Os 5 melhores padrões da arquitectura de software: Como fazer a escolha certa
Quantos enredos existem nos filmes de Hollywood? Alguns críticos dizem que existem apenas cinco. Quantas formas se pode estruturar um programa? Neste momento, a maioria dos programas usa uma das cinco arquitecturas.
Mark Richards é um arquitecto de software baseado em Boston que tem pensado há mais de 30 anos sobre como os dados devem fluir através do software. O seu novo livro (gratuito), Software Architecture Patterns, centra-se em cinco arquitecturas que são comummente utilizadas para organizar sistemas de software. A melhor maneira de planear novos programas é estudá-los e compreender os seus pontos fortes e fracos.
Neste artigo, destilei as cinco arquitecturas numa referência rápida dos pontos fortes e fracos, bem como em casos de utilização óptima. Lembre-se que pode utilizar múltiplos padrões num único sistema para optimizar cada secção de código com a melhor arquitectura. Apesar de lhe chamarem informática, é muitas vezes uma arte.
Arquitectura em camadas (n-tier)
Esta abordagem é provavelmente a mais comum porque é normalmente construída em torno da base de dados, e muitas aplicações nos negócios prestam-se naturalmente ao armazenamento de informação em tabelas.
Esta é uma espécie de profecia auto-realizável. Muitas das maiores e melhores estruturas de software – como Java EE, Drupal, e Express – foram construídas com esta estrutura em mente, pelo que muitas das aplicações construídas com elas saem naturalmente numa arquitectura em camadas.
O código é organizado de modo a que os dados entrem na camada superior e trabalhem para baixo em cada camada até chegarem à camada inferior, que é normalmente uma base de dados. Pelo caminho, cada camada tem uma tarefa específica, como verificar a consistência dos dados ou reformatar os valores para os manter consistentes. É comum que diferentes programadores trabalhem independentemente em diferentes camadas.
Crédito de imagem: Izhaki
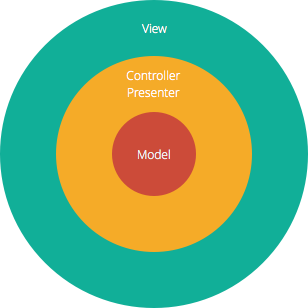
A estrutura Model-View-Controller (MVC), que é a abordagem padrão de desenvolvimento de software oferecida pela maioria das estruturas populares da web, é claramente uma arquitectura em camadas. Logo acima da base de dados está a camada do modelo, que frequentemente contém lógica empresarial e informação sobre os tipos de dados na base de dados. No topo está a camada de visualização, que é frequentemente CSS, JavaScript, e HTML com código dinâmico incorporado. No meio, está o controlador, que tem várias regras e métodos para transformar os dados em movimento entre a vista e o modelo.
A vantagem de uma arquitectura em camadas é a separação das preocupações, o que significa que cada camada pode concentrar-se unicamente no seu papel. Isto faz com que assim seja:
- p>p>Mantainable
- p>Testable>/li>
- p>P>Fácil atribuir “papéis”/li>
- p>P>Fácil actualizar e melhorar as camadas separadamente
Atéreas por camadas terão camadas isoladas que não são afectadas por certas alterações noutras camadas, permitindo uma refactoring mais fácil. Esta arquitectura pode também conter camadas abertas adicionais, como uma camada de serviço, que pode ser utilizada para aceder a serviços partilhados apenas na camada empresarial, mas também ser contornada para velocidade.
Licalizar as tarefas e definir camadas separadas é o maior desafio para o arquitecto. Quando os requisitos se ajustam bem ao padrão, as camadas serão fáceis de separar e atribuir a diferentes programadores.
Cavernas:
- p>código fonte pode transformar-se numa “grande bola de lama” se não estiver organizada e os módulos não tiverem papéis ou relações claras.
-
p>código pode acabar lentamente graças ao que alguns programadores chamam de “anti-padrão de buraco de lama”. Muito do código pode ser dedicado à passagem de dados através de camadas sem utilizar qualquer lógica.
-
Solamento de camadas, que é um objectivo importante para a arquitectura, também pode tornar difícil a compreensão da arquitectura sem compreender cada módulo.
- p>coders podem saltar as camadas passadas para criar um acoplamento apertado e produzir uma confusão lógica cheia de interdependências complexas.
- p>A implantação monolítica é muitas vezes inevitável, o que significa que pequenas alterações podem exigir uma redistribuição completa da aplicação.
Best for:
- p>Novas aplicações que precisam de ser construídas rapidamente
- p>p>Aplicações empresariais que precisam de espelhar os departamentos e processos tradicionais de TI
- p> Equipas com criadores inexperientes que ainda não compreendem outras arquitecturas
- p>Aplicações que requerem normas rigorosas de manutenção e testabilidade
Event-arquitectura conduzida
Muitos programas passam a maior parte do seu tempo à espera que algo aconteça. Isto é especialmente verdade para computadores que trabalham directamente com humanos, mas também é comum em áreas como as redes. Por vezes há dados que necessitam de processamento, e outras vezes não.
A arquitectura conduzida por eventos ajuda a gerir isto construindo uma unidade central que aceita todos os dados e depois os delega nos módulos separados que tratam do tipo particular. Diz-se que esta entrega gera um “evento”, e é delegada no código atribuído a esse tipo.
Programar uma página web com JavaScript implica escrever os pequenos módulos que reagem a eventos como cliques do rato ou toques no teclado. O próprio navegador orquestra todas as entradas e assegura-se de que apenas o código certo vê os eventos certos. Muitos tipos diferentes de eventos são comuns no browser, mas os módulos interagem apenas com os eventos que lhes dizem respeito. Isto é muito diferente da arquitectura em camadas, onde todos os dados passam normalmente por todas as camadas. Em geral, arquitecturas orientadas por eventos:
-
são facilmente adaptáveis a ambientes complexos, muitas vezes caóticos
- p>p>escala facilmente/li>>li>>p>p> são facilmente extensíveis quando aparecem novos tipos de eventos
Cavernas:
- p>p>p>Teste pode ser complexo se os módulos se puderem afectar uns aos outros. Enquanto os módulos individuais podem ser testados independentemente, as interacções entre eles só podem ser testadas num sistema plenamente funcional.
-
p> Manipulação de erros pode ser difícil de estruturar, especialmente quando vários módulos têm de manipular os mesmos eventos.
-
Quando os módulos falham, a unidade central tem de ter um plano de reserva.
- p>Mensagem aérea pode abrandar a velocidade de processamento, especialmente quando a unidade central tem de guardar as mensagens que chegam em rajadas.
- p>>Desenvolver uma estrutura de dados de todo o sistema para eventos pode ser complexo quando os eventos têm necessidades muito diferentes.
- p>A manutenção de um mecanismo baseado em transacções para a consistência é difícil porque os módulos são tão desacoplados e independentes.
Best for:
- p> Sistemas assíncronos com fluxo de dados assíncronos
- p>Aplicações em que os blocos de dados individuais interagem apenas com alguns dos muitos módulos
- p>Utilizador interfaces
Arquitectura do microkernel
Muitas aplicações têm um conjunto central de operações que são usadas repetidamente em diferentes padrões que dependem dos dados e da tarefa em mãos. A popular ferramenta de desenvolvimento Eclipse, por exemplo, abrirá ficheiros, anotá-los-á, editá-los-á, e iniciará processadores de fundo. A ferramenta é famosa por fazer todos estes trabalhos com código Java e depois, quando um botão é premido, compilar o código e executá-lo.
Neste caso, as rotinas básicas para exibir um ficheiro e editá-lo fazem parte do microkernel. O compilador Java é apenas uma parte extra que é aparafusada para suportar as características básicas no microkernel. Outros programadores estenderam o Eclipse para desenvolver código para outras linguagens com outros compiladores. Muitos nem sequer utilizam o compilador Java, mas todos eles utilizam as mesmas rotinas básicas para editar e anotar ficheiros.
As características extra que estão estratificadas no topo são muitas vezes chamadas plug-ins. Muitos chamam a esta abordagem extensível uma arquitectura plug-in em vez.
Richards gosta de explicar isto com um exemplo do negócio dos seguros: “O processamento de reclamações é necessariamente complexo, mas os passos reais não o são. O que o torna complexo são todas as regras”
A solução é empurrar algumas tarefas básicas como pedir um nome ou verificar o pagamento – para o microkernel. As diferentes unidades de negócio podem então escrever plug-ins para os diferentes tipos de reivindicações, tricotando as regras com chamadas às funções básicas no núcleo.
Cavernas:
- p> Decidir o que pertence ao micro núcleo é muitas vezes uma arte. Deve conter o código que é usado frequentemente.
-
Os plug-ins devem incluir uma quantidade razoável de código de aperto de mão para que o microkernel esteja ciente de que o plug-in está instalado e pronto a funcionar.
- p>Modificar o microkernel pode ser muito difícil ou mesmo impossível, uma vez que um número de plug-ins depende dele. A única solução é modificar também os plug-ins.
-
Escolher a granularidade certa para as funções do núcleo é difícil de fazer antecipadamente mas quase impossível de alterar mais tarde no jogo.
Best for:
- p> Ferramentas utilizadas por uma grande variedade de pessoas
- p>p>Aplicações com uma divisão clara entre rotinas básicas e regras de ordem superior
- p>p>Aplicações com um conjunto fixo de rotinas nucleares e um conjunto dinâmico de regras que devem ser actualizadas com frequência
Arquitectura de microsserviços
Software pode ser como um elefante bebé: É giro e divertido quando é pequeno, mas quando fica grande, é difícil de dirigir e resistente à mudança. A arquitectura de microserviços foi concebida para ajudar os criadores a evitar que os seus bebés cresçam e se tornem pesados, monolíticos, e inflexíveis. Em vez de construir um grande programa, o objectivo é criar uma série de diferentes programas minúsculos e depois criar um novo pequeno programa sempre que alguém quiser acrescentar uma nova funcionalidade. Pense numa manada de cobaias.
via GIPHY
“Se for para o seu iPad e olhar para a IU da Netflix, cada coisa nessa interface vem de um serviço separado”, aponta Richards. A lista dos seus favoritos, as classificações que dá aos filmes individuais, e as informações contabilísticas são todas entregues em lotes separados por serviços separados. É como se o Netflix fosse uma constelação de dezenas de websites mais pequenos que por acaso se apresentam apenas como um serviço.
Esta abordagem é semelhante às abordagens por eventos e microkernel, mas é utilizada principalmente quando as diferentes tarefas são facilmente separadas. Em muitos casos, tarefas diferentes podem exigir quantidades diferentes de processamento e podem variar na sua utilização. Os servidores que entregam o conteúdo da Netflix são empurrados com muito mais força nas noites de sexta e sábado, pelo que devem estar prontos para aumentar a escala. Por outro lado, os servidores que acompanham as devoluções de DVD fazem a maior parte do seu trabalho durante a semana, logo após os correios entregarem o correio do dia. Ao implementá-los como serviços separados, a nuvem Netflix pode escalá-los para cima e para baixo independentemente, à medida que a procura muda.
Cavernas:
- p> Os serviços devem ser amplamente independentes ou então a interacção pode fazer com que a nuvem se torne desequilibrada.
- p>Nem todas as aplicações têm tarefas que não podem ser facilmente divididas em unidades independentes.
- p>p>O desempenho pode sofrer quando as tarefas são repartidas entre diferentes micro-serviços. Os custos de comunicação podem ser significativos.
-
Muitos micro-serviços podem confundir os utilizadores, uma vez que partes da página web aparecem muito mais tarde do que outras.
Best for:
- p>p>Websites com pequenos componentes
- p>p>Centros de dados corporativos com fronteiras bem definidas/li>
- p>p>Desenvolvendo rapidamente novos negócios e aplicações web
- p>p> Equipas de desenvolvimento que se encontram dispersas, frequentemente em todo o mundo
Arquitectura baseada no espaço
Muitos websites são construídos em torno de uma base de dados, e funcionam bem desde que a base de dados seja capaz de acompanhar a carga. Mas quando os picos de utilização, e a base de dados não consegue acompanhar o constante desafio de escrever um registo das transacções, todo o website falha.
A arquitectura baseada no espaço é concebida para evitar o colapso funcional sob carga elevada, dividindo tanto o processamento como o armazenamento entre múltiplos servidores. Os dados estão espalhados pelos nós, tal como a responsabilidade pela manutenção das chamadas. Alguns arquitectos usam o termo mais amorfo “arquitectura de nuvem”. O nome “baseado no espaço” refere-se ao “espaço tuple” dos utilizadores, que é cortado para dividir o trabalho entre os nós. “É tudo objectos in-memory”, diz Richards. “A arquitectura baseada no espaço suporta coisas que têm picos imprevisíveis, eliminando a base de dados”
Armazenar a informação na RAM torna muitos trabalhos muito mais rápidos, e espalhar o armazenamento com o processamento pode simplificar muitas tarefas básicas. Mas a arquitectura distribuída pode tornar alguns tipos de análise mais complexos. Cálculos que devem ser distribuídos por todo o conjunto de dados – como encontrar uma média ou fazer uma análise estatística – devem ser divididos em subjobs, espalhados por todos os nós, e depois agregados quando é feito.
Cavernas:
-
O suporte transacional é mais difícil com bases de dados RAM.
- p>Gerar carga suficiente para testar o sistema pode ser um desafio, mas os nós individuais podem ser testados independentemente.
- p>p>Desenvolver a perícia para guardar os dados para velocidade sem corromper múltiplas cópias é difícil.
Best for:
- p> dados de alto volume como fluxos de cliques e registos de utilizadores
- p> dados de baixo valor que podem ser perdidos ocasionalmente sem grandes consequências – por outras palavras, não transacções bancárias/li>
- p>p> redes sociais