5 najlepszych wzorców architektury oprogramowania: Jak dokonać właściwego wyboru
Ile fabuł jest w hollywoodzkich filmach? Niektórzy krytycy twierdzą, że jest ich tylko pięć. Na ile sposobów można zbudować program? W tej chwili większość programów używa jednej z pięciu architektur.
Mark Richards jest architektem oprogramowania z Bostonu, który od ponad 30 lat myśli o tym, jak dane powinny przepływać przez oprogramowanie. Jego nowa (darmowa) książka, Software Architecture Patterns, koncentruje się na pięciu architekturach, które są powszechnie używane do organizowania systemów oprogramowania. Najlepszym sposobem na zaplanowanie nowych programów jest ich przestudiowanie i zrozumienie ich mocnych i słabych stron.
W tym artykule przedstawiłem pięć architektur w formie krótkiego opisu mocnych i słabych stron, a także optymalnych przypadków użycia. Pamiętaj, że możesz używać wielu wzorców w jednym systemie, aby zoptymalizować każdą sekcję kodu z najlepszą architekturą. Nawet jeśli nazywają to informatyką, to często jest to sztuka.
Architektura warstwowa (n-tier)
To podejście jest prawdopodobnie najbardziej powszechne, ponieważ jest zwykle zbudowane wokół bazy danych, a wiele aplikacji biznesowych w naturalny sposób nadaje się do przechowywania informacji w tabelach.
Jest to coś w rodzaju samospełniającej się przepowiedni. Wiele z największych i najlepszych frameworków – jak Java EE, Drupal i Express – zostało zbudowanych z myślą o tej strukturze, więc wiele aplikacji zbudowanych przy ich użyciu naturalnie ma architekturę warstwową.
Kod jest ułożony tak, że dane wchodzą do górnej warstwy i schodzą w dół każdej warstwy, aż dotrą do dolnej, którą zazwyczaj jest baza danych. Po drodze, każda warstwa ma określone zadanie, takie jak sprawdzenie spójności danych lub przeformatowanie wartości, aby zachować ich spójność. Często zdarza się, że różni programiści pracują niezależnie nad różnymi warstwami.
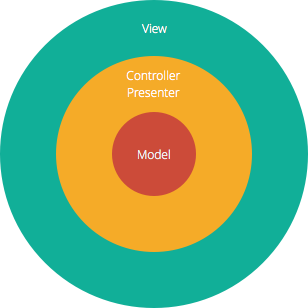
Image credit: Izhaki
Struktura Model-Widok-Kontroler (MVC), która jest standardowym podejściem do tworzenia oprogramowania oferowanym przez większość popularnych frameworków internetowych, jest wyraźnie architekturą warstwową. Tuż nad bazą danych znajduje się warstwa modelu, która często zawiera logikę biznesową oraz informacje o typach danych w bazie. Na górze znajduje się warstwa widoku, która często jest CSS, JavaScript i HTML z dynamicznie osadzonym kodem. W środku masz kontroler, który posiada różne reguły i metody do przekształcania danych poruszających się pomiędzy widokiem a modelem.
Zaletą architektury warstwowej jest separacja obaw, co oznacza, że każda warstwa może skupić się wyłącznie na swojej roli. Dzięki temu:
-
Maintainable
-
Testable
-
Łatwe przypisywanie oddzielnych „ról”
-
Łatwe aktualizowanie i ulepszanie warstw oddzielnie
Prawidłowe architektury warstwowe będą miały izolowane warstwy, na które nie mają wpływu pewne zmiany w innych warstwach, co pozwala na łatwiejszy refaktoring. Architektura ta może również zawierać dodatkowe otwarte warstwy, takie jak warstwa usług, które mogą być używane do dostępu do usług współdzielonych tylko w warstwie biznesowej, ale również mogą być pomijane ze względu na szybkość.
Podzielenie zadań i zdefiniowanie oddzielnych warstw jest największym wyzwaniem dla architekta. Jeśli wymagania dobrze pasują do wzorca, warstwy będą łatwe do rozdzielenia i przypisania różnym programistom.
Caveats:
-
Kod źródłowy może zamienić się w „wielką kulę błota”, jeśli jest niezorganizowany, a moduły nie mają jasnych ról i relacji.
-
Kod może skończyć się powolny dzięki temu, co niektórzy programiści nazywają „anty-wzorcem zapadania się”. Duża część kodu może być poświęcona na przekazywanie danych przez warstwy bez użycia jakiejkolwiek logiki.
-
Izolacja warstw, która jest ważnym celem architektury, może również utrudnić zrozumienie architektury bez zrozumienia każdego modułu.
-
Koderzy mogą pominąć warstwy, aby stworzyć ścisłe sprzężenie i wyprodukować logiczny bałagan pełen złożonych współzależności.
-
Monolityczne wdrożenie jest często nieuniknione, co oznacza, że małe zmiany mogą wymagać całkowitego ponownego wdrożenia aplikacji.
Najlepsze dla:
-
Nowych aplikacji, które muszą być zbudowane szybko
-
Aplikacji korporacyjnych lub biznesowych, które muszą odzwierciedlać tradycyjne działy i procesy IT
-
Zespołów z niedoświadczonymi programistami, którzy nie rozumieją jeszcze innych architektur
-
Aplikacje wymagające ścisłych standardów utrzymywalności i testowalności
Event-architektura sterowana wydarzeniami
Wiele programów spędza większość czasu czekając, aż coś się wydarzy. Jest to szczególnie prawdziwe w przypadku komputerów, które pracują bezpośrednio z ludźmi, ale jest to również powszechne w obszarach takich jak sieci. Czasami są dane, które wymagają przetwarzania, a innym razem ich nie ma.
Architektura sterowana zdarzeniami pomaga zarządzać tym poprzez zbudowanie jednostki centralnej, która przyjmuje wszystkie dane, a następnie deleguje je do oddzielnych modułów, które obsługują dany typ. To przekazanie danych jest określane jako wygenerowanie „zdarzenia” i jest ono przekazywane do kodu przypisanego do danego typu.
Programowanie strony internetowej za pomocą JavaScriptu polega na pisaniu małych modułów, które reagują na zdarzenia takie jak kliknięcia myszą lub naciśnięcia klawiszy. Przeglądarka sama zarządza wszystkimi danymi wejściowymi i upewnia się, że tylko właściwy kod widzi właściwe zdarzenia. Wiele różnych typów zdarzeń jest powszechnych w przeglądarce, ale moduły wchodzą w interakcję tylko z tymi zdarzeniami, które ich dotyczą. Jest to bardzo odmienne od architektury warstwowej, w której wszystkie dane będą zazwyczaj przechodzić przez wszystkie warstwy. Ogólnie rzecz biorąc, architektury sterowane zdarzeniami:
-
Łatwo dostosowują się do złożonych, często chaotycznych środowisk
-
Łatwo skalują się
-
Łatwo rozszerzają się, gdy pojawiają się nowe typy zdarzeń
Zagrożenia:
-
Testowanie może być skomplikowane, jeśli moduły mogą wpływać na siebie nawzajem. Podczas gdy poszczególne moduły mogą być testowane niezależnie, interakcje między nimi mogą być testowane tylko w pełni działającym systemie.
-
Obsługa błędów może być trudna do ustrukturyzowania, szczególnie gdy kilka modułów musi obsługiwać te same zdarzenia.
-
Gdy moduły zawiodą, jednostka centralna musi mieć plan awaryjny.
-
Nadmiar komunikatów może spowolnić szybkość przetwarzania, zwłaszcza gdy jednostka centralna musi buforować komunikaty, które przychodzą w seriach.
-
Opracowanie ogólnosystemowej struktury danych dla zdarzeń może być skomplikowane, gdy zdarzenia mają bardzo różne potrzeby.
-
Utrzymanie mechanizmu spójności opartego na transakcjach jest trudne, ponieważ moduły są tak rozłączne i niezależne.
Najlepsze dla:
-
Systemów z asynchronicznym przepływem danych
-
Aplikacji, w których poszczególne bloki danych wchodzą w interakcje tylko z kilkoma z wielu modułów
-
Użytkowników interfejsy użytkownika
Architektura mikrokernela
Wiele aplikacji posiada podstawowy zestaw operacji, które są wielokrotnie wykorzystywane w różnych wzorcach, zależnych od danych i zadania. Popularne narzędzie programistyczne Eclipse, na przykład, otwiera pliki, dodaje do nich adnotacje, edytuje je i uruchamia procesory działające w tle. Narzędzie to jest znane z tego, że wszystkie te zadania wykonuje za pomocą kodu Java, a następnie, po naciśnięciu przycisku, kompiluje kod i uruchamia go.
W tym przypadku podstawowe procedury wyświetlania pliku i jego edycji są częścią mikrokernela. Kompilator Javy jest tylko dodatkową częścią, która jest przykręcona, by wspierać podstawowe funkcje w mikrokernelu. Inni programiści rozszerzyli Eclipse, by tworzyć kod dla innych języków z innymi kompilatorami. Wielu z nich nie korzysta nawet z kompilatora Javy, ale wszyscy używają tych samych podstawowych procedur do edycji i dodawania adnotacji do plików.
Dodatkowe funkcje, które są nakładane na wierzch, są często nazywane wtyczkami. Wielu nazywa to rozszerzalne podejście architekturą wtyczek.
Richards lubi wyjaśniać to na przykładzie z branży ubezpieczeniowej: „Przetwarzanie roszczeń jest z konieczności skomplikowane, ale same kroki nie są. To, co czyni je złożonym, to wszystkie reguły.”
Rozwiązanie polega na przepchnięciu kilku podstawowych zadań, takich jak zapytanie o nazwisko lub sprawdzenie płatności, do mikrokernela. Różne jednostki biznesowe mogą następnie pisać wtyczki dla różnych typów roszczeń, łącząc reguły z wywołaniami podstawowych funkcji w jądrze.
Zastrzeżenia:
-
Decydowanie, co należy do mikrokernela, jest często sztuką. Powinien on zawierać kod, który jest często używany.
-
Wtyczki muszą zawierać sporą ilość kodu obsługi, aby mikrokernel wiedział, że wtyczka jest zainstalowana i gotowa do pracy.
-
Modyfikacja mikrokernela może być bardzo trudna lub wręcz niemożliwa, gdy zależy od niego wiele pluginów. Jedynym rozwiązaniem jest modyfikacja samych pluginów.
-
Wybór odpowiedniej ziarnistości funkcji jądra jest trudny do wykonania z wyprzedzeniem, ale prawie niemożliwy do zmiany w późniejszej fazie gry.
Najlepsze dla:
-
Narzędzi używanych przez wielu różnych ludzi
-
Aplikacji z wyraźnym podziałem na podstawowe rutyny i reguły wyższego rzędu
-
Aplikacji. z ustalonym zestawem podstawowych procedur i dynamicznym zestawem reguł, które muszą być często aktualizowane
Architektura mikroserwisów
Oprogramowanie może być jak małe słoniątko: Jest uroczy i zabawny, gdy jest mały, ale gdy już stanie się duży, jest trudny do kierowania i odporny na zmiany. Architektura mikroserwisów ma na celu pomóc programistom uniknąć sytuacji, w której ich dzieci wyrosną na nieporęczne, monolityczne i nieelastyczne. Zamiast budować jeden duży program, celem jest stworzenie wielu różnych małych programów, a następnie tworzenie nowego małego programu za każdym razem, gdy ktoś chce dodać nową funkcję. Pomyśl o stadzie królików doświadczalnych.
via GIPHY
„Jeśli wejdziesz na iPada i spojrzysz na interfejs Netflixa, każda pojedyncza rzecz w tym interfejsie pochodzi z oddzielnej usługi” – zauważa Richards. Lista ulubionych filmów, oceny, które wystawiasz poszczególnym filmom, oraz informacje księgowe są dostarczane w osobnych partiach przez osobne serwisy. To tak, jakby Netflix był konstelacją dziesiątek mniejszych stron internetowych, które tak się składa, że prezentują się jako jedna usługa.
To podejście jest podobne do podejścia event-driven i microkernel, ale jest stosowane głównie wtedy, gdy różne zadania można łatwo rozdzielić. W wielu przypadkach różne zadania mogą wymagać różnych ilości przetwarzania i mogą się różnić w użyciu. Serwery dostarczające treści Netflixa są znacznie mocniej obciążane w piątkowe i sobotnie wieczory, więc muszą być gotowe do skalowania. Z kolei serwery śledzące zwroty DVD wykonują większość swojej pracy w ciągu tygodnia, zaraz po tym, jak poczta dostarczy pocztę z całego dnia. Dzięki wdrożeniu ich jako oddzielnych usług, chmura Netflixa może je niezależnie skalować w górę i w dół w miarę zmian popytu.
Caveats:
-
Usługi muszą być w dużej mierze niezależne, w przeciwnym razie interakcje mogą spowodować, że chmura stanie się niezrównoważona.
-
Nie wszystkie aplikacje mają zadania, których nie można łatwo podzielić na niezależne jednostki.
-
Wydajność może ucierpieć, gdy zadania są rozproszone pomiędzy różne mikroserwisy. Koszty komunikacji mogą być znaczące.
-
Zbyt wiele mikroserwisów może dezorientować użytkowników, ponieważ części strony internetowej pojawiają się znacznie później niż inne.
Najlepsze dla:
-
Stron internetowych z małymi komponentami
-
Korporacyjnych centrów danych z dobrze zdefiniowanymi granicami
-
Szybko rozwijających się nowych firm i aplikacji internetowych
-
Zespołów programistów, które są rozproszone, często na całym świecie
Architektura oparta na przestrzeni
Wiele stron internetowych jest zbudowanych wokół bazy danych, i funkcjonują one dobrze tak długo, jak długo baza danych jest w stanie nadążyć z obciążeniem. Ale kiedy obciążenie wzrasta, a baza danych nie jest w stanie sprostać ciągłym wyzwaniom związanym z zapisywaniem dziennika transakcji, cała witryna ulega awarii.
Architektura oparta na przestrzeni została zaprojektowana w celu uniknięcia załamania funkcjonalnego przy dużym obciążeniu poprzez rozdzielenie zarówno przetwarzania, jak i przechowywania danych pomiędzy wiele serwerów. Dane są rozproszone po węzłach, tak jak odpowiedzialność za obsługę połączeń. Niektórzy architekci używają bardziej amorficznego terminu „architektura chmury”. Nazwa „space-based” odnosi się do „przestrzeni tuple” użytkowników, która jest pocięta w celu podzielenia pracy pomiędzy węzły. „To wszystko są obiekty in-memory”, mówi Richards. „Architektura oparta na przestrzeni wspiera rzeczy, które mają nieprzewidywalne skoki poprzez wyeliminowanie bazy danych.”
Przechowywanie informacji w pamięci RAM sprawia, że wiele zadań jest znacznie szybszych, a rozłożenie pamięci masowej z przetwarzaniem może uprościć wiele podstawowych zadań. Jednak rozproszona architektura może sprawić, że niektóre typy analiz staną się bardziej złożone. Obliczenia, które muszą być rozłożone na cały zbiór danych – jak znalezienie średniej lub wykonanie analizy statystycznej – muszą być podzielone na pod-zadania, rozłożone na wszystkie węzły, a następnie zagregowane po ich zakończeniu.
Caveats:
-
Obsługa transakcji jest trudniejsza w przypadku baz danych RAM.
-
Generowanie obciążenia wystarczającego do przetestowania systemu może być wyzwaniem, ale poszczególne węzły mogą być testowane niezależnie.
-
Opracowanie ekspertyzy pozwalającej na buforowanie danych w celu zwiększenia prędkości bez uszkadzania wielu kopii jest trudne.
Najlepsze dla:
-
Danych o dużej objętości, takich jak strumienie kliknięć i logi użytkowników
-
Danych o niskiej wartości, które mogą zostać utracone sporadycznie bez większych konsekwencji – innymi słowy, nie transakcji bankowych
-
Sieci społecznościowych