Les 5 principaux modèles d’architecture logicielle : Comment faire le bon choix
Combien d’intrigues y a-t-il dans les films hollywoodiens ? Certains critiques disent qu’il n’y en a que cinq. De combien de façons peut-on structurer un programme ? À l’heure actuelle, la majorité des programmes utilisent l’une des cinq architectures.
Mark Richards est un architecte logiciel basé à Boston qui réfléchit depuis plus de 30 ans à la façon dont les données doivent circuler dans les logiciels. Son nouveau livre (gratuit), Software Architecture Patterns, se concentre sur cinq architectures couramment utilisées pour organiser les systèmes logiciels. La meilleure façon de planifier de nouveaux programmes est de les étudier et de comprendre leurs forces et leurs faiblesses.
Dans cet article, j’ai distillé les cinq architectures en une référence rapide des forces et des faiblesses, ainsi que des cas d’utilisation optimaux. N’oubliez pas que vous pouvez utiliser plusieurs patterns dans un seul système pour optimiser chaque section de code avec la meilleure architecture. Même si on appelle cela de l’informatique, c’est souvent un art.
Architecture en couches (n-tiers)
Cette approche est probablement la plus courante parce qu’elle est généralement construite autour de la base de données, et de nombreuses applications en entreprise se prêtent naturellement au stockage d’informations dans des tableaux.
C’est en quelque sorte une prophétie auto-réalisatrice. Beaucoup des plus grands et des meilleurs cadres logiciels – comme Java EE, Drupal et Express – ont été construits avec cette structure à l’esprit, de sorte que de nombreuses applications construites avec eux sortent naturellement dans une architecture en couches.
Le code est organisé de sorte que les données entrent dans la couche supérieure et font leur chemin vers le bas de chaque couche jusqu’à ce qu’elles atteignent le bas, qui est généralement une base de données. En cours de route, chaque couche a une tâche spécifique, comme vérifier la cohérence des données ou reformater les valeurs pour les garder cohérentes. Il est courant que différents programmeurs travaillent indépendamment sur différentes couches.
Crédit image : Izhaki
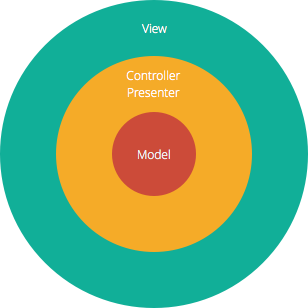
La structure Modèle-Vue-Contrôleur (MVC), qui est l’approche de développement logiciel standard proposée par la plupart des frameworks web populaires, est clairement une architecture en couches. Juste au-dessus de la base de données se trouve la couche modèle, qui contient souvent la logique métier et des informations sur les types de données de la base. Au sommet se trouve la couche de visualisation, qui est souvent constituée de CSS, JavaScript et HTML avec du code dynamique intégré. Au milieu, vous avez le contrôleur, qui a diverses règles et méthodes pour transformer les données se déplaçant entre la vue et le modèle.
L’avantage d’une architecture en couches est la séparation des préoccupations, ce qui signifie que chaque couche peut se concentrer uniquement sur son rôle. Cela permet de :
-
Maintenable
-
Testable
-
Facile d’attribuer des « rôles » séparés
-
Facile de mettre à jour et d’améliorer les couches séparément
Des architectures en couches appropriées auront des couches isolées qui ne sont pas affectées par certains changements dans d’autres couches, permettant une refactorisation plus facile. Cette architecture peut également contenir des couches ouvertes supplémentaires, comme une couche de services, qui peuvent être utilisées pour accéder à des services partagés uniquement dans la couche métier, mais aussi être contournées pour plus de rapidité.
La répartition des tâches et la définition de couches distinctes constituent le plus grand défi pour l’architecte. Lorsque les exigences correspondent bien au patron, les couches seront faciles à séparer et à attribuer à différents programmeurs.
Caveurs:
-
Le code source peut se transformer en une « grosse boule de boue » s’il n’est pas organisé et que les modules n’ont pas de rôles ou de relations claires.
-
Le code peut finir par être lent grâce à ce que certains développeurs appellent l' »anti-pattern du gouffre ». Une grande partie du code peut être consacrée au passage des données à travers les couches sans utiliser aucune logique.
-
L’isolation des couches, qui est un objectif important pour l’architecture, peut également rendre difficile la compréhension de l’architecture sans comprendre chaque module.
-
Les codeurs peuvent sauter des couches pour créer un couplage étroit et produire un fouillis logique plein d’interdépendances complexes.
-
Le déploiement monolithique est souvent inévitable, ce qui signifie que de petites modifications peuvent nécessiter un redéploiement complet de l’application.
Le meilleur pour :
-
Nouvelles applications qui doivent être construites rapidement
-
Les applications d’entreprise ou commerciales qui doivent refléter les départements et processus informatiques traditionnels
-
Équipes. avec des développeurs inexpérimentés qui ne comprennent pas encore d’autres architectures
-
Applications nécessitant des normes strictes de maintenabilité et de testabilité
L’architecture pilotée par les événements-driven architecture
De nombreux programmes passent la plupart de leur temps à attendre que quelque chose se passe. C’est particulièrement vrai pour les ordinateurs qui travaillent directement avec les humains, mais c’est aussi courant dans des domaines comme les réseaux. Parfois, il y a des données qui ont besoin d’être traitées, et d’autres fois, il n’y en a pas.
L’architecture événementielle aide à gérer cela en construisant une unité centrale qui accepte toutes les données et les délègue ensuite aux modules séparés qui traitent le type particulier. On dit que ce transfert génère un « événement », et il est délégué au code affecté à ce type.
Programmer une page web avec JavaScript implique d’écrire les petits modules qui réagissent aux événements tels que les clics de souris ou les frappes au clavier. Le navigateur lui-même orchestre l’ensemble des entrées et s’assure que seul le bon code voit les bons événements. De nombreux types d’événements différents sont courants dans le navigateur, mais les modules n’interagissent qu’avec les événements qui les concernent. C’est très différent de l’architecture en couches où toutes les données passent généralement par toutes les couches. Dans l’ensemble, les architectures pilotées par les événements :
-
Sont facilement adaptables à des environnements complexes, souvent chaotiques
-
Facilement évolutives
-
Facilement extensibles lorsque de nouveaux types d’événements apparaissent
Caveats :
-
Les tests peuvent être complexes si les modules peuvent s’affecter mutuellement. Si les modules individuels peuvent être testés indépendamment, les interactions entre eux ne peuvent être testées que dans un système entièrement fonctionnel.
-
La gestion des erreurs peut être difficile à structurer, en particulier lorsque plusieurs modules doivent gérer les mêmes événements.
-
Lorsque les modules tombent en panne, l’unité centrale doit avoir un plan de secours.
-
La surcharge de messagerie peut ralentir la vitesse de traitement, en particulier lorsque l’unité centrale doit mettre en mémoire tampon les messages qui arrivent en rafales.
-
Développer une structure de données à l’échelle du système pour les événements peut être complexe lorsque les événements ont des besoins très différents.
-
Maintenir un mécanisme de cohérence basé sur les transactions est difficile car les modules sont tellement découplés et indépendants.
Le meilleur pour :
-
Systèmes asynchrones avec flux de données asynchrones
-
Applications où les blocs de données individuels interagissent avec seulement quelques-uns des nombreux modules
-
Utilisateurs. interfaces
Architecture micro-noyau
De nombreuses applications ont un ensemble d’opérations de base qui sont utilisées encore et encore dans différents modèles qui dépendent des données et de la tâche à accomplir. L’outil de développement populaire Eclipse, par exemple, ouvrira des fichiers, les annotera, les modifiera et lancera des processeurs en arrière-plan. L’outil est célèbre pour effectuer toutes ces tâches avec du code Java, puis, lorsqu’on appuie sur un bouton, pour compiler le code et l’exécuter.
Dans ce cas, les routines de base pour afficher un fichier et le modifier font partie du micro-noyau. Le compilateur Java n’est qu’une pièce supplémentaire boulonnée pour prendre en charge les fonctionnalités de base du micro-noyau. D’autres programmeurs ont étendu Eclipse pour développer du code pour d’autres langages avec d’autres compilateurs. Beaucoup n’utilisent même pas le compilateur Java, mais ils utilisent tous les mêmes routines de base pour éditer et annoter les fichiers.
Les fonctionnalités supplémentaires qui sont superposées sont souvent appelées plug-ins. Beaucoup appellent plutôt cette approche extensible une architecture de plug-in.
Richards aime expliquer cela avec un exemple tiré du secteur des assurances : « Le traitement des réclamations est nécessairement complexe, mais les étapes réelles ne le sont pas. Ce qui le rend complexe, ce sont toutes les règles. »
La solution consiste à pousser certaines tâches de base – comme demander un nom ou vérifier le paiement – dans le micro-noyau. Les différentes unités commerciales peuvent ensuite écrire des plug-ins pour les différents types de demandes en tricotant ensemble les règles avec des appels aux fonctions de base dans le noyau.
Caveats:
-
Décider ce qui appartient au micro-noyau est souvent un art. Il devrait contenir le code qui est utilisé fréquemment.
-
Les plug-ins doivent inclure une bonne quantité de code de handshaking pour que le microkernel sache que le plug-in est installé et prêt à fonctionner.
-
Modifier le micro-noyau peut être très difficile, voire impossible, dès lors qu’un certain nombre de plug-ins en dépendent. La seule solution est de modifier aussi les plug-ins.
-
Choisir la bonne granularité pour les fonctions du noyau est difficile à faire à l’avance mais presque impossible à changer plus tard dans la partie.
Le meilleur pour :
-
Outils utilisés par une grande variété de personnes
-
Applications avec une division claire entre les routines de base et les règles d’ordre supérieur
-
Applications. avec un ensemble fixe de routines de base et un ensemble dynamique de règles qui doivent être mises à jour fréquemment
Architecture de microservices
Les logiciels peuvent être comme un bébé éléphant : Il est mignon et amusant quand il est petit, mais une fois qu’il devient grand, il est difficile à diriger et résistant au changement. L’architecture microservice est conçue pour aider les développeurs à éviter de laisser leurs bébés grandir pour devenir lourds, monolithiques et inflexibles. Au lieu de créer un seul gros programme, l’objectif est de créer un certain nombre de petits programmes différents, puis de créer un nouveau petit programme chaque fois que quelqu’un veut ajouter une nouvelle fonctionnalité. Pensez à un troupeau de cobayes.
via GIPHY
« Si vous allez sur votre iPad et que vous regardez l’interface utilisateur de Netflix, chaque élément de cette interface provient d’un service distinct, souligne Richards. La liste de vos favoris, les notes que vous attribuez aux différents films et les informations comptables sont toutes livrées en lots séparés par des services distincts. C’est comme si Netflix était une constellation de dizaines de petits sites web qui se présente comme un seul service.
Cette approche est similaire aux approches événementielle et micro-noyau, mais elle est utilisée principalement lorsque les différentes tâches sont facilement séparées. Dans de nombreux cas, les différentes tâches peuvent nécessiter des quantités différentes de traitement et peuvent varier dans leur utilisation. Les serveurs qui diffusent le contenu de Netflix sont beaucoup plus sollicités le vendredi et le samedi soir, et doivent donc être prêts à monter en charge. Les serveurs qui suivent les retours de DVD, en revanche, effectuent la majeure partie de leur travail pendant la semaine, juste après la distribution du courrier du jour par la poste. En les mettant en œuvre en tant que services distincts, le cloud de Netflix peut les faire évoluer indépendamment en fonction de l’évolution de la demande.
Caveats :
-
Les services doivent être largement indépendants, sinon l’interaction peut entraîner un déséquilibre du cloud.
-
Pas toutes les applications ont des tâches qui ne peuvent pas être facilement divisées en unités indépendantes.
-
Les performances peuvent souffrir lorsque les tâches sont réparties entre différents microservices. Les coûts de communication peuvent être importants.
-
Trop de microservices peuvent dérouter les utilisateurs car certaines parties de la page web apparaissent beaucoup plus tard que d’autres.
Le meilleur pour :
-
Les sites Web avec de petits composants
-
Les centres de données d’entreprise avec des frontières bien définies
-
Le développement rapide de nouvelles entreprises et applications Web
-
Les équipes de développement qui sont dispersées, souvent à travers le monde
Architecture spatiale
De nombreux sites Web sont construits autour d’une base de données, et ils fonctionnent bien tant que la base de données est capable de suivre la charge. Mais lorsque l’utilisation atteint des pics et que la base de données ne peut pas relever le défi constant que représente l’écriture d’un journal des transactions, le site Web tout entier tombe en panne.
L’architecture spatiale est conçue pour éviter l’effondrement fonctionnel en cas de charge élevée en répartissant à la fois le traitement et le stockage entre plusieurs serveurs. Les données sont réparties entre les nœuds, tout comme la responsabilité du service des appels. Certains architectes utilisent le terme plus amorphe d' »architecture en nuage ». Le nom « basé sur l’espace » fait référence à « l’espace des tuplets » des utilisateurs, qui est découpé pour répartir le travail entre les nœuds. « Tout est constitué d’objets en mémoire », explique Richards. « L’architecture basée sur l’espace prend en charge les choses qui ont des pics imprévisibles en éliminant la base de données. »
Le stockage des informations en RAM rend de nombreux travaux beaucoup plus rapides, et la répartition du stockage avec le traitement peut simplifier de nombreuses tâches de base. Mais l’architecture distribuée peut rendre certains types d’analyse plus complexes. Les calculs qui doivent être répartis sur l’ensemble des données – comme la recherche d’une moyenne ou la réalisation d’une analyse statistique – doivent être divisés en tâches secondaires, réparties sur tous les nœuds, puis agrégées lorsque c’est terminé.
Caveats:
-
Le support transactionnel est plus difficile avec les bases de données RAM.
-
Générer suffisamment de charge pour tester le système peut être difficile, mais les nœuds individuels peuvent être testés indépendamment.
-
Développer l’expertise pour mettre en cache les données pour la vitesse sans corrompre les copies multiples est difficile.
Le meilleur pour :
-
Les données à haut volume comme les flux de clics et les journaux d’utilisateurs
-
Les données à faible valeur qui peuvent être perdues occasionnellement sans grandes conséquences-en d’autres termes, pas les transactions bancaires
-
Les réseaux sociaux
.