Algoritmo Florestal Aleatório com Python e Scikit-Learn
Florestas Aleatórias é um tipo de algoritmo de aprendizagem de máquinas supervisionado baseado na aprendizagem em conjunto. A aprendizagem em conjunto é um tipo de aprendizagem onde se juntam diferentes tipos de algoritmos ou o mesmo algoritmo várias vezes para formar um modelo de previsão mais poderoso. O algoritmo florestal aleatório combina múltiplos algoritmos do mesmo tipo, ou seja, múltiplas árvores de decisão, resultando numa floresta de árvores, daí o nome “Floresta Aleatória”. O algoritmo florestal aleatório pode ser usado tanto para tarefas de regressão como de classificação.
Como funciona o Algoritmo Florestal Aleatório
Os seguintes são os passos básicos envolvidos na execução do algoritmo florestal aleatório:
- Pick N registos aleatórios do conjunto de dados.
- Build uma árvore de decisão baseada nestes N registos.
- Escolha o número de árvores que deseja no seu algoritmo e repita os passos 1 e 2.
- No caso de um problema de regressão, para um novo registo, cada árvore na floresta prevê um valor para Y (saída). O valor final pode ser calculado tomando a média de todos os valores previstos por todas as árvores na floresta. Ou, no caso de um problema de classificação, cada árvore da floresta prevê a categoria a que pertence o novo registo. Finalmente, o novo registo é atribuído à categoria que ganha o voto maioritário.
Vantagens da utilização de Floresta Aleatória
As vantagens e desvantagens da sua utilização são possíveis com qualquer algoritmo. Nas duas secções seguintes vamos analisar os prós e contras da utilização de floresta aleatória para classificação e regressão.
- O algoritmo da floresta aleatória não é enviesado, uma vez que, existem múltiplas árvores e cada árvore é treinada num subconjunto de dados. Basicamente, o algoritmo florestal aleatório baseia-se no poder da “multidão”; portanto, o enviesamento geral do algoritmo é reduzido.
- Este algoritmo é muito estável. Mesmo que um novo ponto de dados seja introduzido no conjunto de dados, o algoritmo geral não é muito afectado, uma vez que novos dados podem ter impacto numa árvore, mas é muito difícil que tenha impacto em todas as árvores.
- O algoritmo florestal aleatório funciona bem quando se tem características tanto categóricas como numéricas.
- O algoritmo florestal aleatório também funciona bem quando os dados têm valores em falta ou não foram bem escalados (embora tenhamos realizado escalas de características neste artigo apenas para fins de demonstração).
Desvantagens de usar Random Forest
- Uma grande desvantagem das florestas aleatórias reside na sua complexidade. Requerem muito mais recursos computacionais, devido ao grande número de árvores de decisão unidas.
- li>Devem à sua complexidade, requerem muito mais tempo para treinar do que outros algoritmos comparáveis.
P>Até ao resto deste artigo veremos como a biblioteca Python’s Scikit-Learn pode ser utilizada para implementar o algoritmo florestal aleatório para resolver problemas de regressão, bem como de classificação.
Parte 1: Usando Random Forest for Regression
Nesta secção vamos estudar como as florestas aleatórias podem ser usadas para resolver problemas de regressão usando Scikit-Learn. Na próxima secção vamos resolver o problema da classificação através de florestas aleatórias.
Problem Definition
O problema aqui é prever o consumo de gás (em milhões de galões) em 48 dos estados dos EUA com base no imposto sobre a gasolina (em cêntimos), rendimento per capita (dólares), estradas pavimentadas (em milhas) e a proporção da população com a carta de condução.
Solução
Para resolver este problema de regressão, utilizaremos o algoritmo florestal aleatório através da biblioteca Scikit-Learn Python. Seguiremos a tradicional linha de aprendizagem de máquinas para resolver este problema. Seguir estes passos:
1. Import Libraries
Executar o seguinte código para importar as bibliotecas necessárias:
import pandas as pdimport numpy as np2. Importar conjunto de dados
O conjunto de dados para este problema está disponível em:
https://drive.google.com/file/d/1mVmGNx6cbfvRHC_DvF12ZL3wGLSHD9f_/view
Para o bem deste tutorial, o conjunto de dados foi descarregado para a pasta “Datasets” da Unidade “D”. Terá de alterar o caminho do ficheiro de acordo com a sua própria configuração.
Executar o seguinte comando para importar o conjunto de dados:
dataset = pd.read_csv('D:\Datasets\petrol_consumption.csv')Para obter uma visão de alto nível de como é o conjunto de dados, executar o seguinte comando:
dataset.head()| Petrol_tax | Average_income | Paved_Highways | Population_Driver_license(%) | ||
|---|---|---|---|---|---|
| 0 | 9.0 | 1976 | |||
| 1 | 9.0 | 4092 | 1250 | 0.572 | 524 |
| 2 | 9.0 | 3865 | 1586 | 0.580 | 561 |
| 3 | 7.5 | ||||
| 8.0 | 0.544 | 410 |
Podemos ver que os valores no nosso conjunto de dados não estão muito bem escalados. Vamos reduzi-los antes de treinar o algoritmo.
3. Preparação de dados para treino
Duas tarefas serão realizadas nesta secção. A primeira tarefa consiste em dividir os dados em conjuntos de ‘atributos’ e ‘etiquetas’. Os dados resultantes são então divididos em conjuntos de treino e teste.
O seguinte script divide os dados em atributos e etiquetas:
X = dataset.iloc.valuesy = dataset.iloc.valuesFinalmente, vamos dividir os dados em conjuntos de treino e teste:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)4. Escala de Característica
Sabemos que o nosso conjunto de dados ainda não é um valor escalonado, por exemplo, o campo Average_Income tem valores no intervalo de milhares enquanto que o Petrol_tax tem valores no intervalo de dezenas. Por conseguinte, seria benéfico escalar os nossos dados (embora, como mencionado anteriormente, este passo não seja tão importante para o algoritmo das florestas aleatórias). Para tal, utilizaremos o Scikit-Learn’s StandardScaler class. Executar o seguinte código para o fazer:
# Feature Scalingfrom sklearn.preprocessing import StandardScalersc = StandardScaler()X_train = sc.fit_transform(X_train)X_test = sc.transform(X_test)5. Treinar o Algoritmo
Agora que escalámos o nosso conjunto de dados, é altura de treinar o nosso algoritmo florestal aleatório para resolver este problema de regressão. Executar o seguinte código:
from sklearn.ensemble import RandomForestRegressorregressor = RandomForestRegressor(n_estimators=20, random_state=0)regressor.fit(X_train, y_train)y_pred = regressor.predict(X_test) O RandomForestRegressor classe do sklearn.ensemble biblioteca é utilizada para resolver problemas de regressão através de floresta aleatória. O parâmetro mais importante do parâmetro RandomForestRegressor classe é o parâmetro n_estimators. Este parâmetro define o número de árvores na floresta aleatória. Vamos começar com n_estimator=20 para ver como o nosso algoritmo funciona. Pode encontrar detalhes para todos os parâmetros de RandomForestRegressor aqui.
6. Avaliar o Algoritmo
O último e último passo para resolver um problema de aprendizagem da máquina é avaliar o desempenho do algoritmo. Para problemas de regressão, as métricas utilizadas para avaliar um algoritmo são erro médio absoluto, erro médio quadrático, e erro médio quadrático raiz. Executar o seguinte código para encontrar estes valores:
from sklearn import metricsprint('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))print('Root Mean Squared Error:', np.sqrt(metrics.mean_squared_error(y_test, y_pred)))A saída será algo parecido com isto:
Mean Absolute Error: 51.765Mean Squared Error: 4216.16675Root Mean Squared Error: 64.932016371Com 20 árvores, o erro quadrático médio de raiz é 64,93 que é superior a 10 por cento do consumo médio de gasolina, ou seja, 576,77. Isto pode indicar, entre outras coisas, que não utilizámos estimadores suficientes (árvores).
Se o número de estimadores for alterado para 200, os resultados são os seguintes:
Mean Absolute Error: 47.9825Mean Squared Error: 3469.7007375Root Mean Squared Error: 58.9041657058O gráfico seguinte mostra a diminuição do valor do erro quadrático médio da raiz (RMSE) no que diz respeito ao número de estimadores. Aqui o eixo X contém o número de estimadores enquanto que o eixo Y contém o valor do erro quadrático médio da raiz.
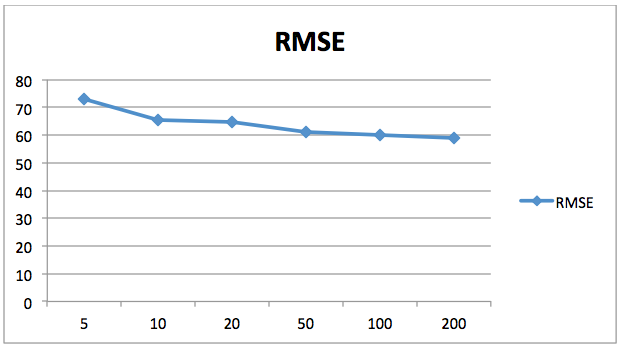
Vê-se que os valores de erro diminuem com o aumento do número de estimadores. Após 200 a taxa de diminuição do erro diminui, por isso 200 é um bom número para n_estimators. Pode brincar com o número de árvores e outros parâmetros para ver se consegue obter melhores resultados por si próprio.
Parte 2: Utilização de Floresta Aleatória para Classificação
Definição de Problema
A tarefa aqui é prever se uma nota de banco é autêntica ou não com base em quatro atributos i.e. variação da imagem wavelet transformada imagem, enviesamento, entropia, e curtosis da imagem.
Solução
Este é um problema de classificação binária e usaremos um classificador florestal aleatório para resolver este problema. Os passos seguidos para resolver este problema serão semelhantes aos passos executados para a regressão.
1. Import Libraries
import pandas as pdimport numpy as np2. Importing Dataset
O conjunto de dados pode ser descarregado a partir do seguinte link:
https://drive.google.com/file/d/13nw-uRXPY8XIZQxKRNZ3yYlho-CYm_Qt/view
p> A informação detalhada sobre os dados está disponível no seguinte link:
https://archive.ics.uci.edu/ml/datasets/banknote+authentication
O seguinte código importa o conjunto de dados:
dataset = pd.read_csv("D:/Datasets/bill_authentication.csv")Para obter uma visão de alto nível do conjunto de dados, executar o seguinte comando:
dataset.head()| Variância | Skewness | Curtosis | Entropia | Class | |
|---|---|---|---|---|---|
| 0 | 3.62160 | 8.6661 | -2.8073 | -0.44699 | 0 |
| 4.54590 | 8.1674 | -2.4586 | -1.46210 | 0 | |
| 2 | 3.86600 | -2.6383 | 1.9242 | 0.10645 | 0 |
| 3 | 3.45660 | 9.5228 | -4.0112 | -3.59440 | 0 |
| 4 | 0.32924 | -4.4552 | 4.5718 | -0.98880 | 0 |
Como era o caso do conjunto de dados de regressão, os valores neste conjunto de dados não são muito bem escalados. O conjunto de dados será escalonado antes do treino do algoritmo.
3. Preparação de dados para treino
O seguinte código divide os dados em atributos e etiquetas:
X = dataset.iloc.valuesy = dataset.iloc.valuesO seguinte código divide os dados em conjuntos de treino e testes:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)4. Escala de características
Como antes, a escala de características funciona da mesma forma:
# Feature Scalingfrom sklearn.preprocessing import StandardScalersc = StandardScaler()X_train = sc.fit_transform(X_train)X_test = sc.transform(X_test)5>5. Treino do Algoritmo
E mais uma vez, agora que já escalámos o nosso conjunto de dados, podemos treinar as nossas florestas aleatórias para resolver este problema de classificação. Para o fazer, executar o seguinte código:
from sklearn.ensemble import RandomForestRegressorregressor = RandomForestRegressor(n_estimators=20, random_state=0)regressor.fit(X_train, y_train)y_pred = regressor.predict(X_test) Em caso de regressão, utilizámos o RandomForestRegressor classe da biblioteca sklearn.ensemble. Para classificação, utilizaremos a RandomForestClassifier classe da biblioteca sklearn.ensemble. RandomForestClassifier class also takes n_estimators as a parâmetro. Como antes, este parâmetro define o número de árvores na nossa floresta aleatória. Vamos recomeçar com 20 árvores. Pode encontrar detalhes de todos os parâmetros de RandomForestClassifier aqui.
6. Avaliando o Algoritmo
Para problemas de classificação, as métricas utilizadas para avaliar um algoritmo são a exactidão, a matriz de confusão, a chamada de precisão, e os valores F1. Executar o seguinte script para encontrar estes valores:
from sklearn.metrics import classification_report, confusion_matrix, accuracy_scoreprint(confusion_matrix(y_test,y_pred))print(classification_report(y_test,y_pred))print(accuracy_score(y_test, y_pred))A saída será algo parecido com isto:
1 117]] precision recall f1-score support 0 0.99 0.99 0.99 157 1 0.98 0.99 0.99 118 avg / total 0.99 0.99 0.99 2750.989090909091A precisão alcançada pelo nosso classificador florestal aleatório com 20 árvores é de 98,90%. Ao contrário de antes, mudar o número de estimadores para este problema não melhorou significativamente os resultados, como mostra o gráfico seguinte. Aqui o eixo X contém o número de estimadores enquanto que o eixo Y mostra a precisão.
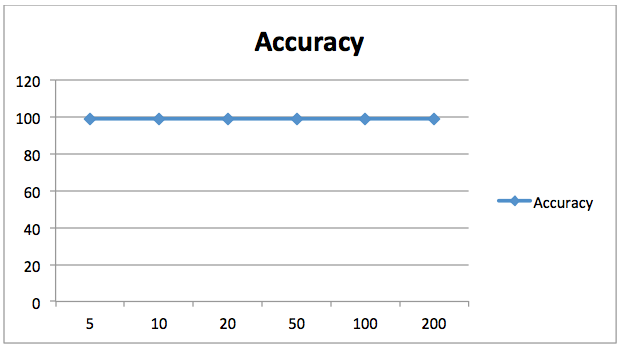 p>98,90% é uma precisão bastante boa, pelo que não faz muito sentido aumentar o nosso número de estimadores de qualquer forma. Podemos ver que aumentar o número de estimadores não melhorou ainda mais a precisão.
p>98,90% é uma precisão bastante boa, pelo que não faz muito sentido aumentar o nosso número de estimadores de qualquer forma. Podemos ver que aumentar o número de estimadores não melhorou ainda mais a precisão.
Para melhorar a precisão, sugiro que brinque com outros parâmetros da classe RandomForestClassifier e veja se consegue melhorar os nossos resultados.
Recursos
Quer saber mais sobre Scikit-Learn e outros algoritmos úteis de aprendizagem de máquinas como florestas aleatórias? Pode consultar alguns recursos mais detalhados, como um curso online:
- Data Science in Python, Pandas, Scikit-learn, Numpy, Matplotlib
- Python for Data Science and Machine Learning Bootcamp
- Machine Learning A-Z: Hands-On Python & R Em Ciência de Dados