Apache Spark: Resilient Distributed Datasets
RDD’s vertegenwoordigen zowel het idee van hoe een grote dataset wordt gerepresenteerd in Apache Spark als de abstractie om ermee te werken. Dit deel gaat over het eerste, en de volgende delen gaan over het laatste. Volgens de seminale paper over Spark, “zijn RDDs onveranderlijke, fout-tolerante, parallelle data structuren die gebruikers expliciet tussentijdse resultaten in het geheugen laten bewaren, hun partitionering controleren om data plaatsing te optimaliseren, en ze manipuleren met behulp van een rijke set van operatoren.” Laten we deze beschrijving eens ontleden om de ideeën achter het RDD concept goed te begrijpen.
Immutable
RDDs zijn ontworpen om immutable te zijn, wat betekent dat je niet specifiek een bepaalde rij in de dataset die door die RDD wordt gerepresenteerd kunt wijzigen. Je kunt een van de beschikbare RDD operaties aanroepen om de rijen in de RDD te manipuleren op de manier die jij wilt, maar die operatie zal een nieuwe RDD teruggeven. De basis RDD blijft ongewijzigd, en de nieuwe RDD zal de data bevatten op de manier zoals jij die hebt gewijzigd. De onveranderlijkheid vereist dat een RDD zijn lineage-informatie bevat, die Spark gebruikt om efficiënt fouttolerantie te bieden.
Fouttolerant
Om meerdere datasets parallel te kunnen verwerken, is meestal een cluster van machines nodig om de rekenlogica te hosten en uit te voeren. Als een of meer van die machines uitvalt of extreem traag wordt door onverwachte omstandigheden, hoe zal dat dan de totale dataverwerking van die datasets beïnvloeden? Het goede nieuws is dat Spark automatisch zorgt voor de afhandeling van de storing namens de gebruikers door het falende deel opnieuw op te bouwen met behulp van de lineage informatie.
Parallelle Data Structuren
Stel je een use case voor waarbij iemand je een groot logbestand geeft dat 1TB groot is en je wordt gevraagd om uit te zoeken hoeveel log statements het woord “exception” bevatten. Een langzame oplossing zou zijn om dat logbestand van begin tot eind te doorlopen en de logica uit te voeren om te bepalen of een bepaalde logstatement het woord “uitzondering” bevat. Een snellere oplossing zou zijn dat bestand van 1 TB in verschillende brokken te verdelen en de bovengenoemde logica op elke brok op een parallelle manier uit te voeren om de totale verwerkingstijd te versnellen. Elke chunk bevat een verzameling rijen. De rijenrijenverzameling is in wezen de gegevensstructuur die een reeks rijen bevat en de mogelijkheid biedt om door elke rij te lopen. Elke chunk bevat een verzameling rijen, en alle chunks worden parallel verwerkt. Dit is waar de term parallelle datastructuren vandaan komt.
In-Memory Computing
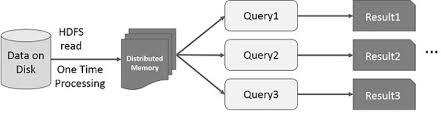
Het idee om de berekening van grote datasets die zich op schijven bevinden te versnellen op een geparallelliseerde manier met behulp van een cluster van machines werd geïntroduceerd door een MapReduce paper2 van Google. Dit idee werd geïmplementeerd en is beschikbaar gesteld in het Hadoop open source-project. Voortbouwend op die solide basis, verlegt RDD de snelheidsgrens door de mogelijkheid te introduceren om gedistribueerde in-memory berekeningen uit te voeren.
Het is altijd fascinerend om te kijken naar de verhalen die tot een innovatief idee hebben geleid. In de wereld van big data processing is het zo dat als je eenmaal in staat bent om op een betrouwbare manier inzichten uit grote datasets te halen met behulp van een aantal rudimentaire technieken, je meer geavanceerde technieken wilt gebruiken om de tijd die dat kost te verkorten. Dit is waar gedistribueerde in-memory computation helpt.
De verfijnde techniek die ik bedoel is het gebruik van machine learning om diverse voorspellingen te doen of om patronen uit grote datasets te halen. Machine learning-algoritmen zijn iteratief van aard, wat betekent dat ze vele iteraties moeten doorlopen om tot een optimale toestand te komen. Dit is waar gedistribueerde in-memory computation kan helpen om de doorlooptijd terug te brengen van dagen tot uren. Een andere toepassing die enorm kan profiteren van gedistribueerde in-memory computation is interactieve datamining, waarbij meerdere ad-hoc query’s worden uitgevoerd op dezelfde subset van gegevens. Als die subset van gegevens in het geheugen wordt bewaard, duurt het voltooien van die query’s seconden in plaats van minuten.