De top 5 software architectuurpatronen: Hoe maak je de juiste keuze
Hoeveel plots zijn er in Hollywoodfilms? Volgens sommige critici zijn het er maar vijf. Op hoeveel manieren kun je een programma structureren? Op dit moment maakt de meerderheid van de programma’s gebruik van een van de vijf architecturen.
Mark Richards is een in Boston gevestigde software-architect die al meer dan 30 jaar nadenkt over hoe gegevens door software zouden moeten stromen. Zijn nieuwe (gratis) boek, Software Architecture Patterns, richt zich op vijf architecturen die vaak worden gebruikt om softwaresystemen te organiseren. De beste manier om nieuwe programma’s te plannen is door ze te bestuderen en hun sterke en zwakke punten te begrijpen.
In dit artikel heb ik de vijf architecturen gedistilleerd tot een snelle referentie van de sterke en zwakke punten, evenals optimale use-cases. Vergeet niet dat je meerdere patronen in een enkel systeem kunt gebruiken om elk deel van de code te optimaliseren met de beste architectuur. Ook al noemen ze het informatica, het is vaak een kunst.
Gelaagde (n-tier) architectuur
Deze aanpak komt waarschijnlijk het meest voor omdat hij meestal rond de database is gebouwd, en veel toepassingen in het bedrijfsleven lenen zich van nature voor het opslaan van informatie in tabellen.
Dit is een soort self-fulfilling prophecy. Veel van de grootste en beste software frameworks, zoals Java EE, Drupal en Express, zijn gebouwd met deze structuur in het achterhoofd, dus veel van de toepassingen die ermee zijn gebouwd hebben van nature een gelaagde architectuur.
De code is zo opgezet dat de gegevens in de bovenste laag binnenkomen en zich een weg naar beneden banen tot ze de onderste laag bereiken, die meestal een database is. Onderweg heeft elke laag een specifieke taak, zoals het controleren van de gegevens op consistentie of het herformatteren van de waarden om ze consistent te houden. Het is gebruikelijk dat verschillende programmeurs onafhankelijk van elkaar aan verschillende lagen werken.
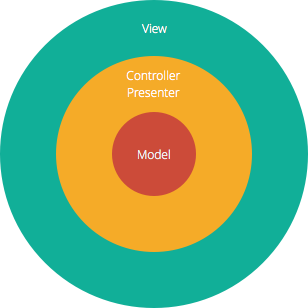
Image credit: Izhaki
De Model-View-Controller (MVC) structuur, de standaard software-ontwikkelingsaanpak die door de meeste populaire webframeworks wordt geboden, is duidelijk een gelaagde architectuur. Net boven de database bevindt zich de modellaag, die vaak bedrijfslogica bevat en informatie over de soorten gegevens in de database. Bovenaan staat de view-laag, die vaak bestaat uit CSS, JavaScript en HTML met dynamische embedded code. In het midden bevindt zich de controller, die verschillende regels en methoden bevat voor het transformeren van de gegevens die zich tussen de view en het model verplaatsen.
Het voordeel van een gelaagde architectuur is de scheiding van belangen, wat betekent dat elke laag zich uitsluitend op zijn rol kan richten. Dit maakt het:
-
Onderhoudbaar
-
Testbaar
-
Gemakkelijk om afzonderlijke “rollen “toe te wijzen
-
Gemakkelijk om lagen afzonderlijk bij te werken en te verbeteren
Een goede gelaagde architectuur heeft geïsoleerde lagen die niet worden beïnvloed door bepaalde wijzigingen in andere lagen, zodat ze gemakkelijker kunnen worden aangepast. Deze architectuur kan ook extra open lagen bevatten, zoals een servicelaag, die kan worden gebruikt om toegang te krijgen tot gedeelde services alleen in de bedrijfslaag, maar ook omzeild kan worden voor snelheid.
Het opknippen van de taken en het definiëren van afzonderlijke lagen is de grootste uitdaging voor de architect. Als de eisen goed in het patroon passen, zijn de lagen gemakkelijk te scheiden en toe te wijzen aan verschillende programmeurs.
Vervaringen:
-
Broncode kan een “grote modderbal” worden als deze ongeorganiseerd is en de modules geen duidelijke rollen of relaties hebben.
-
Code kan traag worden dankzij wat sommige ontwikkelaars het “sinkhole anti-pattern” noemen. Een groot deel van de code kan worden gewijd aan het doorgeven van gegevens door lagen zonder enige logica te gebruiken.
-
Lagenisolatie, een belangrijk doel voor de architectuur, kan het ook moeilijk maken om de architectuur te begrijpen zonder elke module te begrijpen.
-
Coders kunnen lagen overslaan om een strakke koppeling te creëren en een logische warboel vol complexe onderlinge afhankelijkheden te produceren.
-
Monolithische implementatie is vaak onvermijdelijk, wat betekent dat kleine wijzigingen een volledige herimplementatie van de applicatie kunnen vereisen.
Beste voor:
-
Nieuwe applicaties die snel moeten worden gebouwd
-
Enterprise- of bedrijfsapplicaties die traditionele IT-afdelingen en -processen moeten weerspiegelen
-
Teams met onervaren ontwikkelaars die andere architecturen nog niet begrijpen
-
Applicaties die strikte normen voor onderhoudbaarheid en testbaarheid vereisen
Event-driven architecture
Veel programma’s brengen het grootste deel van hun tijd door met wachten tot er iets gebeurt. Dit geldt met name voor computers die direct met mensen samenwerken, maar het komt ook vaak voor in gebieden als netwerken. De ene keer is er data die verwerkt moet worden, de andere keer niet.
De event-driven architectuur helpt dit te beheersen door een centrale eenheid te bouwen die alle data accepteert en deze vervolgens delegeert aan de afzonderlijke modules die het specifieke type verwerken. Deze overdracht wordt een “gebeurtenis” genoemd, en deze wordt gedelegeerd aan de code die aan dat type is toegewezen.
Het programmeren van een webpagina met JavaScript omvat het schrijven van de kleine modules die reageren op gebeurtenissen zoals muisklikken of toetsaanslagen. De browser zelf orkestreert alle invoer en zorgt ervoor dat alleen de juiste code de juiste gebeurtenissen te zien krijgt. Veel verschillende soorten gebeurtenissen komen voor in de browser, maar de modules reageren alleen op de gebeurtenissen die hen betreffen. Dit is heel anders dan de gelaagde architectuur waar alle data typisch door alle lagen gaat. Over het geheel genomen zijn event-driven architecturen:
-
Zijn gemakkelijk aan te passen aan complexe, vaak chaotische omgevingen
-
Schalen gemakkelijk
-
Zijn gemakkelijk uit te breiden wanneer nieuwe gebeurtenistypen verschijnen
Caveats:
-
Het testen kan ingewikkeld zijn als de modules elkaar kunnen beïnvloeden. Afzonderlijke modules kunnen onafhankelijk van elkaar worden getest, maar de interacties tussen de modules kunnen alleen in een volledig functionerend systeem worden getest.
-
Foutafhandeling kan moeilijk te structureren zijn, vooral wanneer verschillende modules dezelfde gebeurtenissen moeten afhandelen.
-
Wanneer modules falen, moet de centrale eenheid een back-upplan hebben.
-
Messaging overhead kan de verwerkingssnelheid vertragen, met name wanneer de centrale eenheid berichten moet bufferen die in vlagen binnenkomen.
-
Het ontwikkelen van een systeembrede datastructuur voor gebeurtenissen kan complex zijn wanneer de gebeurtenissen zeer verschillende behoeften hebben.
-
Het onderhouden van een op transacties gebaseerd mechanisme voor consistentie is moeilijk omdat de modules zo ontkoppeld en onafhankelijk zijn.
Beste voor:
-
Asynchrone systemen met asynchrone gegevensstromen
-
Toepassingen waarbij de afzonderlijke gegevensblokken slechts met enkele van de vele modules interageren
-
Gebruikers interfaces
Microkernel-architectuur
Veel toepassingen hebben een kernset van bewerkingen die steeds opnieuw worden gebruikt in verschillende patronen die afhankelijk zijn van de gegevens en de taak die worden uitgevoerd. Het populaire ontwikkelgereedschap Eclipse, bijvoorbeeld, opent bestanden, annoteert ze, bewerkt ze, en start achtergrondprocessoren. De tool staat erom bekend al deze taken uit te voeren met Java code en vervolgens, als er op een knop wordt gedrukt, de code te compileren en uit te voeren.
In dit geval maken de basisroutines voor het weergeven van een bestand en het bewerken ervan deel uit van de microkernel. De Java compiler is slechts een extra onderdeel dat is vastgeschroefd om de basisfuncties in de microkernel te ondersteunen. Andere programmeurs hebben Eclipse uitgebreid om code te ontwikkelen voor andere talen met andere compilers. Velen gebruiken niet eens de Java compiler, maar ze gebruiken allemaal dezelfde basis routines voor het bewerken en annoteren van bestanden.
De extra functies die er bovenop worden gelegd worden vaak plug-ins genoemd. Velen noemen deze uitbreidbare aanpak in plaats daarvan een plug-in architectuur.
Richards legt dit graag uit met een voorbeeld uit de verzekeringswereld: “Het verwerken van claims is noodzakelijkerwijs complex, maar de feitelijke stappen zijn dat niet. Wat het complex maakt, zijn alle regels.”
De oplossing is om een aantal basistaken, zoals het vragen naar een naam of het controleren van de betaling, in de microkernel te plaatsen. De verschillende bedrijfsonderdelen kunnen dan plug-ins schrijven voor de verschillende soorten claims door de regels aan elkaar te breien met aanroepen naar de basisfuncties in de kernel.
Caveats:
-
Beslissen wat in de microkernel thuishoort, is vaak een kunst. Het moet de code bevatten die vaak wordt gebruikt.
-
De plug-ins moeten een behoorlijke hoeveelheid handshaking-code bevatten, zodat de microkernel weet dat de plug-in is geïnstalleerd en klaar is om te werken.
-
Het wijzigen van de microkernel kan erg moeilijk of zelfs onmogelijk zijn wanneer een aantal plug-ins ervan afhankelijk is. De enige oplossing is om ook de plug-ins aan te passen.
-
Het kiezen van de juiste granulariteit voor de kernelfuncties is van tevoren moeilijk te doen, maar later in het spel vrijwel onmogelijk te veranderen.
Beste voor:
-
Tools die door een grote verscheidenheid aan mensen worden gebruikt
-
Toepassingen met een duidelijke verdeling tussen basisroutines en regels van hogere orde
-
Toepassingen met een vaste set basisroutines en een dynamische set regels die regelmatig moeten worden bijgewerkt
Microservices-architectuur
Software kan net een babyolifantje zijn: Het is schattig en leuk als het klein is, maar zodra het groot wordt, is het moeilijk te besturen en resistent tegen verandering. De microservice-architectuur is ontworpen om ontwikkelaars te helpen voorkomen dat hun baby’s uitgroeien tot logge, monolithische en inflexibele olifanten. In plaats van één groot programma te bouwen, is het de bedoeling om een aantal verschillende kleine programma’s te maken en dan een nieuw klein programma te maken telkens als iemand een nieuwe functie wil toevoegen. Denk aan een kudde proefkonijnen.
via GIPHY
“Als je op je iPad naar de UI van Netflix kijkt, komt elk ding op die interface van een aparte dienst”, zegt Richards. De lijst met je favorieten, de ratings die je aan individuele films geeft, en de boekhoudkundige informatie worden allemaal in aparte batches geleverd door aparte diensten. Het is alsof Netflix een constellatie is van tientallen kleinere websites die zich toevallig als één dienst presenteren.
Deze aanpak lijkt op de event-driven en microkernel benaderingen, maar wordt vooral gebruikt als de verschillende taken gemakkelijk te scheiden zijn. In veel gevallen kunnen verschillende taken verschillende hoeveelheden verwerking vereisen en kunnen ze verschillen in gebruik. De servers die de inhoud van Netflix leveren, worden op vrijdag- en zaterdagavond veel zwaarder belast, dus moeten ze klaar zijn om op te schalen. De servers die dvd-retours bijhouden, daarentegen, doen het grootste deel van hun werk tijdens de week, net nadat het postkantoor de post van die dag heeft bezorgd. Door deze als afzonderlijke diensten te implementeren, kan de Netflix-cloud ze onafhankelijk op- en afschalen als de vraag verandert.
Caveats:
-
De services moeten grotendeels onafhankelijk zijn, anders kan interactie ervoor zorgen dat de cloud uit balans raakt.
-
Niet alle applicaties hebben taken die niet eenvoudig in onafhankelijke eenheden kunnen worden opgesplitst.
-
De prestaties kunnen eronder lijden wanneer taken over verschillende microservices worden verspreid. De communicatiekosten kunnen aanzienlijk zijn.
-
Te veel microservices kunnen gebruikers in verwarring brengen doordat delen van de webpagina veel later verschijnen dan andere.
Beste voor:
-
Websites met kleine componenten
-
Corporate datacenters met goed gedefinieerde grenzen
-
Snelle ontwikkeling van nieuwe bedrijven en webapplicaties
-
Ontwikkelingsteams die verspreid zijn, vaak over de hele wereld
Ruimtegebaseerde architectuur
Veel websites zijn gebouwd rond een database, en ze functioneren goed zolang de database de belasting kan bijhouden. Maar wanneer het gebruik piekt, en de database de constante uitdaging van het schrijven van een log van de transacties niet kan bijhouden, valt de hele website uit.
De space-based architectuur is ontworpen om functionele ineenstorting onder hoge belasting te voorkomen door zowel de verwerking als de opslag over meerdere servers te verdelen. De gegevens worden over de nodes verdeeld, net als de verantwoordelijkheid voor het afhandelen van de oproepen. Sommige architecten gebruiken de meer amorfe term “cloud-architectuur”. De naam “space-based” verwijst naar de “tuple space” van de gebruikers, die wordt opgedeeld om het werk te verdelen over de nodes. “Het zijn allemaal in-memory objecten,” zegt Richards. “De space-based architectuur ondersteunt dingen die onvoorspelbare pieken hebben door de database te elimineren.”
Het opslaan van de informatie in RAM maakt veel taken veel sneller, en het spreiden van de opslag met de verwerking kan veel basistaken vereenvoudigen. Maar de gedistribueerde architectuur kan sommige soorten analyses complexer maken. Berekeningen die over de hele gegevensverzameling moeten worden verspreid – zoals het vinden van een gemiddelde of het uitvoeren van een statistische analyse – moeten in subtaken worden opgesplitst, over alle knooppunten worden verspreid, en dan worden samengevoegd als ze klaar zijn.
Caveats:
-
Transactionele ondersteuning is moeilijker met RAM-databases.
-
Het genereren van voldoende belasting om het systeem te testen kan een uitdaging zijn, maar de afzonderlijke nodes kunnen onafhankelijk worden getest.
-
Het ontwikkelen van de expertise om de gegevens te cachen voor snelheid zonder meerdere kopieën te corrumperen is moeilijk.
Beste voor:
-
Gegevens met hoge volumes, zoals klikstreams en gebruikerslogboeken
-
Gegevens van geringe waarde die af en toe verloren kunnen gaan zonder grote gevolgen – met andere woorden, geen banktransacties
-
Sociale netwerken