Apache Spark: Resilient Distributed Datasets
RDDs representam tanto a ideia de como um grande conjunto de dados é representado na Centelha Apache como a abstracção para trabalhar com ela. Esta secção irá cobrir a primeira, e as secções seguintes irão cobrir a segunda. De acordo com o artigo seminal sobre a Spark, “os RDD são estruturas de dados imutáveis, tolerantes a falhas e paralelas que permitem aos utilizadores persistir explicitamente resultados intermédios na memória, controlar a sua partição para optimizar a colocação de dados, e manipulá-los utilizando um rico conjunto de operadores”. Vamos dissecar esta descrição para compreender verdadeiramente as ideias por detrás do conceito de RDD.
Immutable
RDD são concebidos para serem imutáveis, o que significa que não se pode modificar especificamente uma linha em particular no conjunto de dados representado por esse RDD. Pode chamar uma das operações RDD disponíveis para manipular as linhas no RDD da forma que desejar, mas essa operação irá devolver um novo RDD. A RDD básica permanecerá inalterada, e a nova RDD conterá os dados da forma como os alterou. A imutabilidade exige que um RDD transporte a sua informação de linhagem que a Spark aproveita para fornecer eficientemente capacidades de tolerância a falhas.
 Apache Spark architecture
Apache Spark architecture
br>>>>h2>Fault-Tolerant
A capacidade de processar múltiplos conjuntos de dados em paralelo requer normalmente um cluster de máquinas para hospedar e executar lógica computacional. Se uma ou mais dessas máquinas morrer ou se tornar extremamente lenta devido a circunstâncias inesperadas, então como é que isso irá afectar o processamento global dos dados desses conjuntos de dados? A boa notícia é que a Spark trata automaticamente do tratamento da falha em nome dos seus utilizadores, reconstruindo a parte falhada utilizando a informação da linhagem.
Estruturas de Dados Paralelas
Imagine o caso de utilização em que alguém lhe dá um grande ficheiro de registo com 1TB de tamanho e é-lhe pedido que descubra quantas declarações de registo contêm a palavra “excepção” no mesmo. Uma solução lenta seria iterar através desse ficheiro de registo do início ao fim e executar a lógica de determinar se uma determinada declaração de registo contém a palavra “excepção”. Uma solução mais rápida seria dividir esse ficheiro de 1TB em vários pedaços e executar a lógica acima referida em cada pedaço de forma paralela para acelerar o tempo total de processamento. Cada pedaço contém uma colecção de filas. A recolha de linhas é essencialmente a estrutura de dados que contém um conjunto de linhas e proporciona a capacidade de iterar através de cada linha. Cada pedaço contém uma colecção de filas, e todos os pedaços estão a ser processados em paralelo. É de onde vem a frase estruturas de dados paralelas.
In-Memory Computing
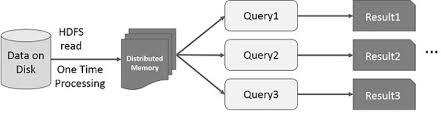
A ideia de acelerar o cálculo de grandes conjuntos de dados que residem em discos de forma paralela utilizando um conjunto de máquinas foi introduzida por um papel MapReduce2 do Google. Esta ideia foi implementada e está disponível no projecto de código aberto Hadoop. Construindo sobre essa base sólida, o RDD empurra o limite de velocidade introduzindo a capacidade de fazer cálculos in-memory distribuídos.
É sempre fascinante examinar as histórias que conduziram à criação de uma ideia inovadora. No mundo dos grandes processamentos de dados, uma vez que se consegue extrair insights de grandes conjuntos de dados de uma forma fiável utilizando um conjunto de técnicas rudimentares, pretende-se utilizar técnicas mais sofisticadas para reduzir o tempo necessário para o fazer. É aqui que o cálculo in-memory distribuído ajuda.
A técnica sofisticada a que me refiro está a utilizar a aprendizagem mecânica para realizar várias previsões ou para extrair padrões de grandes conjuntos de dados. Os algoritmos de aprendizagem de máquinas são iterativos por natureza, o que significa que precisam de passar por muitas iterações para chegar a um estado óptimo. É aqui que o cálculo distribuído na memória pode ajudar a reduzir o tempo de conclusão de dias para horas. Outro caso de utilização que pode beneficiar enormemente do cálculo in-memory distribuído é a extracção interactiva de dados, onde múltiplas consultas ad hoc são realizadas no mesmo subconjunto de dados. Se esse subconjunto de dados persistir na memória, essas consultas levarão segundos e não minutos a completar.