Los 5 mejores patrones de arquitectura de software: Cómo elegir bien
¿Cuántas tramas hay en las películas de Hollywood? Algunos críticos dicen que sólo hay cinco. De cuántas maneras se puede estructurar un programa? Ahora mismo, la mayoría de los programas utilizan una de las cinco arquitecturas.
Mark Richards es un arquitecto de software con sede en Boston que lleva más de 30 años pensando en cómo deben fluir los datos a través del software. Su nuevo libro (gratuito), Software Architecture Patterns, se centra en cinco arquitecturas que se utilizan habitualmente para organizar los sistemas de software. La mejor manera de planificar nuevos programas es estudiarlos y entender sus puntos fuertes y débiles.
En este artículo, he destilado las cinco arquitecturas en una referencia rápida de los puntos fuertes y débiles, así como los casos de uso óptimos. Recuerda que puedes utilizar múltiples patrones en un mismo sistema para optimizar cada sección de código con la mejor arquitectura. Aunque lo llamen informática, a menudo es un arte.
Arquitectura en capas (n-capas)
Este enfoque es probablemente el más común porque suele construirse en torno a la base de datos, y muchas aplicaciones en los negocios se prestan naturalmente a almacenar información en tablas.
Esto es una especie de profecía autocumplida. Muchos de los mayores y mejores frameworks de software -como Java EE, Drupal y Express- se construyeron con esta estructura en mente, por lo que muchas de las aplicaciones construidas con ellos se presentan de forma natural en una arquitectura de capas.
El código se organiza de manera que los datos entran en la capa superior y se abren camino hacia abajo en cada capa hasta llegar a la parte inferior, que suele ser una base de datos. A lo largo del camino, cada capa tiene una tarea específica, como la comprobación de la consistencia de los datos o el reformateo de los valores para mantener la coherencia. Es habitual que diferentes programadores trabajen de forma independiente en diferentes capas.
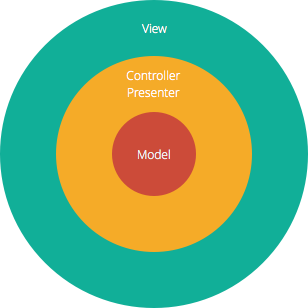
Image credit: Izhaki
La estructura Modelo-Vista-Controlador (MVC), que es el enfoque de desarrollo de software estándar que ofrecen la mayoría de los frameworks web más populares, es claramente una arquitectura por capas. Justo encima de la base de datos está la capa de modelo, que suele contener la lógica de negocio y la información sobre los tipos de datos de la base de datos. En la parte superior está la capa de vista, que a menudo es CSS, JavaScript y HTML con código dinámico incrustado. En el medio, tienes el controlador, que tiene varias reglas y métodos para transformar los datos que se mueven entre la vista y el modelo.
La ventaja de una arquitectura en capas es la separación de preocupaciones, lo que significa que cada capa puede centrarse únicamente en su papel. Esto hace que:
-
Mantenible
-
Testable
-
Fácil de asignar «roles»
-
Fácil de actualizar y mejorar las capas por separado
-
El código fuente puede convertirse en una «gran bola de barro» si no está organizado y los módulos no tienen roles o relaciones claras.
-
El código puede acabar siendo lento gracias a lo que algunos desarrolladores llaman el «antipatrón del sumidero». Gran parte del código puede dedicarse a pasar datos a través de las capas sin utilizar ninguna lógica.
-
El aislamiento de las capas, que es un objetivo importante para la arquitectura, también puede hacer que sea difícil entender la arquitectura sin entender cada módulo.
-
Los codificadores pueden saltarse las capas para crear un acoplamiento estrecho y producir un lío lógico lleno de interdependencias complejas.
-
El despliegue monolítico es a menudo inevitable, lo que significa que pequeños cambios pueden requerir un redespliegue completo de la aplicación.
-
Nuevas aplicaciones que necesitan ser construidas rápidamente
-
Aplicaciones empresariales o de negocio que necesitan reflejar los departamentos y procesos tradicionales de TI
-
Equipos con desarrolladores inexpertos que aún no entienden otras arquitecturas
-
Aplicaciones que requieren estrictas normas de mantenibilidad y testabilidad
-
Son fácilmente adaptables a entornos complejos, a menudo caóticos
-
Se escalan fácilmente
-
Son fácilmente ampliables cuando aparecen nuevos tipos de eventos
-
Las pruebas pueden ser complejas si los módulos pueden afectarse entre sí. Mientras que los módulos individuales pueden probarse de forma independiente, las interacciones entre ellos sólo pueden probarse en un sistema en pleno funcionamiento.
-
El manejo de errores puede ser difícil de estructurar, especialmente cuando varios módulos deben manejar los mismos eventos.
-
Cuando los módulos fallan, la unidad central debe tener un plan de respaldo.
-
La sobrecarga de la mensajería puede ralentizar la velocidad de procesamiento, especialmente cuando la unidad central debe almacenar en el búfer los mensajes que llegan en ráfagas.
-
Desarrollar una estructura de datos a nivel de sistema para los eventos puede ser complejo cuando los eventos tienen necesidades muy diferentes.
-
Mantener un mecanismo de consistencia basado en transacciones es difícil porque los módulos están muy desacoplados y son independientes.
-
Sistemas asíncronos con flujo de datos asíncronos
-
Aplicaciones en las que los bloques de datos individuales interactúan con sólo unos pocos de los muchos módulos
-
Usuario interfaces
-
Decidir qué pertenece al micronúcleo es a menudo un arte. Debe contener el código que se utiliza con frecuencia.
-
Los plug-ins deben incluir una buena cantidad de código handshaking para que el microkernel sea consciente de que el plug-in está instalado y listo para trabajar.
-
Modificar el micronúcleo puede ser muy difícil o incluso imposible una vez que varios plug-ins dependen de él. La única solución es modificar también los plug-ins.
-
Elegir la granularidad adecuada para las funciones del kernel es difícil de hacer de antemano pero casi imposible de cambiar más adelante.
-
Herramientas utilizadas por una gran variedad de personas
-
Aplicaciones con una clara división entre rutinas básicas y reglas de orden superior
-
Aplicaciones con un conjunto fijo de rutinas básicas y un conjunto dinámico de reglas que deben actualizarse con frecuencia
-
Los servicios deben ser en gran medida independientes o, de lo contrario, la interacción puede hacer que la nube se desequilibre.
-
No todas las aplicaciones tienen tareas que no puedan dividirse fácilmente en unidades independientes.
-
El rendimiento puede verse afectado cuando las tareas se reparten entre diferentes microservicios. Los costes de comunicación pueden ser significativos.
-
Demasiados microservicios pueden confundir a los usuarios ya que algunas partes de la página web aparecen mucho más tarde que otras.
-
Sitios web con componentes pequeños
-
Centros de datos corporativos con límites bien definidos
-
Desarrollar rápidamente nuevos negocios y aplicaciones web
-
Equipos de desarrollo que están repartidos, a menudo en todo el mundo
-
El soporte transaccional es más difícil con las bases de datos RAM.
-
Generar suficiente carga para probar el sistema puede ser un reto, pero los nodos individuales pueden ser probados de forma independiente.
-
Desarrollar la experiencia para almacenar en caché los datos para obtener velocidad sin corromper múltiples copias es difícil.
-
Datos de gran volumen como flujos de clics y registros de usuarios
-
Datos de poco valor que pueden perderse ocasionalmente sin grandes consecuencias-en otras palabras, no transacciones bancarias
-
Redes sociales
Las arquitecturas en capas adecuadas tendrán capas aisladas que no se ven afectadas por ciertos cambios en otras capas, permitiendo una refactorización más fácil. Esta arquitectura también puede contener capas abiertas adicionales, como una capa de servicio, que se puede utilizar para acceder a servicios compartidos sólo en la capa de negocio, pero que también se omite para la velocidad.
La división de las tareas y la definición de capas separadas es el mayor desafío para el arquitecto. Cuando los requisitos se ajustan bien al patrón, las capas serán fáciles de separar y asignar a diferentes programadores.
Caveats:
Mejor para:
Arquitectura dirigida por eventosdriven architecture
Muchos programas pasan la mayor parte de su tiempo esperando a que ocurra algo. Esto es especialmente cierto para los ordenadores que trabajan directamente con los humanos, pero también es común en áreas como las redes. A veces hay datos que necesitan ser procesados, y otras veces no.
La arquitectura dirigida por eventos ayuda a gestionar esto mediante la construcción de una unidad central que acepta todos los datos y luego los delega a los módulos separados que manejan el tipo particular. Se dice que este traspaso genera un «evento», y se delega en el código asignado a ese tipo.
Programar una página web con JavaScript implica escribir los pequeños módulos que reaccionan a eventos como clics del ratón o pulsaciones de teclas. El propio navegador orquesta toda la entrada y se asegura de que sólo el código correcto vea los eventos adecuados. Hay muchos tipos de eventos diferentes en el navegador, pero los módulos interactúan sólo con los eventos que les conciernen. Esto es muy diferente de la arquitectura por capas, donde todos los datos suelen pasar por todas las capas. En general, las arquitecturas basadas en eventos:
Caveats:
Mejor para:
Arquitectura del micronúcleo
Muchas aplicaciones tienen un conjunto básico de operaciones que se utilizan una y otra vez en diferentes patrones que dependen de los datos y de la tarea en cuestión. La popular herramienta de desarrollo Eclipse, por ejemplo, abre archivos, los anota, los edita y pone en marcha procesadores en segundo plano. La herramienta es famosa por realizar todas estas tareas con código Java y luego, cuando se pulsa un botón, compilar el código y ejecutarlo.
En este caso, las rutinas básicas para mostrar un archivo y editarlo forman parte del micronúcleo. El compilador de Java es sólo una parte extra que se atornilla para soportar las características básicas del micronúcleo. Otros programadores han ampliado Eclipse para desarrollar código para otros lenguajes con otros compiladores. Muchos ni siquiera utilizan el compilador de Java, pero todos usan las mismas rutinas básicas para editar y anotar archivos.
Las características extra que se superponen suelen llamarse plug-ins. Muchos llaman a este enfoque extensible una arquitectura de complementos.
A Richards le gusta explicar esto con un ejemplo del negocio de los seguros: «El procesamiento de reclamaciones es necesariamente complejo, pero los pasos reales no lo son. Lo que lo hace complejo son todas las reglas»
La solución es empujar algunas tareas básicas -como pedir un nombre o comprobar el pago- al micronúcleo. A continuación, las distintas unidades de negocio pueden escribir complementos para los distintos tipos de reclamaciones, tejiendo las reglas con llamadas a las funciones básicas del núcleo.
Caveats:
Mejor para:
Arquitectura de microservicios
El software puede ser como un bebé elefante: Es lindo y divertido cuando es pequeño, pero una vez que se hace grande, es difícil de dirigir y resistente al cambio. La arquitectura de microservicios está diseñada para ayudar a los desarrolladores a evitar que sus bebés crezcan hasta convertirse en algo difícil de manejar, monolítico e inflexible. En lugar de construir un gran programa, el objetivo es crear una serie de pequeños programas diferentes y luego crear un nuevo programa pequeño cada vez que alguien quiera añadir una nueva característica. Piensa en una manada de conejillos de indias.
via GIPHY
«Si vas a tu iPad y miras la interfaz de usuario de Netflix, cada cosa de esa interfaz viene de un servicio distinto», señala Richards. La lista de tus favoritos, las calificaciones que das a las películas individuales y la información contable se entregan en lotes separados por servicios separados. Es como si Netflix fuera una constelación de docenas de sitios web más pequeños que simplemente se presenta como un solo servicio.
Este enfoque es similar a los enfoques basados en eventos y en micronúcleos, pero se utiliza principalmente cuando las diferentes tareas son fácilmente separables. En muchos casos, las diferentes tareas pueden requerir diferentes cantidades de procesamiento y pueden variar en su uso. Los servidores que distribuyen los contenidos de Netflix se ven sometidos a una presión mucho mayor los viernes y sábados por la noche, por lo que deben estar preparados para escalar. Los servidores que hacen el seguimiento de las devoluciones de DVD, por otro lado, hacen la mayor parte de su trabajo durante la semana, justo después de que la oficina de correos entregue el correo del día. Al implementarlos como servicios separados, la nube de Netflix puede escalarlos de forma independiente según cambie la demanda.
Caveats:
Mejor para:
Arquitectura basada en el espacio
Muchos sitios web se construyen en torno a una base de datos, y funcionan bien siempre que la base de datos sea capaz de mantener la carga. Pero cuando el uso alcanza su punto máximo, y la base de datos no puede seguir el ritmo del desafío constante de escribir un registro de las transacciones, todo el sitio web falla.
La arquitectura basada en el espacio está diseñada para evitar el colapso funcional bajo una alta carga, dividiendo tanto el procesamiento como el almacenamiento entre múltiples servidores. Los datos se reparten entre los nodos al igual que la responsabilidad de atender las llamadas. Algunos arquitectos utilizan el término más amorfo de «arquitectura en la nube». El nombre «basado en el espacio» se refiere al «espacio de tuplas» de los usuarios, que se recorta para repartir el trabajo entre los nodos. «Todo son objetos en memoria», dice Richards. «La arquitectura basada en el espacio soporta cosas que tienen picos impredecibles al eliminar la base de datos».
Almacenar la información en RAM hace que muchos trabajos sean mucho más rápidos, y repartir el almacenamiento con el procesamiento puede simplificar muchas tareas básicas. Pero la arquitectura distribuida puede hacer más complejos algunos tipos de análisis. Los cálculos que deben repartirse por todo el conjunto de datos -como la búsqueda de una media o la realización de un análisis estadístico- deben dividirse en subtrabajos, repartidos por todos los nodos, y luego agregarse cuando hayan terminado.
Caveats:
Mejor para:
.