Cómo Linux facilita la recuperación de datos

Recuperación de datos: El proceso de recuperación de datos de un ordenador cuando el dispositivo que los alberga es inaccesible.
Es algo con lo que ningún profesional de TI quiere tener que lidiar, especialmente dentro de un centro de datos. ¿Por qué? Porque la recuperación de datos podría significar la pérdida de datos, y las implicaciones que rodean a la pérdida de datos son muchas:
-
Pérdida de ingresos
-
Pérdida de documentación
-
Pérdida de contactos
-
Pérdida de información propietaria.
-
Pérdida de información del cliente
- Pérdida de tiempo
-
Pérdida de confianza
La lista sigue y sigue. Al final, cuando algo va mal en un sistema (virus, hardware que falla, sistema operativo corrupto o roto, etc.), depende de ti recuperar los valiosos datos guardados en esa unidad local. Puede ser en un escritorio o en un servidor, en una máquina de usuario final o en el sistema que alberga la base de datos/web/nube de tu empresa.
ES: Guía de seguridad de Kubernetes (PDF gratuito) (TechRepublic)
La verdad del asunto es que no es una cuestión de «si», sino de «cuándo» vas a acabar teniendo que recuperar los datos. Aunque la nube ha hecho que esto sea un poco menos desalentador (con la capacidad de sincronizar sus datos con servidores en la nube utilizando poco esfuerzo), no siempre se puede contar con la nube y, en algunos casos, es posible que tenga datos que no quiere que se alojen en un servidor de terceros.
Así que cuando se le encomienda la tarea de recuperar los datos, ¿a dónde acudir?
Para muchos, la respuesta es Linux.
¿Pero cómo puede un sistema operativo hacer posible la recuperación de datos de otro? Se sorprendería de lo fácil que es hacerlo. Siempre y cuando un disco duro no haya fallado catastróficamente (momento en el que tendrías que enviar esos datos a un especialista forense o aceptar la derrota), puedes recuperar esos datos sin demasiadas complicaciones.
Déjame explicarte.
Bienvenido a la distribución Live
Un área en la que Linux ha brillado durante años es la posibilidad de probar una distribución Linux antes de instalarla. Esto se hace por medio de lo que se llama una distribución Live. El funcionamiento es simple: Al arrancar una distribución Live (de las que son la mayoría de los sistemas operativos Linux modernos) verás algo parecido a lo que ofrece Ubuntu (Figura A).
Figura A
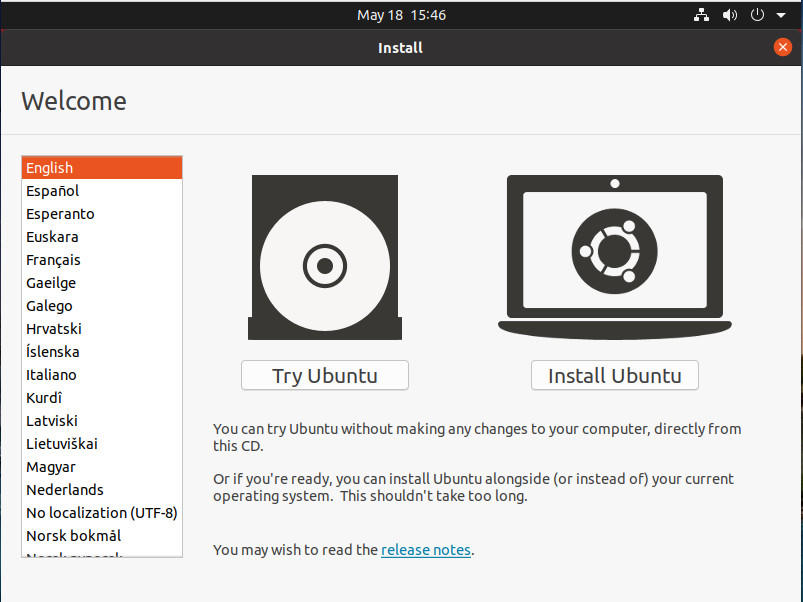
El instalador de Ubuntu Desktop Linux facilita el inicio de una instancia Live.
Al hacer clic en Probar Ubuntu, se inicia una instancia en vivo del sistema operativo. ¿Qué significa esto? Una instancia en vivo se ejecuta completamente en la memoria RAM del sistema, por lo que no se cambia nada en el disco duro de la máquina. En otras palabras, si esa máquina tiene Windows instalado en la unidad local, Windows seguirá estando ahí, sólo que no se ejecutará.
Aquí es donde las cosas se ponen muy útiles.
Las instancias en vivo le dan acceso a todas las herramientas disponibles en el sistema operativo Linux, como si estuviera instalado en la unidad. Eso significa que puedes montar directorios y copiar archivos.
¿Ves a dónde va esto? Si no es así, deja que te lo explique.
El proceso de recuperación de datos con Linux
Digamos que tienes una máquina con Windows 10 que, por el motivo que sea, ya no arranca. Has probado el disco duro y no sale nada malo, así que el problema es la placa base o el propio Windows.
Y hay datos que debes tener en esa unidad interna.
Para recuperar esos datos, graba una distribución de Linux en un pendrive (usando una herramienta como Unetbootin), inserta el pendrive en el sistema en cuestión y arranca desde el pendrive. Cuando se te pida, haz clic en Try Ubuntu (o la nomenclatura que utilice tu distribución preferida). Una vez que la instancia en vivo está en marcha, entonces debe localizar la unidad en cuestión, que se puede encontrar con el comando:
sudo sfdisk -l
Este comando imprimirá una lista de todas las unidades conectadas a la máquina (Figura B).
Figura B
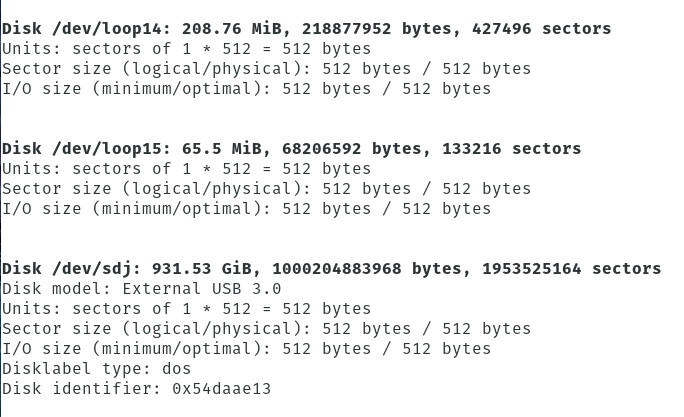
Encontrar la ubicación de la unidad que alberga los datos inaccesibles.
Como puedes ver, en Linux, las unidades se etiquetan en forma de /dev/sdX (donde X es una letra). Aquí es donde las cosas pueden ser un poco complicadas, especialmente si tienes varias unidades conectadas a la máquina que no arranca. Si sólo hay una unidad, lo más probable es que esté etiquetada como /dev/sda. Si hay más de una unidad, probablemente tendrás que tomarte el tiempo y montar todas las unidades, hasta encontrar los datos en cuestión.
Montar una unidad significa que estás montando una unidad en un directorio, para que los datos sean accesibles. Vamos a hacerlo.
Primero abre una ventana de terminal y crea un directorio temporal con el comando:
sudo mkdir /data
Con el directorio en marcha, podemos montar la unidad en él. Supongamos que la unidad es un sistema de archivos NTFS, que se encuentra en /dev/sdb. Para montar esta unidad en nuestro directorio recién creado, emitiríamos un comando como:
sudo mount -t ntfs-3g /dev/sdb1 /data -o force
¿Por qué el 1? Porque, muy probablemente, tus datos están alojados en la primera partición… a no ser que la unidad estuviera particionada de otra manera. Para esto, puede que tengas que usar un poco de prueba y error, como por ejemplo:
sudo mount -t ntfs-3g /dev/sdb /data -o force
o
sudo mount -t ntfs-3g /dev/sdb2 /data -o force
Al final, conseguirás montar la unidad de Windows, lo que significa que todos los datos que contiene se encontrarán en el directorio /data recién creado. Usted puede utilizar la línea de comandos o el administrador de archivos para navegar en ese directorio. Entonces debería ver carpetas como:
-
Documentos y configuraciones
-
Archivos de programa
-
Información sobre el volumen del sistema
-
WINDOWS
¿Qué hacer con esos datos?
Una vez que hayas localizado la carpeta que alberga tus datos de la unidad de Windows, puedes copiarlos fácilmente. Para ello, conecta otra unidad USB (dejando la que tiene la distribución Live en su sitio) y haz clic en la entrada del panel izquierdo del gestor de archivos para montar esa unidad (Figura C).
Figura C
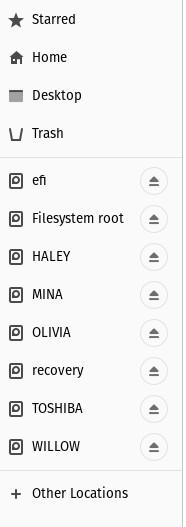
Una unidad USB en el gestor de archivos Nautilus.
Navega hasta la carpeta que alberga los datos que se van a copiar (digamos que se llama client_data) y haz clic con el botón derecho del ratón en la carpeta en cuestión. Seleccione Copiar en el menú (Figura D).
Figura D
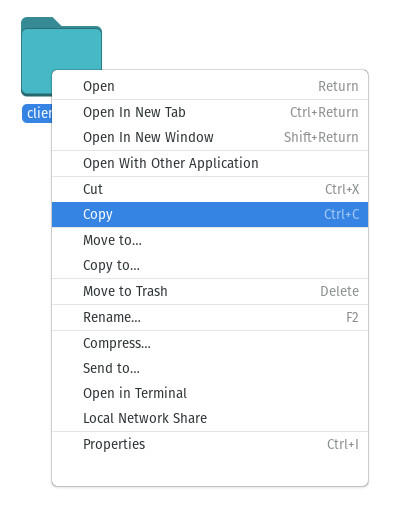
Copiando la carpeta client_data alojada en el directorio WINDOWS.
Una vez que los datos terminen de copiarse, navegue hasta la unidad USB recién conectada en el administrador de archivos, haga clic con el botón derecho en algún lugar del panel derecho y seleccione Pegar (Figura E).
Figura E
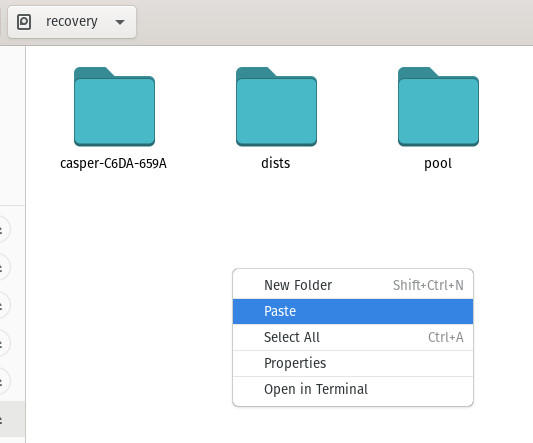
Pegar los datos de la unidad inaccesible a una unidad USB.
Cuando haya terminado de pegar los datos, puede desmontar la unidad USB que contiene los datos copiados haciendo clic en el área que apunta hacia arriba asociada a la unidad en el panel izquierdo del administrador de archivos.
Felicidades, acaba de recuperar los datos de una unidad inaccesible de Windows utilizando Linux. Copie esos datos a una máquina que funcione y ya está de nuevo en marcha.
Vea también
- Cómo convertirse en administrador de bases de datos: Una hoja de trucos (TechRepublic)
- La nube híbrida: Una guía para profesionales de TI (PDF gratuito) (descarga de TechRepublic)
- Lista de comprobación de poder: Migración del servidor de correo electrónico local a la nube (TechRepublic Premium)
- Cómo los centros de datos a hiperescala están remodelando toda la TI (ZDNet)
- Los mejores servicios en la nube para pequeñas empresas (CNET)
- DevOps: Más cobertura imprescindible (TechRepublic en Flipboard)
