque rentable contre l’authentification multifactorielle.
La rétro-ingénierie complète se déroule en plusieurs étapes majeures.
La première étape après la prise d’images avec un MEB consiste à assembler les images, ce qui est nécessaire car chaque couche ne peut pas être capturée par un seul cliché. Un MEB doit balayer la zone du circuit et prendre plusieurs centaines d’images pour couvrir l’ensemble de la couche. L’assemblage d’images prend en entrée plusieurs images et sort une seule image correctement superposée de la couche complète.
Puis, les couches assemblées doivent être alignées car l’échantillon, après gravure, ne peut pas être mis exactement dans la même position par rapport au MEB à chaque fois. Par conséquent, les versions cousues ne se chevaucheront pas de manière correcte, comme sur le circuit réel. Habituellement, trois points correspondants sont sélectionnés, et une transformation est appliquée sur cette base.
Pour extraire la structure du circuit, les images alignées et assemblées doivent être segmentées, ce qui met en évidence les circuits importants et les sépare du fond inintéressant et des matériaux isolants.
Enfin, les fils peuvent être tracés d’une couche à l’autre et la netlist du circuit, qui contient toutes les informations du circuit, peut être reconstituée.
Applications militairesModifier
L’ingénierie inverse est souvent utilisée par des personnes pour copier les technologies, les dispositifs ou les informations d’autres nations qui ont été obtenus par des troupes régulières sur le terrain ou par des opérations de renseignement. Elle a souvent été utilisée pendant la Seconde Guerre mondiale et la guerre froide. Voici des exemples bien connus de la Seconde Guerre mondiale et plus tard:
- Bidon Jerry : Les forces britanniques et américaines ont remarqué que les Allemands avaient des bidons d’essence avec un excellent design. Ils ont procédé à la rétro-ingénierie de copies de ces bidons, lesquels bidons étaient populairement connus sous le nom de « Jerry cans ».
- Panzerschreck : Les Allemands ont capturé un bazooka américain pendant la Seconde Guerre mondiale et l’ont rétroconçu pour créer le plus grand Panzerschreck.
- Tupolev Tu-4 : En 1944, trois bombardiers américains B-29 en mission au-dessus du Japon ont été forcés d’atterrir en Union soviétique. Les Soviétiques, qui ne disposaient pas d’un bombardier stratégique similaire, décidèrent de copier le B-29. En trois ans, ils avaient développé le Tu-4, une copie presque parfaite.
- Radar SCR-584 : copié par l’Union soviétique après la Seconde Guerre mondiale, il est connu pour quelques modifications – СЦР-584, Бинокль-Д.
- Fusée V-2 : Les documents techniques du V-2 et des technologies connexes ont été capturés par les Alliés occidentaux à la fin de la guerre. Les Américains ont concentré leurs efforts de rétro-ingénierie via l’opération Paperclip, qui a conduit au développement de la fusée PGM-11 Redstone. Les Soviétiques ont utilisé des ingénieurs allemands capturés pour reproduire des documents et des plans techniques et ont travaillé à partir de matériel capturé pour fabriquer leur clone de la fusée, la R-1. C’est ainsi qu’a débuté le programme de fusées soviétiques d’après-guerre, qui a conduit à la R-7 et au début de la course à l’espace.
- Le missile K-13/R-3S (nom de rapport de l’OTAN AA-2 Atoll), une copie soviétique de rétro-ingénierie de l’AIM-9 Sidewinder, a été rendu possible après qu’un AIM-9B taïwanais ait touché un MiG-17 chinois sans exploser en septembre 1958. Le missile s’est logé dans la cellule, et le pilote est rentré à la base avec ce que les scientifiques soviétiques décriraient comme un cours universitaire sur le développement des missiles.
- Missile BGM-71 TOW : en mai 1975, les négociations entre l’Iran et Hughes Missile Systems sur la coproduction des missiles TOW et Maverick ont achoppé sur des désaccords dans la structure des prix, la révolution de 1979 qui s’en est suivie mettant fin à tous les plans pour une telle coproduction. L’Iran a réussi par la suite à faire de la rétro-ingénierie sur le missile et produit maintenant sa propre copie, le Toophan.
- La Chine a fait de la rétro-ingénierie sur de nombreux exemples de matériel occidental et russe, des avions de chasse aux missiles et aux voitures HMMWV, comme le MiG-15 (qui est devenu le J-7) et le Su-33 (qui est devenu le J-15). Des analyses plus récentes de la croissance militaire de la Chine ont souligné les limites inhérentes à l’ingénierie inverse pour les systèmes d’armes avancés.
- Pendant la Seconde Guerre mondiale, des cryptographes polonais et britanniques ont étudié les machines de cryptage de messages « »Enigma » » allemandes capturées pour en déceler les faiblesses. Leur fonctionnement a ensuite été simulé sur des dispositifs électromécaniques, les » bombes « , qui ont essayé tous les réglages possibles des brouilleurs des machines « »Enigma » » qui ont aidé à casser les messages codés qui avaient été envoyés par les Allemands.
- Au cours de la Seconde Guerre mondiale également, les scientifiques britanniques ont analysé et vaincu une série de systèmes de radionavigation de plus en plus sophistiqués utilisés par la Luftwaffe pour effectuer des missions de bombardement guidées de nuit. Les contre-mesures britanniques à ce système étaient si efficaces que dans certains cas, les avions allemands ont été amenés par des signaux à atterrir sur les bases de la RAF car ils croyaient être revenus en territoire allemand.
Réseaux génétiquesModification
Les concepts d’ingénierie inverse ont été appliqués à la biologie également, plus précisément à la tâche de comprendre la structure et la fonction des réseaux de régulation des gènes. Ceux-ci régulent presque tous les aspects du comportement biologique et permettent aux cellules de réaliser des processus physiologiques et des réponses aux perturbations. Comprendre la structure et le comportement dynamique des réseaux de gènes est donc l’un des défis majeurs de la biologie systémique, avec des répercussions pratiques immédiates dans plusieurs applications qui vont au-delà de la recherche fondamentale.Il existe plusieurs méthodes de rétroconception des réseaux de régulation des gènes en utilisant des méthodes de biologie moléculaire et de science des données. Elles ont été généralement divisées en six classes :
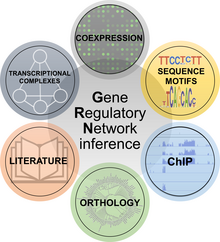
- Les méthodes de coexpression sont basées sur la notion que si deux gènes présentent un profil d’expression similaire, ils peuvent être liés bien qu’aucune causalité ne puisse être simplement déduite de la coexpression.
- Les méthodes de motifs de séquences analysent les promoteurs de gènes pour trouver des domaines de liaison de facteurs de transcription spécifiques. Si l’on prédit qu’un facteur de transcription se lie au promoteur d’un gène spécifique, on peut émettre l’hypothèse d’une connexion régulatrice.
- Les méthodes d’immuno-précipitation de la chromatine (ChIP) étudient le profil à l’échelle du génome de la liaison à l’ADN de facteurs de transcription choisis pour déduire leurs réseaux de gènes en aval.
- Les méthodes d’orthologie transfèrent les connaissances sur les réseaux de gènes d’une espèce à l’autre.
- Les méthodes de littérature mettent en œuvre l’exploration de texte et la recherche manuelle pour identifier les connexions de réseaux de gènes putatifs ou prouvés expérimentalement.
- Les méthodes de complexes transcriptionnels exploitent les informations sur les interactions protéine-protéine entre les facteurs de transcription, étendant ainsi le concept de réseaux de gènes pour inclure les complexes de régulation transcriptionnelle.
Souvent, la fiabilité des réseaux génétiques est testée par des expériences de perturbation génétique suivies d’une modélisation dynamique, basée sur le principe que la suppression d’un nœud du réseau a des effets prévisibles sur le fonctionnement des autres nœuds du réseau.Les applications de l’ingénierie inverse des réseaux génétiques vont de la compréhension des mécanismes de la physiologie végétale à la mise en évidence de nouvelles cibles pour les thérapies anticancéreuses.
Chevauchement avec le droit des brevetsEdit
L’ingénierie inverse s’applique principalement à la compréhension d’un processus ou d’un artefact dont le mode de construction, l’utilisation ou les processus internes n’ont pas été explicités par son créateur.
Les articles brevetés n’ont pas en soi besoin d’être soumis à l’ingénierie inverse pour être étudiés, car l’essence d’un brevet est que les inventeurs fournissent eux-mêmes une divulgation publique détaillée et reçoivent en retour une protection juridique de l’invention concernée. Cependant, un article produit en vertu d’un ou de plusieurs brevets pourrait également inclure d’autres technologies non brevetées et non divulguées. En effet, une motivation courante de l’ingénierie inverse est de déterminer si le produit d’un concurrent contient une violation de brevet ou une violation de droit d’auteur.