Comment Linux facilite la récupération des données

Récupération des données : Le processus de récupération des données d’un ordinateur lorsque le périphérique hébergeant lesdites données est inaccessible.
C’est quelque chose qu’aucun professionnel de l’informatique ne veut jamais avoir à gérer, surtout au sein d’un centre de données. Pourquoi ? Parce que la récupération des données pourrait signifier une perte de données, et les implications entourant la perte de données sont nombreuses :
-
Perte de revenus
-
Perte de documentation
-
Perte de contacts
-
Perte d’informations propriétaires.
-
Perte d’informations sur les clients
- Perte de temps
-
Perte de confiance
La liste est longue. Au final, lorsque quelque chose ne va pas avec un système (virus, matériel défaillant, système d’exploitation corrompu ou cassé, etc.), c’est à vous de récupérer les précieuses données enregistrées sur ce disque local. Cela peut être sur un ordinateur de bureau ou un serveur, une machine d’utilisateur final ou le système hébergeant la base de données/web/cloud de votre entreprise.
ETRE : Guide de sécurité de Kubernetes (PDF gratuit) (TechRepublic)
La vérité est que ce n’est pas une question de » si « , mais de » quand » vous allez vous retrouver à devoir récupérer des données. Bien que le cloud ait rendu cette tâche un peu moins décourageante (avec la possibilité de synchroniser vos données sur des serveurs cloud en déployant peu d’efforts), vous ne pouvez pas toujours compter sur le cloud et, dans certains cas, vous pourriez avoir des données que vous ne voulez pas héberger sur un serveur tiers.
Alors, lorsque vous êtes chargé de récupérer des données, vers qui vous tourner ?
Pour beaucoup, la réponse est Linux.
Mais comment un système d’exploitation peut-il rendre la récupération des données d’un autre même possible ? Vous seriez surpris de la facilité avec laquelle cela peut être fait. Tant qu’un disque dur n’est pas tombé en panne de manière catastrophique (à ce moment-là, vous devriez soit envoyer ces données à un spécialiste de la médecine légale, soit accepter la défaite), vous pouvez récupérer ces données sans trop de tracas.
Laissez-moi vous expliquer.
Bienvenue à la distribution Live
Un domaine où Linux brille depuis des années est la possibilité de tester une distribution Linux avant qu’elle ne soit installée. Cela se fait par le biais de ce que l’on appelle une distribution Live. Le fonctionnement est simple : Lorsque vous démarrez une distribution Live (dont la plupart des systèmes d’exploitation Linux modernes sont), vous verrez quelque chose de semblable à ce que propose Ubuntu (Figure A).
Figure A
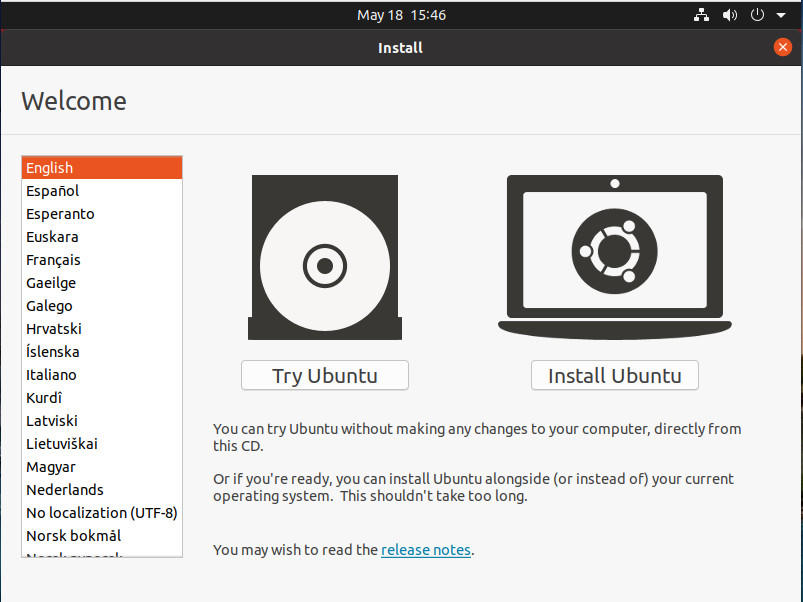
Le programme d’installation de Ubuntu Desktop Linux permet de démarrer facilement une instance Live.
En cliquant sur Try Ubuntu, vous lancez une instance live du système d’exploitation. Qu’est-ce que cela signifie ? Une instance live s’exécute entièrement dans la RAM du système, donc rien n’est modifié sur le disque dur de la machine. En d’autres termes, si cette machine a Windows installé sur le disque local, Windows sera toujours là, mais ne fonctionnera pas.
C’est là que les choses deviennent très utiles.
Les instances vivantes vous donnent accès à tous les outils disponibles sur le système d’exploitation Linux, comme s’il était installé sur le lecteur. Cela signifie que vous pouvez monter des répertoires et copier des fichiers.
Vous voyez où je veux en venir ? Si non, laissez-moi vous expliquer.
Le processus de récupération des données à l’aide de Linux
Disons que vous avez une machine Windows 10 qui, pour une raison quelconque, ne démarre plus. Vous avez testé le disque dur et rien ne se présente de travers, le problème vient donc de la carte mère ou de Windows lui-même.
Et il y a des données que vous devez avoir sur ce disque interne.
Pour récupérer ces données, vous gravez une distribution Linux sur un lecteur flash (en utilisant un outil comme Unetbootin), vous insérez le lecteur flash dans le système en question et vous démarrez à partir du lecteur flash. Lorsque vous y êtes invité, cliquez sur Essayer Ubuntu (ou toute autre nomenclature utilisée par la distribution de votre choix). Une fois que l’instance live est en marche, vous devez ensuite localiser le lecteur en question, ce qui peut être trouvé avec la commande :
sudo sfdisk -l
Cette commande imprimera une liste de tous les lecteurs attachés à la machine (Figure B).
Figure B

Trouver l’emplacement du lecteur abritant les données inaccessibles.
Comme vous pouvez le voir, sous Linux, les lecteurs sont étiquetés sous la forme /dev/sdX (où X est une lettre). C’est là que les choses peuvent devenir un peu délicates, surtout si vous avez plusieurs lecteurs attachés à la machine non amorçable. S’il n’y a qu’un seul disque, il y a de fortes chances qu’il soit étiqueté /dev/sda. S’il y a plus d’un lecteur, vous devrez probablement prendre le temps de monter tous les lecteurs, jusqu’à ce que vous trouviez les données en question.
Monter un lecteur signifie que vous montez un lecteur dans un répertoire, afin que les données soient accessibles. Faisons cela.
D’abord, ouvrez une fenêtre de terminal et créez un répertoire temporaire avec la commande :
sudo mkdir /data
Avec le répertoire en place, nous pouvons y monter le lecteur. Supposons que le lecteur soit un système de fichiers NTFS, trouvé sur /dev/sdb. Pour monter ce lecteur sur notre répertoire nouvellement créé, nous émettrions une commande comme :
sudo mount -t ntfs-3g /dev/sdb1 /data -o force
Pourquoi le 1 ? Parce que, très probablement, vos données sont hébergées sur la première partition – à moins que le disque n’ait été partitionné différemment. Pour cela, vous pourriez avoir à utiliser un peu d’essai et d’erreur, comme :
sudo mount -t ntfs-3g /dev/sdb /data -o force
ou
sudo mount -t ntfs-3g /dev/sdb2 /data -o force
Éventuellement, vous réussirez à monter le lecteur Windows, ce qui signifie que toutes les données qui le contiennent se trouveront dans le répertoire /data nouvellement créé. Vous pouvez soit utiliser la ligne de commande, soit le gestionnaire de fichiers pour naviguer dans ce répertoire. Vous devriez alors voir des dossiers tels que :
-
Documents et paramètres
-
Fichiers de programmes
-
Informations sur le volume du système
-
WINDOWS
Que faire de ces données ?
Une fois que vous avez localisé le dossier hébergeant vos données sur le disque Windows, vous pouvez facilement les copier. Pour ce faire, branchez une autre clé USB (en laissant en place celle contenant la distribution Live) et cliquez sur l’entrée dans le volet gauche du gestionnaire de fichiers pour monter ce lecteur (Figure C).
Figure C
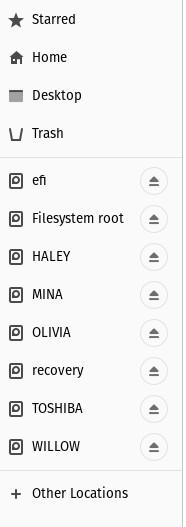
Un lecteur USB dans le gestionnaire de fichiers Nautilus.
Naviguez jusqu’au dossier abritant les données à copier (disons qu’il s’appelle client_data) et faites un clic droit sur le dossier en question. Sélectionnez Copier dans le menu (figure D).
Figure D
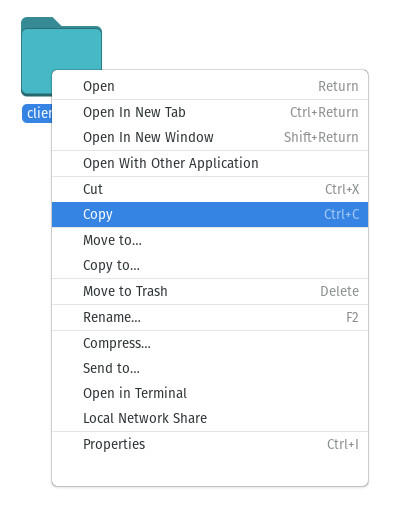
Copier le dossier client_data logé dans le répertoire WINDOWS.
Une fois que les données ont fini d’être copiées, naviguez jusqu’au lecteur USB nouvellement connecté dans le gestionnaire de fichiers, cliquez avec le bouton droit quelque part dans le volet de droite et sélectionnez Coller (Figure E).
Figure E
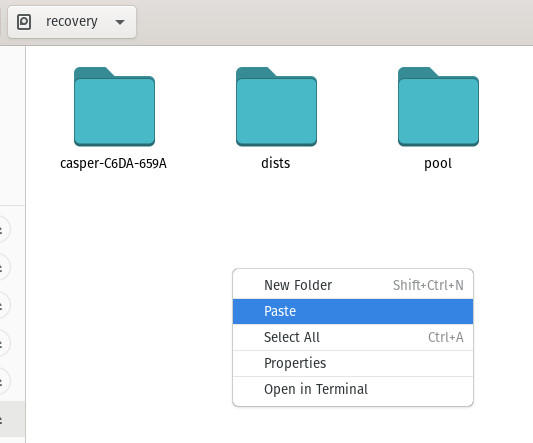
Coller les données du lecteur inaccessible sur un lecteur USB.
Lorsque le collage des données est terminé, vous pouvez alors démonter le lecteur USB contenant les données copiées en cliquant sur la zone pointant vers le haut associée au lecteur dans le volet gauche du gestionnaire de fichiers.
Félicitations, vous venez de récupérer les données d’un lecteur Windows inaccessible à l’aide de Linux. Copiez ces données sur une machine de travail et vous êtes de nouveau opérationnel.
Voir aussi
- Comment devenir un administrateur de base de données : Une antisèche (TechRepublic)
- Le cloud hybride : Un guide pour les pros de l’informatique (PDF gratuit) (téléchargement TechRepublic)
- La liste de contrôle du pouvoir : Migration d’un serveur de messagerie local vers le cloud (TechRepublic Premium)
- Comment les centres de données hyperscale remodèlent toute l’informatique (ZDNet)
- Meilleurs services cloud pour les petites entreprises (CNET)
- DevOps : Plus de couverture incontournable (TechRepublic sur Flipboard)
