Algorytm Random Forest z Pythonem i Scikit-Learn
Random forest jest rodzajem algorytmu uczenia maszynowego opartego na uczeniu zespołowym. Uczenie zespołowe jest typem uczenia, w którym łączy się różne typy algorytmów lub ten sam algorytm wiele razy, aby utworzyć bardziej wydajny model predykcyjny. Algorytm random forest łączy wiele algorytmów tego samego typu, np. wiele drzew decyzyjnych, w wyniku czego powstaje las drzew, stąd nazwa „Random Forest”. Algorytm lasu losowego może być używany zarówno do zadań regresji, jak i klasyfikacji.
Jak działa algorytm lasu losowego
Następujące kroki to podstawowe kroki związane z wykonywaniem algorytmu lasu losowego:
- Wybierz N losowych rekordów z zestawu danych.
- Zbuduj drzewo decyzyjne w oparciu o te N rekordów.
- Wybierz liczbę drzew, które chcesz w swoim algorytmie i powtórz kroki 1 i 2.
- W przypadku problemu regresji, dla nowego rekordu, każde drzewo w lesie przewiduje wartość dla Y (wyjście). Wartość końcowa może być obliczona poprzez przyjęcie średniej wszystkich wartości przewidywanych przez wszystkie drzewa w lesie. Lub, w przypadku problemu klasyfikacji, każde drzewo w lesie przewiduje kategorię, do której należy nowy rekord. Ostatecznie, nowy rekord jest przypisywany do kategorii, która wygrywa większością głosów.
Wady używania Random Forest
Jak z każdym algorytmem, istnieją zalety i wady jego używania. W następnych dwóch sekcjach przyjrzymy się zaletom i wadom używania losowego lasu do klasyfikacji i regresji.
- Algorytm losowego lasu nie jest stronniczy, ponieważ istnieje wiele drzew, a każde drzewo jest trenowane na podzbiorze danych. Zasadniczo algorytm lasu losowego opiera się na sile „tłumu”; dlatego ogólna stronniczość algorytmu jest zredukowana.
- Algorytm ten jest bardzo stabilny. Nawet jeśli nowy punkt danych zostanie wprowadzony do zbioru danych, nie ma to większego wpływu na ogólny algorytm, ponieważ nowe dane mogą wpłynąć na jedno drzewo, ale bardzo trudno jest wpłynąć na wszystkie drzewa.
- Algorytm random forest działa dobrze, gdy masz zarówno cechy kategoryczne, jak i liczbowe.
- Algorytm lasu losowego działa również dobrze, gdy dane mają brakujące wartości lub nie zostały dobrze przeskalowane (chociaż przeprowadziliśmy skalowanie cech w tym artykule tylko dla celów demonstracyjnych).
Wady korzystania z lasu losowego
- Poważną wadą lasów losowych jest ich złożoność. Wymagają one znacznie więcej zasobów obliczeniowych, ze względu na dużą liczbę drzew decyzyjnych połączonych razem.
- Dzięki swojej złożoności, wymagają znacznie więcej czasu na trening niż inne porównywalne algorytmy.
Przez resztę tego artykułu zobaczymy jak biblioteka Scikit-Learn Pythona może być użyta do implementacji algorytmu random forest do rozwiązywania problemów regresji, jak również klasyfikacji.
Część 1: Using Random Forest for Regression
W tej części przestudiujemy, jak można wykorzystać lasy losowe do rozwiązywania problemów regresji za pomocą Scikit-Learn. W następnej części rozwiążemy problem klasyfikacji za pomocą lasów losowych.
Zdefiniowanie problemu
Problem polega na przewidywaniu zużycia gazu (w milionach galonów) w 48 stanach USA na podstawie podatku od benzyny (w centach), dochodu na mieszkańca (w dolarach), utwardzonych autostrad (w milach) i odsetka ludności z prawem jazdy.
Rozwiązanie
Do rozwiązania tego problemu regresji wykorzystamy algorytm random forest za pomocą biblioteki Scikit-Learn Pythona. Aby rozwiązać ten problem, będziemy postępować zgodnie z tradycyjnym tokiem uczenia maszynowego. Wykonaj następujące kroki:
1. Importowanie bibliotek
Wykonaj poniższy kod, aby zaimportować niezbędne biblioteki:
import pandas as pdimport numpy as np2. Importowanie zbioru danych
Zbiór danych dla tego problemu jest dostępny pod adresem:
https://drive.google.com/file/d/1mVmGNx6cbfvRHC_DvF12ZL3wGLSHD9f_/view
Na potrzeby tego tutoriala, zbiór danych został pobrany do folderu „Datasets” na dysku „D”. Będziesz musiał zmienić ścieżkę dostępu do pliku zgodnie z własnymi ustawieniami.
Wykonaj następujące polecenie, aby zaimportować zbiór danych:
dataset = pd.read_csv('D:\Datasets\petrol_consumption.csv')Aby uzyskać widok wysokiego poziomu, jak wygląda zbiór danych, wykonaj następujące polecenie:
dataset.head()| Petrol_tax | Średni_dochód | Drogi utwardzone | Ludność_licencji_kierowcy(%) | Zużycie benzyny | |
|---|---|---|---|---|---|
| 0 | 9.0 | 3571 | 1976 | 0.525 | 541 |
| 1 | 9.0 | 4092 | 1250 | 0.572 | 524 |
| 2 | 9.0 | 3865 | 1586 | 0.580 | 561 |
| 3 | 7.5 | 4870 | 2351 | 0.529 | 414 |
| 4 | 8.0 | 4399 | 431 | 0.544 | 410 |
Widzimy, że wartości w naszym zbiorze danych nie są zbyt dobrze skalowane. Przeskalujemy je w dół przed treningiem algorytmu.
3. Przygotowanie danych do treningu
W tej części zostaną wykonane dwa zadania. Pierwszym zadaniem jest podzielenie danych na zbiory 'atrybutów' i 'etykiet'. Następnie dane wynikowe są dzielone na zbiory treningowe i testowe.
Następujący skrypt dzieli dane na atrybuty i etykiety:
X = dataset.iloc.valuesy = dataset.iloc.valuesNa koniec podzielmy dane na zbiory treningowe i testowe:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)4. Skalowanie cech
Wiemy, że nasz zbiór danych nie jest jeszcze skalowany wartościowo, na przykład pole Average_Income ma wartości z zakresu tysięcy, podczas gdy Petrol_tax ma wartości z zakresu dziesiątek. Dlatego korzystnie byłoby przeskalować nasze dane (choć, jak wspomnieliśmy wcześniej, ten krok nie jest aż tak istotny dla algorytmu lasów losowych). W tym celu wykorzystamy klasę Scikit-Learn StandardScaler. W tym celu wykonaj następujący kod:
# Feature Scalingfrom sklearn.preprocessing import StandardScalersc = StandardScaler()X_train = sc.fit_transform(X_train)X_test = sc.transform(X_test)5. Trening algorytmu
Teraz, gdy już przeskalowaliśmy nasz zbiór danych, nadszedł czas, aby wytrenować nasz algorytm random forest do rozwiązania tego problemu regresji. Wykonaj następujący kod:
from sklearn.ensemble import RandomForestRegressorregressor = RandomForestRegressor(n_estimators=20, random_state=0)regressor.fit(X_train, y_train)y_pred = regressor.predict(X_test)Klasa RandomForestRegressor z biblioteki sklearn.ensemble służy do rozwiązywania problemów regresji za pomocą random forest. Najważniejszym parametrem klasy RandomForestRegressor jest parametr n_estimators. Parametr ten definiuje liczbę drzew w lesie losowym. Zaczniemy od n_estimator=20 aby zobaczyć jak sprawuje się nasz algorytm. Szczegóły dotyczące wszystkich parametrów RandomForestRegressor można znaleźć tutaj.
6. Ocena algorytmu
Ostatnim i ostatnim krokiem rozwiązywania problemu uczenia maszynowego jest ocena wydajności algorytmu. W przypadku problemów z regresją, metryki używane do oceny algorytmu to średni błąd bezwzględny, średni błąd kwadratowy i pierwiastek średniego błędu kwadratowego. Wykonaj poniższy kod, aby znaleźć te wartości:
from sklearn import metricsprint('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))print('Root Mean Squared Error:', np.sqrt(metrics.mean_squared_error(y_test, y_pred)))Wyjście będzie wyglądało mniej więcej tak:
Mean Absolute Error: 51.765Mean Squared Error: 4216.16675Root Mean Squared Error: 64.932016371Przy 20 drzewach błąd średniokwadratowy wynosi 64,93, co jest większe niż 10 procent średniego zużycia benzyny, czyli 576,77. Może to świadczyć między innymi o tym, że nie użyliśmy wystarczającej liczby estymatorów (drzew).
Jeśli liczbę estymatorów zmienimy na 200, to wyniki będą następujące:
Mean Absolute Error: 47.9825Mean Squared Error: 3469.7007375Root Mean Squared Error: 58.9041657058Następujący wykres przedstawia spadek wartości błędu średniokwadratowego (RMSE) w zależności od liczby estymatorów. Tutaj oś X zawiera liczbę estymatorów, natomiast oś Y zawiera wartość błędu średniokwadratowego.
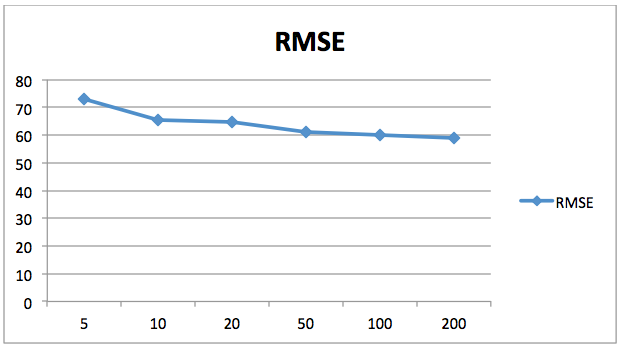
Można zauważyć, że wartości błędu maleją wraz ze wzrostem liczby estymatorów. Po 200 tempo spadku błędu maleje, więc dlatego 200 jest dobrą liczbą dla n_estimators. Możesz pobawić się z liczbą drzew i innymi parametrami, aby sprawdzić, czy możesz uzyskać lepsze wyniki na własną rękę.
Część 2: Użycie Random Forest do klasyfikacji
Problem Definicja
Zadaniem tutaj jest przewidzenie, czy banknot jest autentyczny, czy nie, w oparciu o cztery atrybuty i.tj. wariancji obrazu przekształconego falowo, skośności, entropii i kurtozie obrazu.
Rozwiązanie
Jest to problem klasyfikacji binarnej i użyjemy klasyfikatora lasu losowego do rozwiązania tego problemu. Kroki wykonywane w celu rozwiązania tego problemu będą podobne do kroków wykonywanych dla regresji.
1. Importowanie bibliotek
import pandas as pdimport numpy as np2. Import Datasetu
Zbiór danych można pobrać z poniższego linku:
https://drive.google.com/file/d/13nw-uRXPY8XIZQxKRNZ3yYlho-CYm_Qt/view
Szczegółowe informacje o danych dostępne są pod poniższym linkiem:
https://archive.ics.uci.edu/ml/datasets/banknote+authentication
Następujący kod importuje zbiór danych:
dataset = pd.read_csv("D:/Datasets/bill_authentication.csv")Aby uzyskać wysokopoziomowy widok zbioru danych, wykonaj następujące polecenie:
dataset.head()| Wariancja | Kośność | Kurtoza | Entropia | Klasa | |
|---|---|---|---|---|---|
| 0 | 3.62160 | 8.6661 | -2.8073 | -0.44699 | 0 |
| 1 | 4.54590 | 8.1674 | -2.4586 | -1.46210 | 0 |
| 2 | 3.86600 | -2.6383 | 1.9242 | 0.10645 | 0 |
| 3 | 3.45660 | 9.5228 | -4.0112 | -3.59440 | 0 |
| 4 | 0.32924 | -4.4552 | 4.5718 | -0.98880 | 0 |
Tak jak w przypadku zbioru danych regresji, wartości w tym zbiorze danych nie są zbyt dobrze skalowane. Zbiór danych zostanie przeskalowany przed treningiem algorytmu.
3. Przygotowanie danych do treningu
Następujący kod dzieli dane na atrybuty i etykiety:
X = dataset.iloc.valuesy = dataset.iloc.valuesNastępujący kod dzieli dane na zbiory treningowe i testowe:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)4. Skalowanie cech
Tak jak poprzednio, skalowanie cech działa w ten sam sposób:
# Feature Scalingfrom sklearn.preprocessing import StandardScalersc = StandardScaler()X_train = sc.fit_transform(X_train)X_test = sc.transform(X_test)5. Trening algorytmu
I znowu, teraz, gdy mamy skalowany zbiór danych, możemy trenować nasze lasy losowe, aby rozwiązać ten problem klasyfikacji. W tym celu wykonaj następujący kod:
from sklearn.ensemble import RandomForestRegressorregressor = RandomForestRegressor(n_estimators=20, random_state=0)regressor.fit(X_train, y_train)y_pred = regressor.predict(X_test)W przypadku regresji użyliśmy klasy RandomForestRegressor z biblioteki sklearn.ensemble. Do klasyfikacji wykorzystamy RandomForestClassifier klasę z biblioteki sklearn.ensemble. Klasa RandomForestClassifier również przyjmuje jako parametr n_estimators. Podobnie jak poprzednio, parametr ten określa liczbę drzew w naszym lesie losowym. Ponownie zaczniemy od 20 drzew. Szczegóły dotyczące wszystkich parametrów RandomForestClassifier znajdziesz tutaj.
6. Ocena algorytmu
W przypadku problemów z klasyfikacją, metryki używane do oceny algorytmu to dokładność, macierz konfuzji, precyzja, przywołanie i wartości F1. Wykonaj poniższy skrypt, aby znaleźć te wartości:
from sklearn.metrics import classification_report, confusion_matrix, accuracy_scoreprint(confusion_matrix(y_test,y_pred))print(classification_report(y_test,y_pred))print(accuracy_score(y_test, y_pred))Wyjście będzie wyglądać następująco:
1 117]] precision recall f1-score support 0 0.99 0.99 0.99 157 1 0.98 0.99 0.99 118 avg / total 0.99 0.99 0.99 2750.989090909091Dokładność uzyskana przez nasz klasyfikator random forest z 20 drzewami wynosi 98,90%. Inaczej niż poprzednio, zmiana liczby estymatorów dla tego problemu nie poprawiła znacząco wyników, co widać na poniższym wykresie. Tutaj oś X zawiera liczbę estymatorów, podczas gdy oś Y pokazuje dokładność.
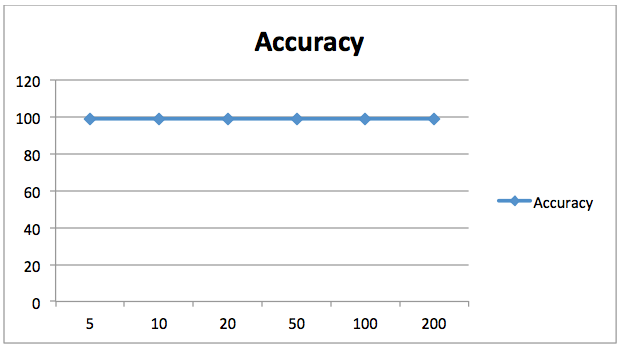
98,90% to całkiem dobra dokładność, więc nie ma większego sensu zwiększać liczby estymatorów. Widzimy, że zwiększenie liczby estymatorów nie poprawiło dokładności.
Aby poprawić dokładność, sugerowałbym pobawić się innymi parametrami klasy RandomForestClassifier i zobaczyć, czy można poprawić nasze wyniki.
Źródła
Chcesz dowiedzieć się więcej o Scikit-Learn i innych użytecznych algorytmach uczenia maszynowego, takich jak lasy losowe? Możesz sprawdzić niektóre bardziej szczegółowe zasoby, takie jak kurs online:
- Data Science in Python, Pandas, Scikit-learn, Numpy, Matplotlib
- Python for Data Science and Machine Learning Bootcamp
- Machine Learning A-Z: Hands-On Python & R W Data Science