Die Top 5 Software-Architekturmuster: Wie Sie die richtige Wahl treffen
Wie viele Handlungsmuster gibt es in Hollywood-Filmen? Manche Kritiker sagen, es gäbe nur fünf. Wie viele Möglichkeiten gibt es, ein Programm zu strukturieren? Im Moment verwenden die meisten Programme eine von fünf Architekturen.
Mark Richards ist ein in Boston ansässiger Softwarearchitekt, der seit mehr als 30 Jahren darüber nachdenkt, wie Daten durch Software fließen sollten. Sein neues (kostenloses) Buch, Software Architecture Patterns, konzentriert sich auf fünf Architekturen, die häufig verwendet werden, um Softwaresysteme zu organisieren. Der beste Weg, neue Programme zu planen, ist, sie zu studieren und ihre Stärken und Schwächen zu verstehen.
In diesem Artikel habe ich die fünf Architekturen zu einer Kurzreferenz der Stärken und Schwächen sowie der optimalen Anwendungsfälle destilliert. Denken Sie daran, dass Sie mehrere Muster in einem einzigen System verwenden können, um jeden Codeabschnitt mit der besten Architektur zu optimieren. Auch wenn man es Computerwissenschaft nennt, ist es oft eine Kunst.
Schicht-Architektur (n-tier)
Dieser Ansatz ist wahrscheinlich der häufigste, weil er normalerweise um die Datenbank herum aufgebaut ist, und viele Anwendungen in der Wirtschaft eignen sich natürlich dazu, Informationen in Tabellen zu speichern.
Dies ist so etwas wie eine sich selbst erfüllende Prophezeiung. Viele der größten und besten Software-Frameworks – wie Java EE, Drupal und Express – wurden mit dieser Struktur im Hinterkopf entwickelt, so dass viele der mit ihnen erstellten Anwendungen natürlich in einer Schichtenarchitektur erscheinen.
Der Code ist so angeordnet, dass die Daten in die oberste Schicht eintreten und sich ihren Weg nach unten durch jede Schicht bahnen, bis sie die unterste erreichen, die normalerweise eine Datenbank ist. Auf dem Weg dorthin hat jede Schicht eine bestimmte Aufgabe, wie z. B. die Überprüfung der Daten auf Konsistenz oder die Neuformatierung der Werte, um sie konsistent zu halten. Es ist üblich, dass verschiedene Programmierer unabhängig voneinander an verschiedenen Schichten arbeiten.
Bildnachweis: Izhaki
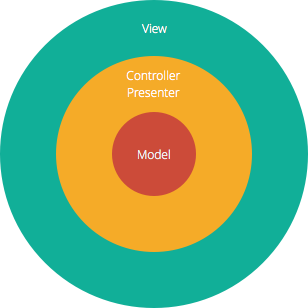
Die Model-View-Controller (MVC)-Struktur, die der Standard-Softwareentwicklungsansatz ist, der von den meisten populären Web-Frameworks angeboten wird, ist eindeutig eine Schichtenarchitektur. Direkt über der Datenbank befindet sich die Modellschicht, die oft Geschäftslogik und Informationen über die Datentypen in der Datenbank enthält. Ganz oben befindet sich die View-Schicht, die oft aus CSS, JavaScript und HTML mit dynamisch eingebettetem Code besteht. In der Mitte befindet sich der Controller, der über verschiedene Regeln und Methoden zur Transformation der Daten verfügt, die sich zwischen View und Model bewegen.
Der Vorteil einer Schichtenarchitektur ist die Trennung der Belange, was bedeutet, dass sich jede Schicht ausschließlich auf ihre Rolle konzentrieren kann. Dies macht es:
-
Wartbar
-
Testbar
-
Einfache Zuweisung von separaten „Rollen“
-
Einfache Aktualisierung und Erweiterung von Schichten getrennt
Proper Schichtenarchitekturen haben isolierte Schichten, die von bestimmten Änderungen in anderen Schichten nicht betroffen sind, was ein einfacheres Refactoring ermöglicht. Diese Architektur kann auch zusätzliche offene Schichten enthalten, wie z. B. eine Service-Schicht, die nur in der Business-Schicht auf gemeinsame Dienste zugreifen kann, aber auch aus Geschwindigkeitsgründen umgangen werden kann.
Die Aufteilung der Aufgaben und die Definition separater Schichten ist die größte Herausforderung für den Architekten. Wenn die Anforderungen gut zum Muster passen, lassen sich die Schichten leicht trennen und verschiedenen Programmierern zuweisen.
Caveats:
-
Der Quellcode kann sich in einen „großen Schlammball“ verwandeln, wenn er unorganisiert ist und die Module keine klaren Rollen oder Beziehungen haben.
-
Der Code kann langsam werden, dank dem, was einige Entwickler das „Sinkhole Anti-Pattern“ nennen. Ein großer Teil des Codes kann der Weitergabe von Daten durch die Schichten gewidmet sein, ohne dass eine Logik verwendet wird.
-
Die Isolierung der Schichten, die ein wichtiges Ziel für die Architektur ist, kann es auch schwierig machen, die Architektur zu verstehen, ohne jedes Modul zu verstehen.
-
Kodierer können Schichten überspringen, um eine enge Kopplung zu schaffen und ein logisches Durcheinander voller komplexer Abhängigkeiten zu erzeugen.
-
Monolithisches Deployment ist oft unvermeidbar, was bedeutet, dass kleine Änderungen ein komplettes Redeployment der Anwendung erfordern können.
Best für:
-
Neue Anwendungen, die schnell erstellt werden müssen
-
Unternehmens- oder Geschäftsanwendungen, die traditionelle IT-Abteilungen und -Prozesse widerspiegeln müssen
-
Teams mit unerfahrenen Entwicklern, die andere Architekturen noch nicht verstehen
-
Anwendungen, die strenge Standards für Wartbarkeit und Testbarkeit erfordern
Event-getriebene Architektur
Viele Programme verbringen den größten Teil ihrer Zeit damit, darauf zu warten, dass etwas passiert. Das gilt besonders für Computer, die direkt mit Menschen zusammenarbeiten, ist aber auch in Bereichen wie Netzwerken üblich. Manchmal gibt es Daten, die verarbeitet werden müssen, und manchmal nicht.
Die ereignisgesteuerte Architektur hilft dabei, dies zu bewältigen, indem sie eine zentrale Einheit aufbaut, die alle Daten annimmt und sie dann an die einzelnen Module weitergibt, die den jeweiligen Typ bearbeiten. Diese Weitergabe wird als „Ereignis“ bezeichnet und an den Code delegiert, der dem jeweiligen Typ zugeordnet ist.
Das Programmieren einer Webseite mit JavaScript beinhaltet das Schreiben der kleinen Module, die auf Ereignisse wie Mausklicks oder Tastendrücke reagieren. Der Browser selbst orchestriert alle Eingaben und sorgt dafür, dass nur der richtige Code die richtigen Ereignisse sieht. Viele verschiedene Arten von Ereignissen sind im Browser üblich, aber die Module interagieren nur mit den Ereignissen, die sie betreffen. Dies ist ein großer Unterschied zur Schichtenarchitektur, bei der alle Daten typischerweise alle Schichten durchlaufen. Insgesamt sind ereignisgesteuerte Architekturen:
-
Sind leicht an komplexe, oft chaotische Umgebungen anpassbar
-
Skalieren leicht
-
Sind leicht erweiterbar, wenn neue Ereignistypen auftauchen
Tests können komplex sein, wenn die Module sich gegenseitig beeinflussen können. Während einzelne Module unabhängig voneinander getestet werden können, können die Wechselwirkungen zwischen ihnen nur in einem voll funktionsfähigen System getestet werden.
Die Fehlerbehandlung kann schwierig zu strukturieren sein, besonders wenn mehrere Module die gleichen Ereignisse behandeln müssen.
Wenn Module ausfallen, muss die zentrale Einheit einen Backup-Plan haben.
Messaging-Overhead kann die Verarbeitungsgeschwindigkeit verlangsamen, insbesondere wenn die Zentraleinheit Nachrichten puffern muss, die in Schüben eintreffen.
Die Entwicklung einer systemweiten Datenstruktur für Ereignisse kann komplex sein, wenn die Ereignisse sehr unterschiedliche Anforderungen haben.
Die Aufrechterhaltung eines transaktionsbasierten Mechanismus für Konsistenz ist schwierig, da die Module so entkoppelt und unabhängig sind.
Best für:
-
Asynchrone Systeme mit asynchronem Datenfluss
-
Anwendungen, bei denen die einzelnen Datenblöcke nur mit wenigen der vielen Module interagieren
-
Benutzer Schnittstellen
Microkernel-Architektur
Viele Anwendungen haben einen Kernsatz von Operationen, die immer wieder in unterschiedlichen Mustern verwendet werden, die von den Daten und der jeweiligen Aufgabe abhängen. Das beliebte Entwicklungswerkzeug Eclipse zum Beispiel öffnet Dateien, versieht sie mit Anmerkungen, bearbeitet sie und startet Hintergrundprozessoren. Das Tool ist dafür bekannt, dass es all diese Aufgaben mit Java-Code erledigt und dann auf Knopfdruck den Code kompiliert und ausführt.
In diesem Fall sind die grundlegenden Routinen zum Anzeigen und Bearbeiten einer Datei Teil des Mikrokerns. Der Java-Compiler ist nur ein zusätzlicher Teil, der aufgeschraubt wird, um die Grundfunktionen des Mikrokerns zu unterstützen. Andere Programmierer haben Eclipse erweitert, um Code für andere Sprachen mit anderen Compilern zu entwickeln. Viele verwenden nicht einmal den Java-Compiler, aber sie alle nutzen die gleichen grundlegenden Routinen zum Bearbeiten und Kommentieren von Dateien.
Die zusätzlichen Funktionen, die darüber geschichtet werden, werden oft Plug-ins genannt. Viele bezeichnen diesen erweiterbaren Ansatz auch als Plug-in-Architektur.
Richards erklärt dies gerne mit einem Beispiel aus der Versicherungsbranche: „Die Schadenbearbeitung ist notwendigerweise komplex, aber die eigentlichen Schritte sind es nicht. Was sie komplex macht, sind all die Regeln.“
Die Lösung besteht darin, einige grundlegende Aufgaben – wie die Abfrage eines Namens oder die Überprüfung der Zahlung – in den Mikrokernel zu verlagern. Die verschiedenen Geschäftsbereiche können dann Plug-ins für die verschiedenen Arten von Ansprüchen schreiben, indem sie die Regeln mit Aufrufen zu den Grundfunktionen im Kernel zusammenstricken.
Caveats:
-
Die Entscheidung, was in den Mikrokernel gehört, ist oft eine Kunst. Er sollte den Code enthalten, der häufig verwendet wird.
-
Die Plug-ins müssen eine ordentliche Menge an Handshaking-Code enthalten, damit der Mikrokernel weiß, dass das Plug-in installiert und einsatzbereit ist.
-
Eine Modifikation des Mikrokerns kann sehr schwierig oder sogar unmöglich sein, wenn eine Reihe von Plug-Ins von ihm abhängt. Die einzige Lösung ist, auch die Plug-ins zu modifizieren.
-
Die Wahl der richtigen Granularität für die Kernel-Funktionen ist im Voraus schwer zu treffen, aber später fast unmöglich zu ändern.
Best für:
-
Werkzeuge, die von einer Vielzahl von Personen genutzt werden
-
Anwendungen mit einer klaren Trennung zwischen Basisroutinen und Regeln höherer Ordnung
-
Anwendungen mit einem festen Satz von Kernroutinen und einem dynamischen Satz von Regeln, die häufig aktualisiert werden müssen
Microservices-Architektur
Software kann wie ein Babyelefant sein: Sie ist niedlich und lustig, wenn sie klein ist, aber sobald sie groß wird, ist sie schwer zu steuern und resistent gegen Veränderungen. Die Microservice-Architektur soll Entwicklern helfen, ihre Babys nicht zu unhandlichen, monolithischen und unflexiblen Gebilden heranwachsen zu lassen. Anstatt ein einziges großes Programm zu bauen, besteht das Ziel darin, eine Reihe verschiedener kleiner Programme zu erstellen und dann jedes Mal ein neues kleines Programm zu erstellen, wenn jemand eine neue Funktion hinzufügen möchte. Stellen Sie sich eine Herde von Versuchskaninchen vor.
via GIPHY
„Wenn Sie auf Ihr iPad gehen und sich die Benutzeroberfläche von Netflix ansehen, kommt jede einzelne Sache auf dieser Oberfläche von einem anderen Dienst“, betont Richards. Die Liste Ihrer Favoriten, die Bewertungen, die Sie einzelnen Filmen geben, und die Buchhaltungsinformationen werden alle in separaten Chargen von separaten Diensten geliefert. Es ist, als ob Netflix eine Konstellation von Dutzenden kleinerer Websites ist, die sich nur zufällig als ein Dienst präsentiert.
Dieser Ansatz ähnelt dem ereignisgesteuerten und dem Mikrokernel-Ansatz, wird aber vor allem dann verwendet, wenn die verschiedenen Aufgaben leicht zu trennen sind. In vielen Fällen erfordern die verschiedenen Aufgaben unterschiedliche Mengen an Verarbeitung und können unterschiedlich genutzt werden. Die Server, die die Inhalte von Netflix ausliefern, werden am Freitag- und Samstagabend viel stärker beansprucht, so dass sie bereit sein müssen, hoch zu skalieren. Die Server, die DVD-Rücksendungen verfolgen, erledigen dagegen den Großteil ihrer Arbeit unter der Woche, gleich nachdem die Post die Tagespost zugestellt hat. Indem diese als separate Dienste implementiert werden, kann die Netflix-Cloud sie unabhängig hoch- und runterskalieren, wenn sich die Nachfrage ändert.
Caveats:
-
Die Dienste müssen weitgehend unabhängig sein, sonst kann die Interaktion zu einem Ungleichgewicht in der Cloud führen.
-
Nicht alle Anwendungen haben Aufgaben, die sich nicht einfach in unabhängige Einheiten aufteilen lassen.
-
Die Leistung kann leiden, wenn Aufgaben auf verschiedene Microservices verteilt werden. Die Kommunikationskosten können erheblich sein.
-
Zu viele Microservices können Benutzer verwirren, da Teile der Webseite viel später erscheinen als andere.
Best for:
-
Webseiten mit kleinen Komponenten
-
Unternehmensrechenzentren mit klar definierten Grenzen
-
Zügige Entwicklung neuer Unternehmen und Webanwendungen
-
Entwicklungsteams, die verstreut sind, oft über den ganzen Globus verstreut sind
Raumbasierte Architektur
Viele Websites sind um eine Datenbank herum aufgebaut, und sie funktionieren gut, solange die Datenbank mit der Last Schritt halten kann. Aber wenn die Nutzung Spitzenwerte erreicht und die Datenbank mit der ständigen Herausforderung, ein Protokoll der Transaktionen zu schreiben, nicht mithalten kann, fällt die gesamte Website aus.
Die raumbasierte Architektur wurde entwickelt, um einen funktionalen Zusammenbruch unter hoher Last zu vermeiden, indem sowohl die Verarbeitung als auch die Speicherung auf mehrere Server aufgeteilt werden. Die Daten werden auf die Knoten verteilt, ebenso wie die Verantwortung für die Bedienung der Aufrufe. Einige Architekten verwenden den eher amorphen Begriff „Cloud-Architektur“. Der Name „raumbasiert“ bezieht sich auf den „Tupelraum“ der Benutzer, der zerlegt wird, um die Arbeit zwischen den Knoten zu verteilen. „Es sind alles In-Memory-Objekte“, sagt Richards. „
Die raumbasierte Architektur unterstützt Dinge, die unvorhersehbare Spitzen haben, indem sie die Datenbank eliminiert.“
Die Speicherung der Informationen im RAM macht viele Jobs viel schneller, und die Verteilung der Speicherung mit der Verarbeitung kann viele grundlegende Aufgaben vereinfachen. Aber die verteilte Architektur kann einige Arten von Analysen komplexer machen. Berechnungen, die über den gesamten Datensatz verteilt werden müssen – wie z. B. die Ermittlung eines Durchschnittswerts oder eine statistische Analyse – müssen in Teilaufgaben aufgeteilt, auf alle Knoten verteilt und anschließend zusammengefasst werden.
Hinweise:
-
Die Transaktionsunterstützung ist bei RAM-Datenbanken schwieriger.
-
Genügend Last zu erzeugen, um das System zu testen, kann eine Herausforderung sein, aber die einzelnen Knoten können unabhängig voneinander getestet werden.
-
Das Know-how zu entwickeln, um die Daten für Geschwindigkeit zu cachen, ohne mehrere Kopien zu beschädigen, ist schwierig.
Best for:
-
Hochvolumige Daten wie Klickströme und Benutzerprotokolle
-
Niedrigwertige Daten, die gelegentlich ohne große Konsequenzen verloren gehen können – also keine Bankgeschäfte
-
Soziale Netzwerke