Como o Linux torna a recuperação de dados fácil

Recuperação de dados: O processo de recuperação de dados de um computador quando o alojamento do dispositivo de recuperação de dados está inacessível.
É algo com que nenhum profissional de TI quer ter de lidar, especialmente dentro de um centro de dados. Porquê? Porque a recuperação de dados pode significar perda de dados, e as implicações em torno da perda de dados são muitas:
- p>p>Perda de receitas
- p>Perda de documentação /li>>>p>p>Perda de contactos
- p>p>Perda de informação proprietária
- p>Informação do cliente perdido
- p>P>Tempo perdido /li>>p>P>Perda de confiança
A lista não pára. No final, quando algo corre mal com um sistema (vírus, falha de hardware, sistema operativo corrupto ou quebrado, etc.), cabe-lhe a si recuperar os preciosos dados guardados naquela unidade local. Estes podem estar numa área de trabalho ou num servidor, numa máquina de utilizadores finais, ou no sistema que alberga a base de dados/web/cloud da sua empresa.
VER: Kubernetes security guide (PDF gratuito) (TechRepublic)
A verdade é que, não é uma questão de “se”, mas de “quando” vai acabar por ter de recuperar os dados. Embora a nuvem tenha tornado isto um pouco menos assustador (com a capacidade de sincronizar os seus dados com os servidores da nuvem usando pouco esforço), nem sempre pode contar com a nuvem e, em alguns casos, pode ter dados que não quer que sejam alojados num servidor de terceiros.
Então, quando está encarregado de recuperar dados, para onde se dirige?
Para muitos, a resposta é Linux.
Mas como pode um sistema operativo tornar a recuperação de dados de outro mesmo possível? Ficaria surpreendido com a facilidade com que isto pode ser feito. Desde que um disco rígido não tenha falhado catastroficamente (altura em que estaria a enviar esses dados a um especialista forense ou a aceitar a derrota), é possível recuperar esses dados sem demasiados incómodos.
Deixem-me explicar.
Bem-vindo à distribuição Live
Uma área onde o Linux tem brilhado durante anos é a capacidade de testar uma distribuição Linux antes de ser instalada. Isto é feito através do que se chama uma distribuição Live. Como isto funciona é simples: Quando se inicia uma distribuição Live (da qual a maioria dos sistemas operativos Linux modernos são) verá algo semelhante ao que o Ubuntu oferece (Figura A).
Figure A
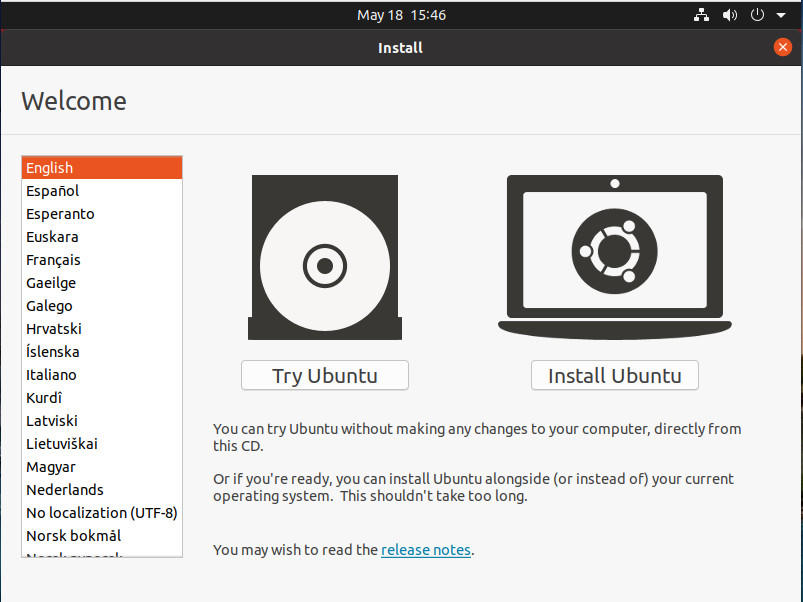
O instalador do Ubuntu Desktop Linux facilita o arranque de uma instância Live.
p> Ao clicar em Try Ubuntu, lança-se uma instância ao vivo do sistema operativo. O que é que isto significa? Uma instância ao vivo corre completamente na RAM do sistema, por isso nada mudou no disco rígido da máquina. Por outras palavras, se essa máquina tiver o Windows instalado no disco local, o Windows continuará lá, só que não está a funcionar.
É aqui que as coisas se tornam muito úteis.
Instâncias em directo dão-lhe acesso a todas as ferramentas disponíveis no sistema operativo Linux, como se estivesse instalado na unidade de disco. Isso significa que pode montar directórios e copiar ficheiros.
Ver para onde isto vai? Se não, deixe-me explicar.
O processo de recuperação de dados usando Linux
Vejamos que tem uma máquina Windows 10 que, por qualquer razão, já não arranca. Já testou o disco rígido e nada está a correr mal, por isso o problema é a placa mãe ou o próprio Windows.
E há dados que deve ter nesse disco interno.
Para recuperar esses dados, queima-se uma distribuição Linux numa unidade flash (utilizando uma ferramenta como Unetbootin), insere-se a unidade flash no sistema em questão, e inicializa-se a partir da unidade flash. Quando solicitado, clique em Try Ubuntu (ou qualquer nomenclatura que a sua distribuição de escolha utilize). Assim que a instância ao vivo estiver a funcionar, deve então localizar a drive em questão, que pode ser encontrada com o comando:
sudo sfdisk -l
Este comando irá imprimir uma lista de todas as unidades anexadas à máquina (Figura B).
Figure B
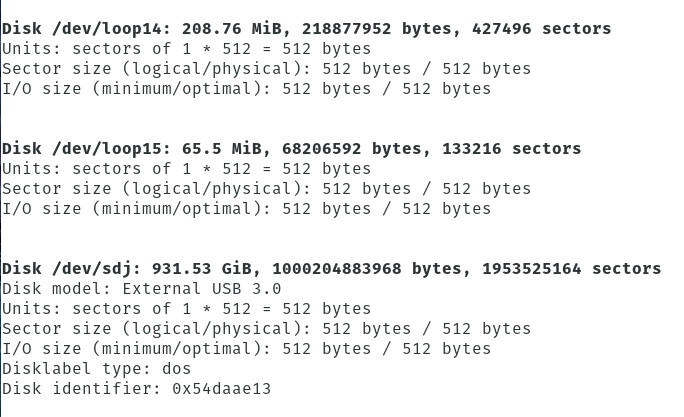
encontrar a localização da unidade que alberga os dados inacessíveis.
Como pode ver, no Linux, as unidades são etiquetadas sob a forma de /dev/sdX (onde X é uma letra). É aqui que as coisas podem ficar um pouco complicadas, especialmente se tiver várias unidades ligadas à máquina não inicializável. Se houver apenas uma unidade, as hipóteses são boas de ser etiquetada /dev/sda. Se houver mais do que uma unidade, provavelmente terá de levar o tempo e montar todas as unidades, até encontrar os dados em questão.
Montar uma unidade significa que está a montar uma unidade num directório, para que os dados estejam acessíveis. Vamos fazer isso.
Abra primeiro uma janela de terminal e cria um directório temporário com o comando:
sudo mkdir /data
Com o directório no lugar, podemos montar a unidade no directório. Vamos assumir que a unidade é um sistema de ficheiros NTFS, encontrado em /dev/sdb. Para montar esta unidade no nosso directório recentemente criado, emitiríamos um comando como:
sudo mount -t ntfs-3g /dev/sdb1 /data -o force
Porquê o 1? Porque, muito provavelmente, os seus dados estão alojados na primeira partição – a não ser que a unidade tenha sido particionada de forma diferente. Para isso, poderá ter de usar um pouco de tentativa e erro, como por exemplo:
sudo mount -t ntfs-3g /dev/sdb /data -o force
ou
sudo mount -t ntfs-3g /dev/sdb2 /data -o force
Eventualmente, conseguirá montar a unidade Windows, o que significa que todos os dados que contêm serão encontrados no directório /dados recém-criado. Pode utilizar a linha de comando ou o gestor de ficheiros para navegar para esse directório. Deverá então ver pastas tais como:
- p>Documentos e Configurações
- p>Arquivos de Programas
- p>p>Informação de Volume do Sistema
li>>p>WINDOWS
O que fazer com esses dados?
Após ter localizado a pasta que contém os seus dados a partir da unidade do Windows, pode facilmente copiá-la. Para o fazer, ligue outra unidade USB (deixando a que tem a distribuição Live no local) e clique na entrada no painel esquerdo do gestor de ficheiros para montar essa unidade (Figura C).
Figure C
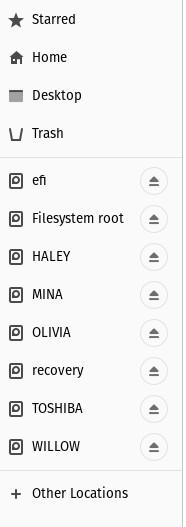
uma unidade USB no gestor de ficheiros Nautilus.
Navigate to the folder housing the data to be copied (say it’s named client_data) and rightclick the folder in question. Seleccione Copiar no menu (Figura D).
Figure D
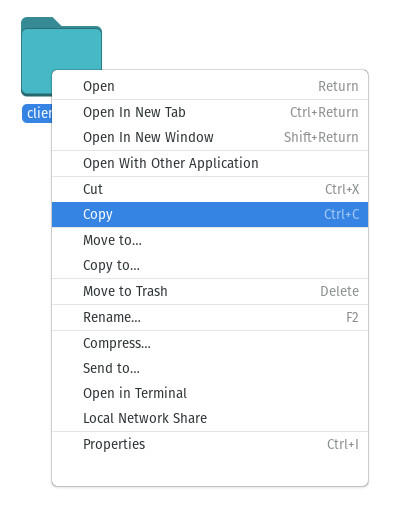
Copying the client_data folder housed in the WINDOWS directory.
Após a conclusão da cópia dos dados, navegar para a unidade USB recentemente anexada no gestor de ficheiros, clicar com o botão direito do rato algures no painel direito, e seleccionar Colar (Figura E).
Figure E
colar os dados da unidade inacessível para uma unidade USB.
Quando a colagem de dados tiver terminado, pode então desmontar a unidade USB que contém os dados copiados clicando na área de apontamento para cima associada à unidade no painel esquerdo do gestor de ficheiros.
Felicidades, acaba de recuperar dados de uma unidade Windows inacessível usando Linux. Copie esses dados para uma máquina de trabalho e está de novo a funcionar.
Também ver
- Como tornar-se um administrador de bases de dados: Uma folha de fraude (TechRepublic)
- Hybrid cloud: Um guia para profissionais de TI (PDF gratuito) (TechRepublic download)
- Lista de verificação de poder: Migração local de servidor para nuvem de correio electrónico (TechRepublic Premium)
- Como os centros de dados de hiper-escala estão a remodelar todas as TI (ZDNet)
- Os melhores serviços de nuvem para pequenas empresas (CNET)
- DevOps: Mais cobertura de leitura obrigatória (TechRepublic on Flipboard)
